add cyfi445 labs
18
CYFI445/lectures/00_configuration/installcommands.txt
Normal file
@@ -0,0 +1,18 @@
|
||||
pip install ipywidgets
|
||||
pip install scikit-learn
|
||||
pip install ultralytics
|
||||
pip install ultralytics opencv-python
|
||||
pip install transformers
|
||||
pip install ipykernel
|
||||
# pip install sentencepiece did not work
|
||||
conda install sentencepiece
|
||||
|
||||
|
||||
For AI Agents
|
||||
- Create a different envirofment: python version 3.11
|
||||
- installl pytorch
|
||||
- pip install browser-use
|
||||
- pip install "browser-use[memory]"
|
||||
- playwright install chromium --with-deps --no-shell
|
||||
|
||||
|
||||
{kind=link}
|
After Width: | Height: | Size: 221 KiB |
{kind=link}
|
After Width: | Height: | Size: 47 KiB |
329
CYFI445/lectures/04_linear_regression_Pytorch/0_oop.ipynb
Normal file
@@ -0,0 +1,329 @@
|
||||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# Python Object-Oriented Programming (OOP) Tutorial\n",
|
||||
"\n",
|
||||
"This tutorial introduces Object-Oriented Programming (OOP) in Python for beginners. We'll cover classes, objects, attributes, methods, and inheritance with simple examples."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## 1. What is OOP?\n",
|
||||
"OOP is a programming paradigm that organizes code into **objects**, which are instances of **classes**. A class is like a blueprint, and an object is a specific instance created from that blueprint."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## 2. Creating a Class and Object\n",
|
||||
"\n",
|
||||
"Let's create a simple `Dog` class to represent a dog with a name and age."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"Buddy\n",
|
||||
"3\n",
|
||||
"Buddy says Woof!\n",
|
||||
"Luna\n",
|
||||
"Luna says Woof!\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"# Define the Dog class\n",
|
||||
"class Dog:\n",
|
||||
" # Constructor method to initialize attributes\n",
|
||||
" def __init__(self, name, age):\n",
|
||||
" self.name = name # Instance attribute\n",
|
||||
" self.age = age # Instance attribute\n",
|
||||
"\n",
|
||||
" # Method to make the dog bark\n",
|
||||
" def bark(self):\n",
|
||||
" return f\"{self.name} says Woof!\"\n",
|
||||
"\n",
|
||||
"# Create objects (instances) of the Dog class\n",
|
||||
"dog1 = Dog(\"Buddy\", 3)\n",
|
||||
"dog2 = Dog(\"Luna\", 5)\n",
|
||||
"\n",
|
||||
"# Access attributes and call methods\n",
|
||||
"print(dog1.name) # Output: Buddy\n",
|
||||
"print(dog1.age) # Output: 3\n",
|
||||
"print(dog1.bark()) # Output: Buddy says Woof!\n",
|
||||
"print(dog2.name) # Output: Luna\n",
|
||||
"print(dog2.bark()) # Output: Luna says Woof!"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Explanation:\n",
|
||||
"- `class Dog:` defines the class.\n",
|
||||
"- `__init__` is the constructor, called when an object is created. It sets the object's initial attributes (`name` and `age`).\n",
|
||||
"- `self` refers to the instance of the class.\n",
|
||||
"- `bark` is a method that returns a string.\n",
|
||||
"- `dog1` and `dog2` are objects created from the `Dog` class."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## 3. Class Attributes\n",
|
||||
"Class attributes are shared by all instances of a class. Let's add a class attribute to track the species."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"Canis familiaris\n",
|
||||
"Canis familiaris\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"class Dog:\n",
|
||||
" # Class attribute\n",
|
||||
" species = \"Canis familiaris\"\n",
|
||||
"\n",
|
||||
" def __init__(self, name, age):\n",
|
||||
" self.name = name\n",
|
||||
" self.age = age\n",
|
||||
"\n",
|
||||
" def bark(self):\n",
|
||||
" return f\"{self.name} says Woof!\"\n",
|
||||
"\n",
|
||||
"dog1 = Dog(\"Buddy\", 3)\n",
|
||||
"print(dog1.species) # Output: Canis familiaris\n",
|
||||
"print(Dog.species) # Output: Canis familiaris"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Explanation:\n",
|
||||
"- `species` is a class attribute, shared by all `Dog` objects.\n",
|
||||
"- You can access it via the class (`Dog.species`) or an instance (`dog1.species`)."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## 4. Inheritance\n",
|
||||
"Inheritance allows a class to inherit attributes and methods from another class. Let's create a `Puppy` class that inherits from `Dog`."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"Max says Yip!\n",
|
||||
"Max is playing!\n",
|
||||
"Canis familiaris\n",
|
||||
"True\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"class Dog:\n",
|
||||
" species = \"Canis familiaris\"\n",
|
||||
"\n",
|
||||
" def __init__(self, name, age):\n",
|
||||
" self.name = name\n",
|
||||
" self.age = age\n",
|
||||
"\n",
|
||||
" def bark(self):\n",
|
||||
" return f\"{self.name} says Woof!\"\n",
|
||||
"\n",
|
||||
"# Puppy inherits from Dog\n",
|
||||
"class Puppy(Dog):\n",
|
||||
" def __init__(self, name, age, is_cute):\n",
|
||||
" # Call the parent class's __init__\n",
|
||||
" super().__init__(name, age)\n",
|
||||
" self.is_cute = is_cute\n",
|
||||
"\n",
|
||||
" # Override the bark method\n",
|
||||
" def bark(self):\n",
|
||||
" return f\"{self.name} says Yip!\"\n",
|
||||
"\n",
|
||||
" # New method specific to Puppy\n",
|
||||
" def play(self):\n",
|
||||
" return f\"{self.name} is playing!\"\n",
|
||||
"\n",
|
||||
"puppy1 = Puppy(\"Max\", 1, True)\n",
|
||||
"print(puppy1.bark()) # Output: Max says Yip!\n",
|
||||
"print(puppy1.play()) # Output: Max is playing!\n",
|
||||
"print(puppy1.species) # Output: Canis familiaris\n",
|
||||
"print(puppy1.is_cute) # Output: True"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Explanation:\n",
|
||||
"- `Puppy` inherits from `Dog` using `class Puppy(Dog)`.\n",
|
||||
"- `super().__init__(name, age)` calls the parent class's constructor.\n",
|
||||
"- The `bark` method is overridden in `Puppy` to say \"Yip!\" instead of \"Woof!\".\n",
|
||||
"- `play` is a new method unique to `Puppy`."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## 5. Practice Exercise\n",
|
||||
"Create a `Student` class with:\n",
|
||||
"- Instance attributes: `name` and `grade`.\n",
|
||||
"- A class attribute: `school = \"High School\"`.\n",
|
||||
"- A method `study` that returns `\"[name] is studying!\"`.\n",
|
||||
"- Create a `Freshman` class that inherits from `Student` and adds a method `welcome` that returns `\"[name] is a new freshman!\"`."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"Alice is studying!\n",
|
||||
"Bob is studying!\n",
|
||||
"Bob is a new freshman!\n",
|
||||
"High School\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"class Student:\n",
|
||||
" school = \"High School\"\n",
|
||||
"\n",
|
||||
" def __init__(self, name, grade):\n",
|
||||
" self.name = name\n",
|
||||
" self.grade = grade\n",
|
||||
"\n",
|
||||
" def study(self):\n",
|
||||
" return f\"{self.name} is studying!\"\n",
|
||||
"\n",
|
||||
"class Freshman(Student):\n",
|
||||
" def welcome(self):\n",
|
||||
" return f\"{self.name} is a new freshman!\"\n",
|
||||
"\n",
|
||||
"# Test the classes\n",
|
||||
"student1 = Student(\"Alice\", 10)\n",
|
||||
"freshman1 = Freshman(\"Bob\", 9)\n",
|
||||
"print(student1.study()) # Output: Alice is studying!\n",
|
||||
"print(freshman1.study()) # Output: Bob is studying!\n",
|
||||
"print(freshman1.welcome()) # Output: Bob is a new freshman!\n",
|
||||
"print(freshman1.school) # Output: High School"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## 6. Reuse class in a package\n",
|
||||
"- Often we need to reuse a class developed by other programmer"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"Alice is studying!\n",
|
||||
"High School\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"import ub\n",
|
||||
"student = ub.Student(\"Alice\", 10)\n",
|
||||
"print(student.study()) # Output: Alice is studying!\n",
|
||||
"print(student.school) # Output: High School"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## 7. Key OOP Concepts\n",
|
||||
"- **Encapsulation**: Bundling data (attributes) and methods into a class.\n",
|
||||
"- **Inheritance**: Allowing a class to inherit from another class.\n",
|
||||
"- **Polymorphism**: Allowing different classes to be treated as instances of the same class (e.g., `Puppy` and `Dog` both have `bark` but behave differently).\n",
|
||||
"- **Abstraction**: Hiding complex details and showing only necessary features (not covered in this basic tutorial)."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## 8. Next Steps\n",
|
||||
"- Experiment with more complex classes and methods.\n",
|
||||
"- Learn about private attributes (using `_` or `__` prefixes).\n",
|
||||
"- Explore abstract base classes and polymorphism in Python.\n",
|
||||
"\n",
|
||||
"This tutorial provides a foundation for understanding OOP in Python. Practice by creating your own classes and experimenting with inheritance!"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": []
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.13.2"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 4
|
||||
}
|
||||
@@ -0,0 +1,279 @@
|
||||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "c0fc8d3e",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Step 1: Implment linear regression: replace the gradient function with autograd\n",
|
||||
"\n",
|
||||
"- Recall key steps for training\n",
|
||||
" - Forward model (1) = compute prediction with model\n",
|
||||
" - Forward model (2) = Compute loss\n",
|
||||
" - Backward = compute gradients\n",
|
||||
" - Update weights \n",
|
||||
"\n",
|
||||
"- replace np array with pytorch tensor \n",
|
||||
"- replace gradient function with `loss.backward()` "
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 61,
|
||||
"id": "016485d6",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"epoch 1: w = 25.779, loss = 5939.33496094\n",
|
||||
"epoch 2: w = 22.191, loss = 4291.27685547\n",
|
||||
"epoch 3: w = 19.141, loss = 3100.55566406\n",
|
||||
"epoch 4: w = 16.549, loss = 2240.25878906\n",
|
||||
"epoch 5: w = 14.346, loss = 1618.69470215\n",
|
||||
"epoch 6: w = 12.473, loss = 1169.61450195\n",
|
||||
"epoch 7: w = 10.881, loss = 845.15423584\n",
|
||||
"epoch 8: w = 9.528, loss = 610.73156738\n",
|
||||
"epoch 9: w = 8.378, loss = 441.36120605\n",
|
||||
"epoch 10: w = 7.400, loss = 318.99108887\n",
|
||||
"epoch 11: w = 6.569, loss = 230.57872009\n",
|
||||
"epoch 12: w = 5.863, loss = 166.70083618\n",
|
||||
"epoch 13: w = 5.262, loss = 120.54901886\n",
|
||||
"epoch 14: w = 4.752, loss = 87.20434570\n",
|
||||
"epoch 15: w = 4.318, loss = 63.11280441\n",
|
||||
"epoch 16: w = 3.949, loss = 45.70667267\n",
|
||||
"epoch 17: w = 3.636, loss = 33.13073730\n",
|
||||
"epoch 18: w = 3.370, loss = 24.04463005\n",
|
||||
"epoch 19: w = 3.143, loss = 17.47991371\n",
|
||||
"epoch 20: w = 2.951, loss = 12.73690891\n",
|
||||
"Prediction after training: f(6) = 17.704\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"import numpy as np\n",
|
||||
"import matplotlib.pyplot as plt\n",
|
||||
"import torch\n",
|
||||
"\n",
|
||||
"def forward(w, x):\n",
|
||||
" return w * x\n",
|
||||
"\n",
|
||||
"# MSE as the loss function\n",
|
||||
"def loss(y, y_pred):\n",
|
||||
" return ((y_pred - y)**2).mean()\n",
|
||||
"\n",
|
||||
"# don't need this any more as we use autograd\n",
|
||||
"# MSE = j = 1/N * (w*x - y)**2\n",
|
||||
"# dJ/dw = 2/N (w*x - y)*x\n",
|
||||
"\"\"\"\n",
|
||||
"def gradient(x, y, y_pred):\n",
|
||||
" return np.mean(2*x*(y_pred - y))\n",
|
||||
"\"\"\"\n",
|
||||
"\n",
|
||||
"# Train function\n",
|
||||
"def train(learning_rate, n_iters, w, X, Y):\n",
|
||||
" # Convert inputs to PyTorch tensors\n",
|
||||
" w = torch.tensor(w, dtype=torch.float32, requires_grad=True)\n",
|
||||
"\n",
|
||||
" for epoch in range(n_iters):\n",
|
||||
" y_pred = forward(w, X) # Forward pass\n",
|
||||
" l = loss(Y, y_pred) # Loss\n",
|
||||
" \n",
|
||||
" # Backward pass, compute autograde\n",
|
||||
" l.backward() \n",
|
||||
"\n",
|
||||
" # Update weights\n",
|
||||
" with torch.no_grad():\n",
|
||||
" w.data -= learning_rate * w.grad\n",
|
||||
" \n",
|
||||
" w.grad.zero_() # Reset gradients\n",
|
||||
" \n",
|
||||
" # Print using .item() for scalars to avoid NumPy conversion\n",
|
||||
" print(f'epoch {epoch+1}: w = {w.item():.3f}, loss = {l.item():.8f}')\n",
|
||||
" \n",
|
||||
" print(f'Prediction after training: f(6) = {forward(w.item(), 6):.3f}')\n",
|
||||
" \n",
|
||||
" \n",
|
||||
"# Define the data, make sure to use torch tensor, not np.array\n",
|
||||
"X = torch.tensor([1.0, 2.0, 3, 4], dtype=torch.float32)\n",
|
||||
"Y = torch.tensor([2.3, 3.4, 6.5, 6.8], dtype=torch.float32)\n",
|
||||
"\n",
|
||||
"# Configration\n",
|
||||
"learning_rate = 0.01\n",
|
||||
"n_iters = 20\n",
|
||||
"w_init = 30\n",
|
||||
"train(learning_rate, n_iters, w_init, X, Y)\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "58726271",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Step 2: Implment linear regression: replace the update weights (gradient descent) with an optimizor\n",
|
||||
"- replace loss function with built-in loss function `loss = nn.MSELoss()`\n",
|
||||
"- Update weights with ` optimizer.step()`"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 62,
|
||||
"id": "712d00f9",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"epoch 1: w = 0.900, b = 0.874, loss = 5.15727806\n",
|
||||
"epoch 2: w = 1.001, b = 0.907, loss = 3.69042563\n",
|
||||
"epoch 3: w = 1.084, b = 0.934, loss = 2.67253804\n",
|
||||
"epoch 4: w = 1.154, b = 0.956, loss = 1.96617866\n",
|
||||
"epoch 5: w = 1.212, b = 0.974, loss = 1.47598338\n",
|
||||
"epoch 6: w = 1.260, b = 0.989, loss = 1.13578010\n",
|
||||
"epoch 7: w = 1.301, b = 1.001, loss = 0.89965343\n",
|
||||
"epoch 8: w = 1.335, b = 1.011, loss = 0.73574245\n",
|
||||
"epoch 9: w = 1.363, b = 1.019, loss = 0.62194228\n",
|
||||
"epoch 10: w = 1.387, b = 1.025, loss = 0.54291308\n",
|
||||
"epoch 11: w = 1.406, b = 1.031, loss = 0.48801088\n",
|
||||
"epoch 12: w = 1.423, b = 1.035, loss = 0.44985026\n",
|
||||
"epoch 13: w = 1.437, b = 1.038, loss = 0.42330658\n",
|
||||
"epoch 14: w = 1.448, b = 1.040, loss = 0.40482411\n",
|
||||
"epoch 15: w = 1.458, b = 1.042, loss = 0.39193565\n",
|
||||
"epoch 16: w = 1.466, b = 1.043, loss = 0.38292903\n",
|
||||
"epoch 17: w = 1.473, b = 1.044, loss = 0.37661636\n",
|
||||
"epoch 18: w = 1.479, b = 1.045, loss = 0.37217349\n",
|
||||
"epoch 19: w = 1.484, b = 1.045, loss = 0.36902806\n",
|
||||
"epoch 20: w = 1.488, b = 1.045, loss = 0.36678365\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"import numpy as np\n",
|
||||
"import matplotlib.pyplot as plt\n",
|
||||
"import torch\n",
|
||||
"import torch.nn as nn\n",
|
||||
"\n",
|
||||
"# replace this with a Linear Model\n",
|
||||
"\"\"\"\n",
|
||||
"def forward(w, x):\n",
|
||||
" return w * x\n",
|
||||
"\"\"\"\n",
|
||||
"\n",
|
||||
"# don't need this any more as we use autograd\n",
|
||||
"# MSE as the loss function\n",
|
||||
"\"\"\"\n",
|
||||
"def loss(y, y_pred):\n",
|
||||
" return ((y_pred - y)**2).mean()\n",
|
||||
"\"\"\"\n",
|
||||
"\n",
|
||||
"# don't need this any more as we use autograd\n",
|
||||
"# MSE = j = 1/N * (w*x - y)**2\n",
|
||||
"# dJ/dw = 2/N (w*x - y)*x\n",
|
||||
"\"\"\"\n",
|
||||
"def gradient(x, y, y_pred):\n",
|
||||
" return np.mean(2*x*(y_pred - y))\n",
|
||||
"\"\"\"\n",
|
||||
"\n",
|
||||
"# Train function\n",
|
||||
"def train(n_iters, X, Y):\n",
|
||||
" for epoch in range(n_iters):\n",
|
||||
" y_pred = model(X) # Forward pass\n",
|
||||
" l = loss(Y, y_pred) # Loss\n",
|
||||
" \n",
|
||||
" # Backward pass, compute autograde (directioin of change for each parameter)\n",
|
||||
" l.backward() \n",
|
||||
"\n",
|
||||
" # Update weights\n",
|
||||
" optimizer.step()\n",
|
||||
" \n",
|
||||
" optimizer.zero_grad() # Reset gradients\n",
|
||||
" \n",
|
||||
" # Print using .item() for scalars to avoid NumPy conversion\n",
|
||||
" # Print w and b\n",
|
||||
" w = model.weight.item() # Scalar value of weight\n",
|
||||
" b = model.bias.item() # Scalar value of bias\n",
|
||||
" print(f'epoch {epoch+1}: w = {w:.3f}, b = {b:.3f}, loss = {l.item():.8f}')\n",
|
||||
" \n",
|
||||
"# Define the data, make sure to use torch tensor, not np.array\n",
|
||||
"X = torch.tensor([1.0, 2.0, 3, 4], dtype=torch.float32)\n",
|
||||
"X = X.reshape(4, 1)\n",
|
||||
"Y = torch.tensor([2.3, 3.4, 6.5, 6.8], dtype=torch.float32)\n",
|
||||
"Y = Y.reshape(4, 1)\n",
|
||||
"\n",
|
||||
"n_samples, n_features = X.shape \n",
|
||||
"\n",
|
||||
"# Linear model f = wx + b\n",
|
||||
"input_size = n_features\n",
|
||||
"output_size = 1\n",
|
||||
"model = nn.Linear(input_size, output_size)\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"# Loss and optimizer\n",
|
||||
"learning_rate = 0.01\n",
|
||||
"criterion = nn.MSELoss()\n",
|
||||
"\n",
|
||||
"# Stochastic Gradient Descent (SGD)\n",
|
||||
"optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate) \n",
|
||||
"\n",
|
||||
"\n",
|
||||
"n_iters = 20\n",
|
||||
"\n",
|
||||
"train(n_iters, X, Y)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "09623107",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"Prediction for x = 6: 9.973\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"# Test the model with x = 6\n",
|
||||
"# predicted = model(X).detach().numpy()\n",
|
||||
"test_input = torch.tensor([[6.0]], dtype=torch.float32) # Shape: (1, 1)\n",
|
||||
"with torch.no_grad(): # Disable gradient tracking for inference\n",
|
||||
" y_pred = model(test_input)\n",
|
||||
"print(f'Prediction for x = 6: {y_pred.item():.3f}')"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "44ad547f",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": []
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.13.2"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 5
|
||||
}
|
||||
9
CYFI445/lectures/04_linear_regression_Pytorch/ub.py
Normal file
@@ -0,0 +1,9 @@
|
||||
class Student:
|
||||
school = "High School"
|
||||
|
||||
def __init__(self, name, grade):
|
||||
self.name = name
|
||||
self.grade = grade
|
||||
|
||||
def study(self):
|
||||
return f"{self.name} is studying!"
|
||||
{kind=link}
|
After Width: | Height: | Size: 29 KiB |
{kind=link}
|
After Width: | Height: | Size: 30 KiB |
{kind=link}
|
After Width: | Height: | Size: 29 KiB |
{kind=link}
|
After Width: | Height: | Size: 45 KiB |
{kind=link}
|
After Width: | Height: | Size: 25 KiB |
BIN
CYFI445/lectures/06_universal_approximation_theorem/UAE.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 42 KiB |
@@ -0,0 +1,15 @@
|
||||
// Artificial Neuron
|
||||
digraph {
|
||||
x1 [label="x₁" fillcolor=lightblue shape=circle style=filled]
|
||||
x2 [label="x₂" fillcolor=lightblue shape=circle style=filled]
|
||||
sum [label="Σ
|
||||
(w₁x₁ + w₂x₂ + b)" fillcolor=lightgreen shape=circle style=filled]
|
||||
act [label="σ
|
||||
(sigmoid)" fillcolor=lightyellow shape=circle style=filled]
|
||||
y [label="y
|
||||
(output)" fillcolor=lightcoral shape=circle style=filled]
|
||||
x1 -> sum [label="w₁"]
|
||||
x2 -> sum [label="w₂"]
|
||||
sum -> act
|
||||
act -> y
|
||||
}
|
||||
250
CYFI445/lectures/06_universal_approximation_theorem/neuron.ipynb
Normal file
BIN
CYFI445/lectures/06_universal_approximation_theorem/neuron.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 41 KiB |
@@ -0,0 +1,484 @@
|
||||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "31ee256c",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"## Breast cancer prediction"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"id": "53af081c",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"import torch\n",
|
||||
"import torch.nn as nn\n",
|
||||
"import numpy as np\n",
|
||||
"from sklearn.datasets import load_breast_cancer\n",
|
||||
"from sklearn.preprocessing import StandardScaler\n",
|
||||
"from sklearn.model_selection import train_test_split"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "536078f0",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Load and preprocess breast cancer dataset"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"id": "06746e3c",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"\"\"\"Load and preprocess breast cancer dataset.\"\"\"\n",
|
||||
"# Load dataset\n",
|
||||
"data = load_breast_cancer()\n",
|
||||
"X, y = data.data, data.target"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "3477485c",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Understand inputs"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"id": "76d4d576",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"(569, 30)"
|
||||
]
|
||||
},
|
||||
"execution_count": 4,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"X.shape"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"id": "fddcc037",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"array([1.799e+01, 1.038e+01, 1.228e+02, 1.001e+03, 1.184e-01, 2.776e-01,\n",
|
||||
" 3.001e-01, 1.471e-01, 2.419e-01, 7.871e-02, 1.095e+00, 9.053e-01,\n",
|
||||
" 8.589e+00, 1.534e+02, 6.399e-03, 4.904e-02, 5.373e-02, 1.587e-02,\n",
|
||||
" 3.003e-02, 6.193e-03, 2.538e+01, 1.733e+01, 1.846e+02, 2.019e+03,\n",
|
||||
" 1.622e-01, 6.656e-01, 7.119e-01, 2.654e-01, 4.601e-01, 1.189e-01])"
|
||||
]
|
||||
},
|
||||
"execution_count": 5,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"X[0, :]"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 6,
|
||||
"id": "070dcd69",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"(569,)"
|
||||
]
|
||||
},
|
||||
"execution_count": 6,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"y.shape"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 7,
|
||||
"id": "c4632c29",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"np.int64(0)"
|
||||
]
|
||||
},
|
||||
"execution_count": 7,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"y[0]"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "b74373cb",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
" ### Split dataset into training and testing"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 8,
|
||||
"id": "0675a8c7",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"X_train, X_test, y_train, y_test = train_test_split(\n",
|
||||
" X, y, test_size=0.2, random_state=1234\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 9,
|
||||
"id": "bfe70bd9",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"(455, 30)"
|
||||
]
|
||||
},
|
||||
"execution_count": 9,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"X_train.shape"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 10,
|
||||
"id": "a4df0052",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"(114, 30)"
|
||||
]
|
||||
},
|
||||
"execution_count": 10,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"X_test.shape"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "d597a997",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Scale fetures\n",
|
||||
"Scaling features, as done in the code with StandardScaler, transforms the input data so that each feature has a mean of 0 and a standard deviation of 1. This is also known as standardization. The purpose of scaling features in this context is to:\n",
|
||||
"\n",
|
||||
"- Improve Model Convergence: Many machine learning algorithms, including neural networks optimized with gradient-based methods like SGD, converge faster when features are on a similar scale. Unscaled features with different ranges can cause gradients to vary widely, slowing down or destabilizing training.\n",
|
||||
"- Ensure Fair Feature Influence: Features with larger numerical ranges could disproportionately influence the model compared to features with smaller ranges. Standardization ensures all features contribute equally to the model's predictions.\n",
|
||||
"- Enhance Numerical Stability: Large or highly variable feature values can lead to numerical instability in computations, especially in deep learning frameworks like PyTorch. Scaling mitigates this risk."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 11,
|
||||
"id": "3aeb88da",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# Scale features\n",
|
||||
"scaler = StandardScaler()\n",
|
||||
"X_train = scaler.fit_transform(X_train)\n",
|
||||
"X_test = scaler.transform(X_test)\n",
|
||||
"\n",
|
||||
"# Convert to PyTorch tensors\n",
|
||||
"X_train = torch.from_numpy(X_train.astype(np.float32))\n",
|
||||
"X_test = torch.from_numpy(X_test.astype(np.float32))\n",
|
||||
"y_train = torch.from_numpy(y_train.astype(np.float32)).view(-1, 1)\n",
|
||||
"y_test = torch.from_numpy(y_test.astype(np.float32)).view(-1, 1)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 12,
|
||||
"id": "3b10079f",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"torch.Size([455, 30])"
|
||||
]
|
||||
},
|
||||
"execution_count": 12,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"X_train.shape"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 13,
|
||||
"id": "13f4059c",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"tensor([-0.3618, -0.2652, -0.3172, -0.4671, 1.8038, 1.1817, -0.5169, 0.1065,\n",
|
||||
" -0.3901, 1.3914, 0.1437, -0.1208, 0.1601, -0.1326, -0.5863, -0.1248,\n",
|
||||
" -0.5787, 0.1091, -0.2819, -0.1889, -0.2571, -0.2403, -0.2442, -0.3669,\n",
|
||||
" 0.5449, 0.2481, -0.7109, -0.0797, -0.5280, 0.2506])"
|
||||
]
|
||||
},
|
||||
"execution_count": 13,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"X_train[0,:]"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "b0b15d2f",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Binary Classifier model"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 14,
|
||||
"id": "e1b50a04",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"class BinaryClassifier(nn.Module):\n",
|
||||
" \"\"\"Simple neural network for binary classification.\"\"\"\n",
|
||||
" def __init__(self, input_features):\n",
|
||||
" super(BinaryClassifier, self).__init__()\n",
|
||||
" self.linear = nn.Linear(input_features, 1)\n",
|
||||
" \n",
|
||||
" def forward(self, x):\n",
|
||||
" return torch.sigmoid(self.linear(x))"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 15,
|
||||
"id": "49694959",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"torch.Size([455, 30])"
|
||||
]
|
||||
},
|
||||
"execution_count": 15,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"X_train.shape"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "14873622",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### show binary classification model \n",
|
||||
"- the number of input features\n",
|
||||
"- the number of output features"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 16,
|
||||
"id": "466f6c41",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"BinaryClassifier(\n",
|
||||
" (linear): Linear(in_features=30, out_features=1, bias=True)\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
"execution_count": 16,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"n_features = X_train.shape[1]\n",
|
||||
"model = BinaryClassifier(n_features)\n",
|
||||
"model"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "c66978b5",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Train the model with given parameters.\n",
|
||||
"\n",
|
||||
"- forward pass: prediction\n",
|
||||
"- loss: error\n",
|
||||
"- autograd: weight change direction\n",
|
||||
"- stochastic gradient descent (optimizer): update weights\n",
|
||||
"- optimizer.zero_grad()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 17,
|
||||
"id": "1d1d7868",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"Epoch [10/100], Loss: 0.4627\n",
|
||||
"Epoch [20/100], Loss: 0.4105\n",
|
||||
"Epoch [30/100], Loss: 0.3721\n",
|
||||
"Epoch [40/100], Loss: 0.3424\n",
|
||||
"Epoch [50/100], Loss: 0.3186\n",
|
||||
"Epoch [60/100], Loss: 0.2990\n",
|
||||
"Epoch [70/100], Loss: 0.2825\n",
|
||||
"Epoch [80/100], Loss: 0.2683\n",
|
||||
"Epoch [90/100], Loss: 0.2560\n",
|
||||
"Epoch [100/100], Loss: 0.2452\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"num_epochs=100\n",
|
||||
"learning_rate=0.01\n",
|
||||
"\n",
|
||||
"\"\"\"Train the model with given parameters.\"\"\"\n",
|
||||
"criterion = nn.BCELoss()\n",
|
||||
"optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)\n",
|
||||
"\n",
|
||||
"for epoch in range(num_epochs):\n",
|
||||
" # Forward pass\n",
|
||||
" y_pred = model(X_train)\n",
|
||||
" loss = criterion(y_pred, y_train)\n",
|
||||
" \n",
|
||||
" # Backward pass and optimization\n",
|
||||
" optimizer.zero_grad()\n",
|
||||
" loss.backward()\n",
|
||||
" optimizer.step()\n",
|
||||
" \n",
|
||||
" # Log progress\n",
|
||||
" if (epoch + 1) % 10 == 0:\n",
|
||||
" print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}')\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "1a59248d",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Evaluate model performance on test set"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 18,
|
||||
"id": "eeddd812",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"\n",
|
||||
"Test Accuracy: 0.8947\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"with torch.no_grad():\n",
|
||||
" y_pred = model(X_test)\n",
|
||||
" y_pred_classes = y_pred.round() # Values 𝑥 ≥ 0.5 are rounded to 1, else 0\n",
|
||||
" accuracy = y_pred_classes.eq(y_test).sum() / float(y_test.shape[0])\n",
|
||||
" print(f'\\nTest Accuracy: {accuracy:.4f}')"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "1dc4fcd3",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": []
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.13.2"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 5
|
||||
}
|
||||
@@ -0,0 +1,146 @@
|
||||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"id": "53af081c",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"Training model...\n",
|
||||
"Epoch [10/100], Loss: 0.6247\n",
|
||||
"Epoch [20/100], Loss: 0.4940\n",
|
||||
"Epoch [30/100], Loss: 0.4156\n",
|
||||
"Epoch [40/100], Loss: 0.3641\n",
|
||||
"Epoch [50/100], Loss: 0.3277\n",
|
||||
"Epoch [60/100], Loss: 0.3005\n",
|
||||
"Epoch [70/100], Loss: 0.2794\n",
|
||||
"Epoch [80/100], Loss: 0.2624\n",
|
||||
"Epoch [90/100], Loss: 0.2483\n",
|
||||
"Epoch [100/100], Loss: 0.2364\n",
|
||||
"\n",
|
||||
"Test Accuracy: 0.9211\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"import torch\n",
|
||||
"import torch.nn as nn\n",
|
||||
"import numpy as np\n",
|
||||
"from sklearn.datasets import load_breast_cancer\n",
|
||||
"from sklearn.preprocessing import StandardScaler\n",
|
||||
"from sklearn.model_selection import train_test_split\n",
|
||||
"\n",
|
||||
"def prepare_data():\n",
|
||||
" \"\"\"Load and preprocess breast cancer dataset.\"\"\"\n",
|
||||
" # Load dataset\n",
|
||||
" data = load_breast_cancer()\n",
|
||||
" X, y = data.data, data.target\n",
|
||||
" \n",
|
||||
" # Split dataset\n",
|
||||
" X_train, X_test, y_train, y_test = train_test_split(\n",
|
||||
" X, y, test_size=0.2, random_state=1234\n",
|
||||
" )\n",
|
||||
" \n",
|
||||
" # Scale features\n",
|
||||
" scaler = StandardScaler()\n",
|
||||
" X_train = scaler.fit_transform(X_train)\n",
|
||||
" X_test = scaler.transform(X_test)\n",
|
||||
" \n",
|
||||
" # Convert to PyTorch tensors\n",
|
||||
" X_train = torch.from_numpy(X_train.astype(np.float32))\n",
|
||||
" X_test = torch.from_numpy(X_test.astype(np.float32))\n",
|
||||
" y_train = torch.from_numpy(y_train.astype(np.float32)).view(-1, 1)\n",
|
||||
" y_test = torch.from_numpy(y_test.astype(np.float32)).view(-1, 1)\n",
|
||||
" \n",
|
||||
" return X_train, X_test, y_train, y_test\n",
|
||||
"\n",
|
||||
"class BinaryClassifier(nn.Module):\n",
|
||||
" \"\"\"Simple neural network for binary classification.\"\"\"\n",
|
||||
" def __init__(self, input_features):\n",
|
||||
" super(BinaryClassifier, self).__init__()\n",
|
||||
" self.linear = nn.Linear(input_features, 1)\n",
|
||||
" \n",
|
||||
" def forward(self, x):\n",
|
||||
" return torch.sigmoid(self.linear(x))\n",
|
||||
"\n",
|
||||
"def train_model(model, X_train, y_train, num_epochs=100, learning_rate=0.01):\n",
|
||||
" \"\"\"Train the model with given parameters.\"\"\"\n",
|
||||
" criterion = nn.BCELoss()\n",
|
||||
" optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)\n",
|
||||
" \n",
|
||||
" for epoch in range(num_epochs):\n",
|
||||
" # Forward pass\n",
|
||||
" y_pred = model(X_train)\n",
|
||||
" loss = criterion(y_pred, y_train)\n",
|
||||
" \n",
|
||||
" # Backward pass and optimization\n",
|
||||
" optimizer.zero_grad()\n",
|
||||
" loss.backward()\n",
|
||||
" optimizer.step()\n",
|
||||
" \n",
|
||||
" # Log progress\n",
|
||||
" if (epoch + 1) % 10 == 0:\n",
|
||||
" print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}')\n",
|
||||
"\n",
|
||||
"def evaluate_model(model, X_test, y_test):\n",
|
||||
" \"\"\"Evaluate model performance on test set.\"\"\"\n",
|
||||
" with torch.no_grad():\n",
|
||||
" y_pred = model(X_test)\n",
|
||||
" y_pred_classes = y_pred.round()\n",
|
||||
" accuracy = y_pred_classes.eq(y_test).sum() / float(y_test.shape[0])\n",
|
||||
" return accuracy.item()\n",
|
||||
"\n",
|
||||
"def main():\n",
|
||||
" # Prepare data\n",
|
||||
" X_train, X_test, y_train, y_test = prepare_data()\n",
|
||||
" \n",
|
||||
" # Initialize model\n",
|
||||
" n_features = X_train.shape[1]\n",
|
||||
" model = BinaryClassifier(n_features)\n",
|
||||
" \n",
|
||||
" # Train model\n",
|
||||
" print(\"Training model...\")\n",
|
||||
" train_model(model, X_train, y_train)\n",
|
||||
" \n",
|
||||
" # Evaluate model\n",
|
||||
" accuracy = evaluate_model(model, X_test, y_test)\n",
|
||||
" print(f'\\nTest Accuracy: {accuracy:.4f}')\n",
|
||||
"\n",
|
||||
"main()"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "76d4d576",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": []
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.13.2"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 5
|
||||
}
|
||||
@@ -0,0 +1,209 @@
|
||||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"id": "52950b67",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"First sample - Features: tensor([1.4230e+01, 1.7100e+00, 2.4300e+00, 1.5600e+01, 1.2700e+02, 2.8000e+00,\n",
|
||||
" 3.0600e+00, 2.8000e-01, 2.2900e+00, 5.6400e+00, 1.0400e+00, 3.9200e+00,\n",
|
||||
" 1.0650e+03]), Label: tensor([1.])\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"import torch\n",
|
||||
"import torchvision\n",
|
||||
"from torch.utils.data import Dataset, DataLoader\n",
|
||||
"import numpy as np\n",
|
||||
"import math\n",
|
||||
"\n",
|
||||
"# Custom Dataset class for Wine dataset\n",
|
||||
"class WineDataset(Dataset):\n",
|
||||
" def __init__(self, data_path='data/wine.csv'):\n",
|
||||
" \"\"\"\n",
|
||||
" Initialize the dataset by loading wine data from a CSV file.\n",
|
||||
" \n",
|
||||
" Args:\n",
|
||||
" data_path (str): Path to the wine CSV file\n",
|
||||
" \"\"\"\n",
|
||||
" # Load data from CSV, skipping header row\n",
|
||||
" xy = np.loadtxt(data_path, delimiter=',', dtype=np.float32, skiprows=1)\n",
|
||||
" self.n_samples = xy.shape[0]\n",
|
||||
" \n",
|
||||
" # Split into features (all columns except first) and labels (first column)\n",
|
||||
" self.x_data = torch.from_numpy(xy[:, 1:]) # Shape: [n_samples, n_features]\n",
|
||||
" self.y_data = torch.from_numpy(xy[:, [0]]) # Shape: [n_samples, 1]\n",
|
||||
"\n",
|
||||
" def __getitem__(self, index):\n",
|
||||
" \"\"\"\n",
|
||||
" Enable indexing to retrieve a specific sample.\n",
|
||||
" \n",
|
||||
" Args:\n",
|
||||
" index (int): Index of the sample to retrieve\n",
|
||||
" \n",
|
||||
" Returns:\n",
|
||||
" tuple: (features, label) for the specified index\n",
|
||||
" \"\"\"\n",
|
||||
" return self.x_data[index], self.y_data[index]\n",
|
||||
"\n",
|
||||
" def __len__(self):\n",
|
||||
" \"\"\"\n",
|
||||
" Return the total number of samples in the dataset.\n",
|
||||
" \n",
|
||||
" Returns:\n",
|
||||
" int: Number of samples\n",
|
||||
" \"\"\"\n",
|
||||
" return self.n_samples\n",
|
||||
"\n",
|
||||
"# Create dataset instance\n",
|
||||
"dataset = WineDataset()\n",
|
||||
"\n",
|
||||
"# Access and print first sample\n",
|
||||
"features, labels = dataset[0]\n",
|
||||
"print(f\"First sample - Features: {features}, Label: {labels}\")\n",
|
||||
"\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"id": "5448f749",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"Sample batch - Features: torch.Size([4, 13]), Labels: torch.Size([4, 1])\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"\"\"\"\n",
|
||||
"Create a DataLoader for the wine dataset.\n",
|
||||
"\n",
|
||||
"Args:\n",
|
||||
" dataset (Dataset): The dataset to load\n",
|
||||
" batch_size (int): Number of samples per batch\n",
|
||||
" shuffle (bool): Whether to shuffle the data\n",
|
||||
" num_workers (int): Number of subprocesses for data loading\n",
|
||||
" \n",
|
||||
"Returns:\n",
|
||||
" DataLoader: Configured DataLoader instance\n",
|
||||
"\"\"\"\n",
|
||||
"train_loader = DataLoader(dataset, batch_size=4, shuffle=True, num_workers=0)\n",
|
||||
"\n",
|
||||
"# Examine one batch\n",
|
||||
"dataiter = iter(train_loader)\n",
|
||||
"features, labels = next(dataiter)\n",
|
||||
"print(f\"Sample batch - Features: {features.shape}, Labels: {labels.shape}\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 6,
|
||||
"id": "0e122c46",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"Total samples: 178, Iterations per epoch: 45\n",
|
||||
"Epoch: 1/2, Step 5/45 | Inputs torch.Size([4, 13]) | Labels torch.Size([4, 1])\n",
|
||||
"Epoch: 1/2, Step 10/45 | Inputs torch.Size([4, 13]) | Labels torch.Size([4, 1])\n",
|
||||
"Epoch: 1/2, Step 15/45 | Inputs torch.Size([4, 13]) | Labels torch.Size([4, 1])\n",
|
||||
"Epoch: 1/2, Step 20/45 | Inputs torch.Size([4, 13]) | Labels torch.Size([4, 1])\n",
|
||||
"Epoch: 1/2, Step 25/45 | Inputs torch.Size([4, 13]) | Labels torch.Size([4, 1])\n",
|
||||
"Epoch: 1/2, Step 30/45 | Inputs torch.Size([4, 13]) | Labels torch.Size([4, 1])\n",
|
||||
"Epoch: 1/2, Step 35/45 | Inputs torch.Size([4, 13]) | Labels torch.Size([4, 1])\n",
|
||||
"Epoch: 1/2, Step 40/45 | Inputs torch.Size([4, 13]) | Labels torch.Size([4, 1])\n",
|
||||
"Epoch: 1/2, Step 45/45 | Inputs torch.Size([2, 13]) | Labels torch.Size([2, 1])\n",
|
||||
"Epoch: 2/2, Step 5/45 | Inputs torch.Size([4, 13]) | Labels torch.Size([4, 1])\n",
|
||||
"Epoch: 2/2, Step 10/45 | Inputs torch.Size([4, 13]) | Labels torch.Size([4, 1])\n",
|
||||
"Epoch: 2/2, Step 15/45 | Inputs torch.Size([4, 13]) | Labels torch.Size([4, 1])\n",
|
||||
"Epoch: 2/2, Step 20/45 | Inputs torch.Size([4, 13]) | Labels torch.Size([4, 1])\n",
|
||||
"Epoch: 2/2, Step 25/45 | Inputs torch.Size([4, 13]) | Labels torch.Size([4, 1])\n",
|
||||
"Epoch: 2/2, Step 30/45 | Inputs torch.Size([4, 13]) | Labels torch.Size([4, 1])\n",
|
||||
"Epoch: 2/2, Step 35/45 | Inputs torch.Size([4, 13]) | Labels torch.Size([4, 1])\n",
|
||||
"Epoch: 2/2, Step 40/45 | Inputs torch.Size([4, 13]) | Labels torch.Size([4, 1])\n",
|
||||
"Epoch: 2/2, Step 45/45 | Inputs torch.Size([2, 13]) | Labels torch.Size([2, 1])\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"# Training loop parameters\n",
|
||||
"num_epochs = 2\n",
|
||||
"total_samples = len(dataset)\n",
|
||||
"n_iterations = math.ceil(total_samples / 4)\n",
|
||||
"print(f\"Total samples: {total_samples}, Iterations per epoch: {n_iterations}\")\n",
|
||||
"\n",
|
||||
"# Dummy training loop\n",
|
||||
"for epoch in range(num_epochs):\n",
|
||||
" for i, (inputs, labels) in enumerate(train_loader):\n",
|
||||
" # Training step\n",
|
||||
" if (i + 1) % 5 == 0:\n",
|
||||
" print(f'Epoch: {epoch+1}/{num_epochs}, Step {i+1}/{n_iterations} | '\n",
|
||||
" f'Inputs {inputs.shape} | Labels {labels.shape}')"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 7,
|
||||
"id": "37095d28",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"MNIST batch - Inputs: torch.Size([3, 1, 28, 28]), Targets: torch.Size([3])\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"# Example with MNIST dataset\n",
|
||||
"train_dataset = torchvision.datasets.MNIST(root='./data',\n",
|
||||
" train=True,\n",
|
||||
" transform=torchvision.transforms.ToTensor(),\n",
|
||||
" download=True)\n",
|
||||
"\n",
|
||||
"mnist_loader = DataLoader(dataset=train_dataset,\n",
|
||||
" batch_size=3,\n",
|
||||
" shuffle=True)\n",
|
||||
"\n",
|
||||
"# Examine MNIST batch\n",
|
||||
"dataiter = iter(mnist_loader)\n",
|
||||
"inputs, targets = next(dataiter)\n",
|
||||
"print(f\"MNIST batch - Inputs: {inputs.shape}, Targets: {targets.shape}\")"
|
||||
]
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.13.2"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 5
|
||||
}
|
||||
179
CYFI445/lectures/07_binary_classification_n_to_1/data/wine.csv
Normal file
@@ -0,0 +1,179 @@
|
||||
Wine,Alcohol,Malic.acid,Ash,Acl,Mg,Phenols,Flavanoids,Nonflavanoid.phenols,Proanth,Color.int,Hue,OD,Proline
|
||||
1,14.23,1.71,2.43,15.6,127,2.8,3.06,.28,2.29,5.64,1.04,3.92,1065
|
||||
1,13.2,1.78,2.14,11.2,100,2.65,2.76,.26,1.28,4.38,1.05,3.4,1050
|
||||
1,13.16,2.36,2.67,18.6,101,2.8,3.24,.3,2.81,5.68,1.03,3.17,1185
|
||||
1,14.37,1.95,2.5,16.8,113,3.85,3.49,.24,2.18,7.8,.86,3.45,1480
|
||||
1,13.24,2.59,2.87,21,118,2.8,2.69,.39,1.82,4.32,1.04,2.93,735
|
||||
1,14.2,1.76,2.45,15.2,112,3.27,3.39,.34,1.97,6.75,1.05,2.85,1450
|
||||
1,14.39,1.87,2.45,14.6,96,2.5,2.52,.3,1.98,5.25,1.02,3.58,1290
|
||||
1,14.06,2.15,2.61,17.6,121,2.6,2.51,.31,1.25,5.05,1.06,3.58,1295
|
||||
1,14.83,1.64,2.17,14,97,2.8,2.98,.29,1.98,5.2,1.08,2.85,1045
|
||||
1,13.86,1.35,2.27,16,98,2.98,3.15,.22,1.85,7.22,1.01,3.55,1045
|
||||
1,14.1,2.16,2.3,18,105,2.95,3.32,.22,2.38,5.75,1.25,3.17,1510
|
||||
1,14.12,1.48,2.32,16.8,95,2.2,2.43,.26,1.57,5,1.17,2.82,1280
|
||||
1,13.75,1.73,2.41,16,89,2.6,2.76,.29,1.81,5.6,1.15,2.9,1320
|
||||
1,14.75,1.73,2.39,11.4,91,3.1,3.69,.43,2.81,5.4,1.25,2.73,1150
|
||||
1,14.38,1.87,2.38,12,102,3.3,3.64,.29,2.96,7.5,1.2,3,1547
|
||||
1,13.63,1.81,2.7,17.2,112,2.85,2.91,.3,1.46,7.3,1.28,2.88,1310
|
||||
1,14.3,1.92,2.72,20,120,2.8,3.14,.33,1.97,6.2,1.07,2.65,1280
|
||||
1,13.83,1.57,2.62,20,115,2.95,3.4,.4,1.72,6.6,1.13,2.57,1130
|
||||
1,14.19,1.59,2.48,16.5,108,3.3,3.93,.32,1.86,8.7,1.23,2.82,1680
|
||||
1,13.64,3.1,2.56,15.2,116,2.7,3.03,.17,1.66,5.1,.96,3.36,845
|
||||
1,14.06,1.63,2.28,16,126,3,3.17,.24,2.1,5.65,1.09,3.71,780
|
||||
1,12.93,3.8,2.65,18.6,102,2.41,2.41,.25,1.98,4.5,1.03,3.52,770
|
||||
1,13.71,1.86,2.36,16.6,101,2.61,2.88,.27,1.69,3.8,1.11,4,1035
|
||||
1,12.85,1.6,2.52,17.8,95,2.48,2.37,.26,1.46,3.93,1.09,3.63,1015
|
||||
1,13.5,1.81,2.61,20,96,2.53,2.61,.28,1.66,3.52,1.12,3.82,845
|
||||
1,13.05,2.05,3.22,25,124,2.63,2.68,.47,1.92,3.58,1.13,3.2,830
|
||||
1,13.39,1.77,2.62,16.1,93,2.85,2.94,.34,1.45,4.8,.92,3.22,1195
|
||||
1,13.3,1.72,2.14,17,94,2.4,2.19,.27,1.35,3.95,1.02,2.77,1285
|
||||
1,13.87,1.9,2.8,19.4,107,2.95,2.97,.37,1.76,4.5,1.25,3.4,915
|
||||
1,14.02,1.68,2.21,16,96,2.65,2.33,.26,1.98,4.7,1.04,3.59,1035
|
||||
1,13.73,1.5,2.7,22.5,101,3,3.25,.29,2.38,5.7,1.19,2.71,1285
|
||||
1,13.58,1.66,2.36,19.1,106,2.86,3.19,.22,1.95,6.9,1.09,2.88,1515
|
||||
1,13.68,1.83,2.36,17.2,104,2.42,2.69,.42,1.97,3.84,1.23,2.87,990
|
||||
1,13.76,1.53,2.7,19.5,132,2.95,2.74,.5,1.35,5.4,1.25,3,1235
|
||||
1,13.51,1.8,2.65,19,110,2.35,2.53,.29,1.54,4.2,1.1,2.87,1095
|
||||
1,13.48,1.81,2.41,20.5,100,2.7,2.98,.26,1.86,5.1,1.04,3.47,920
|
||||
1,13.28,1.64,2.84,15.5,110,2.6,2.68,.34,1.36,4.6,1.09,2.78,880
|
||||
1,13.05,1.65,2.55,18,98,2.45,2.43,.29,1.44,4.25,1.12,2.51,1105
|
||||
1,13.07,1.5,2.1,15.5,98,2.4,2.64,.28,1.37,3.7,1.18,2.69,1020
|
||||
1,14.22,3.99,2.51,13.2,128,3,3.04,.2,2.08,5.1,.89,3.53,760
|
||||
1,13.56,1.71,2.31,16.2,117,3.15,3.29,.34,2.34,6.13,.95,3.38,795
|
||||
1,13.41,3.84,2.12,18.8,90,2.45,2.68,.27,1.48,4.28,.91,3,1035
|
||||
1,13.88,1.89,2.59,15,101,3.25,3.56,.17,1.7,5.43,.88,3.56,1095
|
||||
1,13.24,3.98,2.29,17.5,103,2.64,2.63,.32,1.66,4.36,.82,3,680
|
||||
1,13.05,1.77,2.1,17,107,3,3,.28,2.03,5.04,.88,3.35,885
|
||||
1,14.21,4.04,2.44,18.9,111,2.85,2.65,.3,1.25,5.24,.87,3.33,1080
|
||||
1,14.38,3.59,2.28,16,102,3.25,3.17,.27,2.19,4.9,1.04,3.44,1065
|
||||
1,13.9,1.68,2.12,16,101,3.1,3.39,.21,2.14,6.1,.91,3.33,985
|
||||
1,14.1,2.02,2.4,18.8,103,2.75,2.92,.32,2.38,6.2,1.07,2.75,1060
|
||||
1,13.94,1.73,2.27,17.4,108,2.88,3.54,.32,2.08,8.90,1.12,3.1,1260
|
||||
1,13.05,1.73,2.04,12.4,92,2.72,3.27,.17,2.91,7.2,1.12,2.91,1150
|
||||
1,13.83,1.65,2.6,17.2,94,2.45,2.99,.22,2.29,5.6,1.24,3.37,1265
|
||||
1,13.82,1.75,2.42,14,111,3.88,3.74,.32,1.87,7.05,1.01,3.26,1190
|
||||
1,13.77,1.9,2.68,17.1,115,3,2.79,.39,1.68,6.3,1.13,2.93,1375
|
||||
1,13.74,1.67,2.25,16.4,118,2.6,2.9,.21,1.62,5.85,.92,3.2,1060
|
||||
1,13.56,1.73,2.46,20.5,116,2.96,2.78,.2,2.45,6.25,.98,3.03,1120
|
||||
1,14.22,1.7,2.3,16.3,118,3.2,3,.26,2.03,6.38,.94,3.31,970
|
||||
1,13.29,1.97,2.68,16.8,102,3,3.23,.31,1.66,6,1.07,2.84,1270
|
||||
1,13.72,1.43,2.5,16.7,108,3.4,3.67,.19,2.04,6.8,.89,2.87,1285
|
||||
2,12.37,.94,1.36,10.6,88,1.98,.57,.28,.42,1.95,1.05,1.82,520
|
||||
2,12.33,1.1,2.28,16,101,2.05,1.09,.63,.41,3.27,1.25,1.67,680
|
||||
2,12.64,1.36,2.02,16.8,100,2.02,1.41,.53,.62,5.75,.98,1.59,450
|
||||
2,13.67,1.25,1.92,18,94,2.1,1.79,.32,.73,3.8,1.23,2.46,630
|
||||
2,12.37,1.13,2.16,19,87,3.5,3.1,.19,1.87,4.45,1.22,2.87,420
|
||||
2,12.17,1.45,2.53,19,104,1.89,1.75,.45,1.03,2.95,1.45,2.23,355
|
||||
2,12.37,1.21,2.56,18.1,98,2.42,2.65,.37,2.08,4.6,1.19,2.3,678
|
||||
2,13.11,1.01,1.7,15,78,2.98,3.18,.26,2.28,5.3,1.12,3.18,502
|
||||
2,12.37,1.17,1.92,19.6,78,2.11,2,.27,1.04,4.68,1.12,3.48,510
|
||||
2,13.34,.94,2.36,17,110,2.53,1.3,.55,.42,3.17,1.02,1.93,750
|
||||
2,12.21,1.19,1.75,16.8,151,1.85,1.28,.14,2.5,2.85,1.28,3.07,718
|
||||
2,12.29,1.61,2.21,20.4,103,1.1,1.02,.37,1.46,3.05,.906,1.82,870
|
||||
2,13.86,1.51,2.67,25,86,2.95,2.86,.21,1.87,3.38,1.36,3.16,410
|
||||
2,13.49,1.66,2.24,24,87,1.88,1.84,.27,1.03,3.74,.98,2.78,472
|
||||
2,12.99,1.67,2.6,30,139,3.3,2.89,.21,1.96,3.35,1.31,3.5,985
|
||||
2,11.96,1.09,2.3,21,101,3.38,2.14,.13,1.65,3.21,.99,3.13,886
|
||||
2,11.66,1.88,1.92,16,97,1.61,1.57,.34,1.15,3.8,1.23,2.14,428
|
||||
2,13.03,.9,1.71,16,86,1.95,2.03,.24,1.46,4.6,1.19,2.48,392
|
||||
2,11.84,2.89,2.23,18,112,1.72,1.32,.43,.95,2.65,.96,2.52,500
|
||||
2,12.33,.99,1.95,14.8,136,1.9,1.85,.35,2.76,3.4,1.06,2.31,750
|
||||
2,12.7,3.87,2.4,23,101,2.83,2.55,.43,1.95,2.57,1.19,3.13,463
|
||||
2,12,.92,2,19,86,2.42,2.26,.3,1.43,2.5,1.38,3.12,278
|
||||
2,12.72,1.81,2.2,18.8,86,2.2,2.53,.26,1.77,3.9,1.16,3.14,714
|
||||
2,12.08,1.13,2.51,24,78,2,1.58,.4,1.4,2.2,1.31,2.72,630
|
||||
2,13.05,3.86,2.32,22.5,85,1.65,1.59,.61,1.62,4.8,.84,2.01,515
|
||||
2,11.84,.89,2.58,18,94,2.2,2.21,.22,2.35,3.05,.79,3.08,520
|
||||
2,12.67,.98,2.24,18,99,2.2,1.94,.3,1.46,2.62,1.23,3.16,450
|
||||
2,12.16,1.61,2.31,22.8,90,1.78,1.69,.43,1.56,2.45,1.33,2.26,495
|
||||
2,11.65,1.67,2.62,26,88,1.92,1.61,.4,1.34,2.6,1.36,3.21,562
|
||||
2,11.64,2.06,2.46,21.6,84,1.95,1.69,.48,1.35,2.8,1,2.75,680
|
||||
2,12.08,1.33,2.3,23.6,70,2.2,1.59,.42,1.38,1.74,1.07,3.21,625
|
||||
2,12.08,1.83,2.32,18.5,81,1.6,1.5,.52,1.64,2.4,1.08,2.27,480
|
||||
2,12,1.51,2.42,22,86,1.45,1.25,.5,1.63,3.6,1.05,2.65,450
|
||||
2,12.69,1.53,2.26,20.7,80,1.38,1.46,.58,1.62,3.05,.96,2.06,495
|
||||
2,12.29,2.83,2.22,18,88,2.45,2.25,.25,1.99,2.15,1.15,3.3,290
|
||||
2,11.62,1.99,2.28,18,98,3.02,2.26,.17,1.35,3.25,1.16,2.96,345
|
||||
2,12.47,1.52,2.2,19,162,2.5,2.27,.32,3.28,2.6,1.16,2.63,937
|
||||
2,11.81,2.12,2.74,21.5,134,1.6,.99,.14,1.56,2.5,.95,2.26,625
|
||||
2,12.29,1.41,1.98,16,85,2.55,2.5,.29,1.77,2.9,1.23,2.74,428
|
||||
2,12.37,1.07,2.1,18.5,88,3.52,3.75,.24,1.95,4.5,1.04,2.77,660
|
||||
2,12.29,3.17,2.21,18,88,2.85,2.99,.45,2.81,2.3,1.42,2.83,406
|
||||
2,12.08,2.08,1.7,17.5,97,2.23,2.17,.26,1.4,3.3,1.27,2.96,710
|
||||
2,12.6,1.34,1.9,18.5,88,1.45,1.36,.29,1.35,2.45,1.04,2.77,562
|
||||
2,12.34,2.45,2.46,21,98,2.56,2.11,.34,1.31,2.8,.8,3.38,438
|
||||
2,11.82,1.72,1.88,19.5,86,2.5,1.64,.37,1.42,2.06,.94,2.44,415
|
||||
2,12.51,1.73,1.98,20.5,85,2.2,1.92,.32,1.48,2.94,1.04,3.57,672
|
||||
2,12.42,2.55,2.27,22,90,1.68,1.84,.66,1.42,2.7,.86,3.3,315
|
||||
2,12.25,1.73,2.12,19,80,1.65,2.03,.37,1.63,3.4,1,3.17,510
|
||||
2,12.72,1.75,2.28,22.5,84,1.38,1.76,.48,1.63,3.3,.88,2.42,488
|
||||
2,12.22,1.29,1.94,19,92,2.36,2.04,.39,2.08,2.7,.86,3.02,312
|
||||
2,11.61,1.35,2.7,20,94,2.74,2.92,.29,2.49,2.65,.96,3.26,680
|
||||
2,11.46,3.74,1.82,19.5,107,3.18,2.58,.24,3.58,2.9,.75,2.81,562
|
||||
2,12.52,2.43,2.17,21,88,2.55,2.27,.26,1.22,2,.9,2.78,325
|
||||
2,11.76,2.68,2.92,20,103,1.75,2.03,.6,1.05,3.8,1.23,2.5,607
|
||||
2,11.41,.74,2.5,21,88,2.48,2.01,.42,1.44,3.08,1.1,2.31,434
|
||||
2,12.08,1.39,2.5,22.5,84,2.56,2.29,.43,1.04,2.9,.93,3.19,385
|
||||
2,11.03,1.51,2.2,21.5,85,2.46,2.17,.52,2.01,1.9,1.71,2.87,407
|
||||
2,11.82,1.47,1.99,20.8,86,1.98,1.6,.3,1.53,1.95,.95,3.33,495
|
||||
2,12.42,1.61,2.19,22.5,108,2,2.09,.34,1.61,2.06,1.06,2.96,345
|
||||
2,12.77,3.43,1.98,16,80,1.63,1.25,.43,.83,3.4,.7,2.12,372
|
||||
2,12,3.43,2,19,87,2,1.64,.37,1.87,1.28,.93,3.05,564
|
||||
2,11.45,2.4,2.42,20,96,2.9,2.79,.32,1.83,3.25,.8,3.39,625
|
||||
2,11.56,2.05,3.23,28.5,119,3.18,5.08,.47,1.87,6,.93,3.69,465
|
||||
2,12.42,4.43,2.73,26.5,102,2.2,2.13,.43,1.71,2.08,.92,3.12,365
|
||||
2,13.05,5.8,2.13,21.5,86,2.62,2.65,.3,2.01,2.6,.73,3.1,380
|
||||
2,11.87,4.31,2.39,21,82,2.86,3.03,.21,2.91,2.8,.75,3.64,380
|
||||
2,12.07,2.16,2.17,21,85,2.6,2.65,.37,1.35,2.76,.86,3.28,378
|
||||
2,12.43,1.53,2.29,21.5,86,2.74,3.15,.39,1.77,3.94,.69,2.84,352
|
||||
2,11.79,2.13,2.78,28.5,92,2.13,2.24,.58,1.76,3,.97,2.44,466
|
||||
2,12.37,1.63,2.3,24.5,88,2.22,2.45,.4,1.9,2.12,.89,2.78,342
|
||||
2,12.04,4.3,2.38,22,80,2.1,1.75,.42,1.35,2.6,.79,2.57,580
|
||||
3,12.86,1.35,2.32,18,122,1.51,1.25,.21,.94,4.1,.76,1.29,630
|
||||
3,12.88,2.99,2.4,20,104,1.3,1.22,.24,.83,5.4,.74,1.42,530
|
||||
3,12.81,2.31,2.4,24,98,1.15,1.09,.27,.83,5.7,.66,1.36,560
|
||||
3,12.7,3.55,2.36,21.5,106,1.7,1.2,.17,.84,5,.78,1.29,600
|
||||
3,12.51,1.24,2.25,17.5,85,2,.58,.6,1.25,5.45,.75,1.51,650
|
||||
3,12.6,2.46,2.2,18.5,94,1.62,.66,.63,.94,7.1,.73,1.58,695
|
||||
3,12.25,4.72,2.54,21,89,1.38,.47,.53,.8,3.85,.75,1.27,720
|
||||
3,12.53,5.51,2.64,25,96,1.79,.6,.63,1.1,5,.82,1.69,515
|
||||
3,13.49,3.59,2.19,19.5,88,1.62,.48,.58,.88,5.7,.81,1.82,580
|
||||
3,12.84,2.96,2.61,24,101,2.32,.6,.53,.81,4.92,.89,2.15,590
|
||||
3,12.93,2.81,2.7,21,96,1.54,.5,.53,.75,4.6,.77,2.31,600
|
||||
3,13.36,2.56,2.35,20,89,1.4,.5,.37,.64,5.6,.7,2.47,780
|
||||
3,13.52,3.17,2.72,23.5,97,1.55,.52,.5,.55,4.35,.89,2.06,520
|
||||
3,13.62,4.95,2.35,20,92,2,.8,.47,1.02,4.4,.91,2.05,550
|
||||
3,12.25,3.88,2.2,18.5,112,1.38,.78,.29,1.14,8.21,.65,2,855
|
||||
3,13.16,3.57,2.15,21,102,1.5,.55,.43,1.3,4,.6,1.68,830
|
||||
3,13.88,5.04,2.23,20,80,.98,.34,.4,.68,4.9,.58,1.33,415
|
||||
3,12.87,4.61,2.48,21.5,86,1.7,.65,.47,.86,7.65,.54,1.86,625
|
||||
3,13.32,3.24,2.38,21.5,92,1.93,.76,.45,1.25,8.42,.55,1.62,650
|
||||
3,13.08,3.9,2.36,21.5,113,1.41,1.39,.34,1.14,9.40,.57,1.33,550
|
||||
3,13.5,3.12,2.62,24,123,1.4,1.57,.22,1.25,8.60,.59,1.3,500
|
||||
3,12.79,2.67,2.48,22,112,1.48,1.36,.24,1.26,10.8,.48,1.47,480
|
||||
3,13.11,1.9,2.75,25.5,116,2.2,1.28,.26,1.56,7.1,.61,1.33,425
|
||||
3,13.23,3.3,2.28,18.5,98,1.8,.83,.61,1.87,10.52,.56,1.51,675
|
||||
3,12.58,1.29,2.1,20,103,1.48,.58,.53,1.4,7.6,.58,1.55,640
|
||||
3,13.17,5.19,2.32,22,93,1.74,.63,.61,1.55,7.9,.6,1.48,725
|
||||
3,13.84,4.12,2.38,19.5,89,1.8,.83,.48,1.56,9.01,.57,1.64,480
|
||||
3,12.45,3.03,2.64,27,97,1.9,.58,.63,1.14,7.5,.67,1.73,880
|
||||
3,14.34,1.68,2.7,25,98,2.8,1.31,.53,2.7,13,.57,1.96,660
|
||||
3,13.48,1.67,2.64,22.5,89,2.6,1.1,.52,2.29,11.75,.57,1.78,620
|
||||
3,12.36,3.83,2.38,21,88,2.3,.92,.5,1.04,7.65,.56,1.58,520
|
||||
3,13.69,3.26,2.54,20,107,1.83,.56,.5,.8,5.88,.96,1.82,680
|
||||
3,12.85,3.27,2.58,22,106,1.65,.6,.6,.96,5.58,.87,2.11,570
|
||||
3,12.96,3.45,2.35,18.5,106,1.39,.7,.4,.94,5.28,.68,1.75,675
|
||||
3,13.78,2.76,2.3,22,90,1.35,.68,.41,1.03,9.58,.7,1.68,615
|
||||
3,13.73,4.36,2.26,22.5,88,1.28,.47,.52,1.15,6.62,.78,1.75,520
|
||||
3,13.45,3.7,2.6,23,111,1.7,.92,.43,1.46,10.68,.85,1.56,695
|
||||
3,12.82,3.37,2.3,19.5,88,1.48,.66,.4,.97,10.26,.72,1.75,685
|
||||
3,13.58,2.58,2.69,24.5,105,1.55,.84,.39,1.54,8.66,.74,1.8,750
|
||||
3,13.4,4.6,2.86,25,112,1.98,.96,.27,1.11,8.5,.67,1.92,630
|
||||
3,12.2,3.03,2.32,19,96,1.25,.49,.4,.73,5.5,.66,1.83,510
|
||||
3,12.77,2.39,2.28,19.5,86,1.39,.51,.48,.64,9.899999,.57,1.63,470
|
||||
3,14.16,2.51,2.48,20,91,1.68,.7,.44,1.24,9.7,.62,1.71,660
|
||||
3,13.71,5.65,2.45,20.5,95,1.68,.61,.52,1.06,7.7,.64,1.74,740
|
||||
3,13.4,3.91,2.48,23,102,1.8,.75,.43,1.41,7.3,.7,1.56,750
|
||||
3,13.27,4.28,2.26,20,120,1.59,.69,.43,1.35,10.2,.59,1.56,835
|
||||
3,13.17,2.59,2.37,20,120,1.65,.68,.53,1.46,9.3,.6,1.62,840
|
||||
3,14.13,4.1,2.74,24.5,96,2.05,.76,.56,1.35,9.2,.61,1.6,560
|
||||
|
@@ -0,0 +1,207 @@
|
||||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"id": "c694345f",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"Epoch [20/100], Loss: 0.7266\n",
|
||||
"Epoch [40/100], Loss: 0.6070\n",
|
||||
"Epoch [60/100], Loss: 0.5695\n",
|
||||
"Epoch [80/100], Loss: 0.5610\n",
|
||||
"Epoch [100/100], Loss: 0.5574\n",
|
||||
"\n",
|
||||
"Model Architecture:\n",
|
||||
"MultiClassModel(\n",
|
||||
" (layer1): Linear(in_features=4, out_features=64, bias=True)\n",
|
||||
" (relu1): ReLU()\n",
|
||||
" (layer2): Linear(in_features=64, out_features=32, bias=True)\n",
|
||||
" (relu2): ReLU()\n",
|
||||
" (output): Linear(in_features=32, out_features=3, bias=True)\n",
|
||||
" (softmax): Softmax(dim=1)\n",
|
||||
")\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"import torch\n",
|
||||
"import torch.nn as nn\n",
|
||||
"import torch.optim as optim\n",
|
||||
"from sklearn.datasets import load_iris\n",
|
||||
"from sklearn.model_selection import train_test_split\n",
|
||||
"from sklearn.preprocessing import StandardScaler\n",
|
||||
"import numpy as np\n",
|
||||
"\n",
|
||||
"# Define the neural network model\n",
|
||||
"class MultiClassModel(nn.Module):\n",
|
||||
" def __init__(self, input_dim, num_classes):\n",
|
||||
" super(MultiClassModel, self).__init__()\n",
|
||||
" self.layer1 = nn.Linear(input_dim, 64)\n",
|
||||
" self.relu1 = nn.ReLU()\n",
|
||||
" self.layer2 = nn.Linear(64, 32)\n",
|
||||
" self.relu2 = nn.ReLU()\n",
|
||||
" self.output = nn.Linear(32, num_classes)\n",
|
||||
" self.softmax = nn.Softmax(dim=1)\n",
|
||||
" \n",
|
||||
" def forward(self, x):\n",
|
||||
" x = self.relu1(self.layer1(x))\n",
|
||||
" x = self.relu2(self.layer2(x))\n",
|
||||
" x = self.softmax(self.output(x))\n",
|
||||
" return x\n",
|
||||
"\n",
|
||||
"# Load and preprocess Iris dataset\n",
|
||||
"iris = load_iris()\n",
|
||||
"X = iris.data\n",
|
||||
"y = iris.target\n",
|
||||
"\n",
|
||||
"# Standardize features\n",
|
||||
"scaler = StandardScaler()\n",
|
||||
"X = scaler.fit_transform(X)\n",
|
||||
"\n",
|
||||
"# Convert to PyTorch tensors\n",
|
||||
"X = torch.FloatTensor(X)\n",
|
||||
"# nn.CrossEntropyLoss expects the target tensor to have the torch.int64 (long) data type\n",
|
||||
"y = torch.tensor(y, dtype=torch.int64)\n",
|
||||
"\n",
|
||||
"# Split dataset\n",
|
||||
"X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)\n",
|
||||
"\n",
|
||||
"# Model parameters\n",
|
||||
"input_dim = X.shape[1]\n",
|
||||
"num_classes = len(np.unique(y))\n",
|
||||
"\n",
|
||||
"# Initialize model, loss, and optimizer\n",
|
||||
"model = MultiClassModel(input_dim, num_classes)\n",
|
||||
"criterion = nn.CrossEntropyLoss()\n",
|
||||
"optimizer = optim.Adam(model.parameters(), lr=0.001)\n",
|
||||
"\n",
|
||||
"# Training loop\n",
|
||||
"num_epochs = 100\n",
|
||||
"batch_size = 32\n",
|
||||
"n_batches = len(X_train) // batch_size\n",
|
||||
"\n",
|
||||
"for epoch in range(num_epochs):\n",
|
||||
" model.train()\n",
|
||||
" for i in range(0, len(X_train), batch_size):\n",
|
||||
" batch_X = X_train[i:i+batch_size]\n",
|
||||
" batch_y = y_train[i:i+batch_size]\n",
|
||||
" \n",
|
||||
" # Forward pass\n",
|
||||
" outputs = model(batch_X)\n",
|
||||
" loss = criterion(outputs, batch_y)\n",
|
||||
" \n",
|
||||
" # Backward pass and optimization\n",
|
||||
" optimizer.zero_grad()\n",
|
||||
" loss.backward()\n",
|
||||
" optimizer.step()\n",
|
||||
" \n",
|
||||
" # Print progress every 20 epochs\n",
|
||||
" if (epoch + 1) % 20 == 0:\n",
|
||||
" print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}')\n",
|
||||
"\n",
|
||||
"# Print model architecture\n",
|
||||
"print('\\nModel Architecture:')\n",
|
||||
"print(model)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"id": "3d325c03",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"\n",
|
||||
"Test Accuracy: 1.0000\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"# Evaluate model\n",
|
||||
"model.eval()\n",
|
||||
"with torch.no_grad():\n",
|
||||
" test_outputs = model(X_test)\n",
|
||||
" _, predicted = torch.max(test_outputs, 1)\n",
|
||||
" accuracy = (predicted == y_test).float().mean()\n",
|
||||
" print(f'\\nTest Accuracy: {accuracy:.4f}')"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"id": "c15bb757",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"The first prediction [0.000702839985024184, 0.9973917007446289, 0.001905460492707789]\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"print(\"The first prediction\", test_outputs[0].tolist())"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"id": "91588c01",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"tensor([1, 0, 2, 1, 1, 0, 1, 2, 1, 1, 2, 0, 0, 0, 0, 1, 2, 1, 1, 2, 0, 2, 0, 2,\n",
|
||||
" 2, 2, 2, 2, 0, 0])"
|
||||
]
|
||||
},
|
||||
"execution_count": 5,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"predicted"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "3811df4a",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": []
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.13.2"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 5
|
||||
}
|
||||
@@ -0,0 +1,273 @@
|
||||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"id": "46ca8277",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stderr",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"100%|██████████| 170M/170M [00:07<00:00, 24.0MB/s] \n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"Epoch 1, Loss: 1.535, Accuracy: 44.58%\n",
|
||||
"Epoch 2, Loss: 1.254, Accuracy: 54.91%\n",
|
||||
"Epoch 3, Loss: 1.144, Accuracy: 59.47%\n",
|
||||
"Epoch 4, Loss: 1.071, Accuracy: 62.25%\n",
|
||||
"Epoch 5, Loss: 1.017, Accuracy: 64.26%\n",
|
||||
"Epoch 6, Loss: 0.975, Accuracy: 65.75%\n",
|
||||
"Epoch 7, Loss: 0.945, Accuracy: 67.02%\n",
|
||||
"Epoch 8, Loss: 0.916, Accuracy: 68.16%\n",
|
||||
"Epoch 9, Loss: 0.892, Accuracy: 68.86%\n",
|
||||
"Epoch 10, Loss: 0.865, Accuracy: 70.02%\n",
|
||||
"\n",
|
||||
"Test Accuracy: 73.62%\n",
|
||||
"Training complete. Plots saved as 'training_metrics.png', 'confusion_matrix.png', and 'sample_predictions.png'\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"import torch # PyTorch library for tensor computations and deep learning\n",
|
||||
"import torch.nn as nn # Neural network modules\n",
|
||||
"import torch.nn.functional as F # Functional interface for neural network operations\n",
|
||||
"import torch.optim as optim # Optimization algorithms\n",
|
||||
"import torchvision # Computer vision datasets and models\n",
|
||||
"import torchvision.transforms as transforms # Image transformations\n",
|
||||
"import matplotlib.pyplot as plt # Plotting library\n",
|
||||
"import numpy as np # Numerical computations\n",
|
||||
"from sklearn.metrics import confusion_matrix # For confusion matrix\n",
|
||||
"import seaborn as sns # Visualization library for confusion matrix\n",
|
||||
"\n",
|
||||
"# Set random seed for reproducibility across runs\n",
|
||||
"torch.manual_seed(42)\n",
|
||||
"\n",
|
||||
"# Define data transformations for preprocessing\n",
|
||||
"# - RandomHorizontalFlip: Randomly flip images horizontally for data augmentation\n",
|
||||
"# - RandomRotation: Randomly rotate images by up to 10 degrees for augmentation\n",
|
||||
"# - ToTensor: Convert images to PyTorch tensors (HWC to CHW format)\n",
|
||||
"# - Normalize: Normalize RGB channels with mean=0.5 and std=0.5\n",
|
||||
"transform = transforms.Compose([\n",
|
||||
" transforms.RandomHorizontalFlip(),\n",
|
||||
" transforms.RandomRotation(10),\n",
|
||||
" transforms.ToTensor(),\n",
|
||||
" transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))\n",
|
||||
"])\n",
|
||||
"\n",
|
||||
"# Load CIFAR-10 training dataset\n",
|
||||
"# - root: Directory to store dataset\n",
|
||||
"# - train: True for training set\n",
|
||||
"# - download: Download dataset if not present\n",
|
||||
"# - transform: Apply defined transformations\n",
|
||||
"trainset = torchvision.datasets.CIFAR10(root='./data', train=True,\n",
|
||||
" download=True, transform=transform)\n",
|
||||
"# Create DataLoader for training set\n",
|
||||
"# - batch_size: Number of images per batch (64)\n",
|
||||
"# - shuffle: Randomly shuffle data for better training\n",
|
||||
"# - num_workers: Number of subprocesses for data loading\n",
|
||||
"trainloader = torch.utils.data.DataLoader(trainset, batch_size=64,\n",
|
||||
" shuffle=True, num_workers=2)\n",
|
||||
"\n",
|
||||
"# Load CIFAR-10 test dataset\n",
|
||||
"testset = torchvision.datasets.CIFAR10(root='./data', train=False,\n",
|
||||
" download=True, transform=transform)\n",
|
||||
"# Create DataLoader for test set\n",
|
||||
"# - shuffle: False to maintain order for evaluation\n",
|
||||
"testloader = torch.utils.data.DataLoader(testset, batch_size=64,\n",
|
||||
" shuffle=False, num_workers=2)\n",
|
||||
"\n",
|
||||
"# Define class labels for CIFAR-10\n",
|
||||
"classes = ('airplane', 'automobile', 'bird', 'cat', 'deer',\n",
|
||||
" 'dog', 'frog', 'horse', 'ship', 'truck')\n",
|
||||
"\n",
|
||||
"# Define CNN architecture\n",
|
||||
"class Net(nn.Module):\n",
|
||||
" def __init__(self):\n",
|
||||
" super(Net, self).__init__()\n",
|
||||
" # First convolutional layer: 3 input channels (RGB), 32 output channels, 3x3 kernel\n",
|
||||
" self.conv1 = nn.Conv2d(3, 32, 3, padding=1)\n",
|
||||
" # Second convolutional layer: 32 input channels, 64 output channels, 3x3 kernel\n",
|
||||
" self.conv2 = nn.Conv2d(32, 64, 3, padding=1)\n",
|
||||
" # Max pooling layer: 2x2 kernel, stride 2\n",
|
||||
" self.pool = nn.MaxPool2d(2, 2)\n",
|
||||
" # Batch normalization for first conv layer\n",
|
||||
" self.bn1 = nn.BatchNorm2d(32)\n",
|
||||
" # Batch normalization for second conv layer\n",
|
||||
" self.bn2 = nn.BatchNorm2d(64)\n",
|
||||
" # First fully connected layer: Input size calculated from conv output (64*8*8), 512 units\n",
|
||||
" self.fc1 = nn.Linear(64 * 8 * 8, 512)\n",
|
||||
" # Second fully connected layer: 512 units to 10 output classes\n",
|
||||
" self.fc2 = nn.Linear(512, 10)\n",
|
||||
" # Dropout layer with 50% probability to prevent overfitting\n",
|
||||
" self.dropout = nn.Dropout(0.5)\n",
|
||||
"\n",
|
||||
" def forward(self, x):\n",
|
||||
" # Forward pass through the network\n",
|
||||
" # Conv1 -> BatchNorm -> ReLU -> MaxPool\n",
|
||||
" x = self.pool(F.relu(self.bn1(self.conv1(x))))\n",
|
||||
" # Conv2 -> BatchNorm -> ReLU -> MaxPool\n",
|
||||
" x = self.pool(F.relu(self.bn2(self.conv2(x))))\n",
|
||||
" # Flatten the output for fully connected layers\n",
|
||||
" x = x.view(-1, 64 * 8 * 8)\n",
|
||||
" # Fully connected layer 1 -> ReLU\n",
|
||||
" x = F.relu(self.fc1(x))\n",
|
||||
" # Apply dropout\n",
|
||||
" x = self.dropout(x)\n",
|
||||
" # Final fully connected layer for classification\n",
|
||||
" x = self.fc2(x)\n",
|
||||
" return x\n",
|
||||
"\n",
|
||||
"# Initialize model and move to appropriate device (GPU if available, else CPU)\n",
|
||||
"device = torch.device(\"cuda:0\" if torch.cuda.is_available() else \"cpu\")\n",
|
||||
"model = Net().to(device)\n",
|
||||
"\n",
|
||||
"# Define loss function (CrossEntropyLoss for multi-class classification)\n",
|
||||
"criterion = nn.CrossEntropyLoss()\n",
|
||||
"# Define optimizer (Adam with learning rate 0.001)\n",
|
||||
"optimizer = optim.Adam(model.parameters(), lr=0.001)\n",
|
||||
"\n",
|
||||
"# Training loop\n",
|
||||
"num_epochs = 10 # Number of training epochs\n",
|
||||
"train_losses = [] # Store loss per epoch\n",
|
||||
"train_accuracies = [] # Store accuracy per epoch\n",
|
||||
"\n",
|
||||
"for epoch in range(num_epochs):\n",
|
||||
" model.train() # Set model to training mode\n",
|
||||
" running_loss = 0.0 # Track total loss for epoch\n",
|
||||
" correct = 0 # Track correct predictions\n",
|
||||
" total = 0 # Track total samples\n",
|
||||
" for i, data in enumerate(trainloader, 0):\n",
|
||||
" # Get inputs and labels, move to device\n",
|
||||
" inputs, labels = data[0].to(device), data[1].to(device)\n",
|
||||
" # Zero the parameter gradients\n",
|
||||
" optimizer.zero_grad()\n",
|
||||
" # Forward pass\n",
|
||||
" outputs = model(inputs)\n",
|
||||
" # Compute loss\n",
|
||||
" loss = criterion(outputs, labels)\n",
|
||||
" # Backward pass and optimize\n",
|
||||
" loss.backward()\n",
|
||||
" optimizer.step()\n",
|
||||
" \n",
|
||||
" # Update running loss\n",
|
||||
" running_loss += loss.item()\n",
|
||||
" # Calculate accuracy\n",
|
||||
" _, predicted = torch.max(outputs.data, 1)\n",
|
||||
" total += labels.size(0)\n",
|
||||
" correct += (predicted == labels).sum().item()\n",
|
||||
" \n",
|
||||
" # Calculate and store epoch metrics\n",
|
||||
" epoch_loss = running_loss / len(trainloader)\n",
|
||||
" epoch_acc = 100 * correct / total\n",
|
||||
" train_losses.append(epoch_loss)\n",
|
||||
" train_accuracies.append(epoch_acc)\n",
|
||||
" print(f\"Epoch {epoch + 1}, Loss: {epoch_loss:.3f}, Accuracy: {epoch_acc:.2f}%\")\n",
|
||||
"\n",
|
||||
"# Evaluate model on test set\n",
|
||||
"model.eval() # Set model to evaluation mode\n",
|
||||
"correct = 0\n",
|
||||
"total = 0\n",
|
||||
"all_preds = [] # Store predictions for confusion matrix\n",
|
||||
"all_labels = [] # Store true labels\n",
|
||||
"with torch.no_grad(): # Disable gradient computation for evaluation\n",
|
||||
" for data in testloader:\n",
|
||||
" images, labels = data[0].to(device), data[1].to(device)\n",
|
||||
" outputs = model(images)\n",
|
||||
" _, predicted = torch.max(outputs.data, 1)\n",
|
||||
" total += labels.size(0)\n",
|
||||
" correct += (predicted == labels).sum().item()\n",
|
||||
" all_preds.extend(predicted.cpu().numpy())\n",
|
||||
" all_labels.extend(labels.cpu().numpy())\n",
|
||||
"\n",
|
||||
"# Calculate and print test accuracy\n",
|
||||
"test_accuracy = 100 * correct / total\n",
|
||||
"print(f\"\\nTest Accuracy: {test_accuracy:.2f}%\")\n",
|
||||
"\n",
|
||||
"# Plot training metrics (loss and accuracy)\n",
|
||||
"plt.figure(figsize=(12, 4))\n",
|
||||
"\n",
|
||||
"# Plot training loss\n",
|
||||
"plt.subplot(1, 2, 1)\n",
|
||||
"plt.plot(train_losses, label='Training Loss')\n",
|
||||
"plt.title('Training Loss')\n",
|
||||
"plt.xlabel('Epoch')\n",
|
||||
"plt.ylabel('Loss')\n",
|
||||
"plt.legend()\n",
|
||||
"\n",
|
||||
"# Plot training accuracy\n",
|
||||
"plt.subplot(1, 2, 2)\n",
|
||||
"plt.plot(train_accuracies, label='Training Accuracy')\n",
|
||||
"plt.title('Training Accuracy')\n",
|
||||
"plt.xlabel('Epoch')\n",
|
||||
"plt.ylabel('Accuracy (%)')\n",
|
||||
"plt.legend()\n",
|
||||
"\n",
|
||||
"plt.tight_layout()\n",
|
||||
"plt.savefig('training_metrics.png') # Save plot\n",
|
||||
"plt.close()\n",
|
||||
"\n",
|
||||
"# Plot confusion matrix\n",
|
||||
"cm = confusion_matrix(all_labels, all_preds)\n",
|
||||
"plt.figure(figsize=(10, 8))\n",
|
||||
"sns.heatmap(cm, annot=True, fmt='d', cmap='Blues',\n",
|
||||
" xticklabels=classes, yticklabels=classes)\n",
|
||||
"plt.title('Confusion Matrix')\n",
|
||||
"plt.xlabel('Predicted')\n",
|
||||
"plt.ylabel('True')\n",
|
||||
"plt.savefig('confusion_matrix.png') # Save plot\n",
|
||||
"plt.close()\n",
|
||||
"\n",
|
||||
"# Function to unnormalize and display images\n",
|
||||
"def imshow(img):\n",
|
||||
" img = img / 2 + 0.5 # Unnormalize\n",
|
||||
" npimg = img.numpy()\n",
|
||||
" return np.transpose(npimg, (1, 2, 0)) # Convert from CHW to HWC\n",
|
||||
"\n",
|
||||
"# Show sample test images with predictions\n",
|
||||
"dataiter = iter(testloader)\n",
|
||||
"images, labels = next(dataiter)\n",
|
||||
"images, labels = images[:8].to(device), labels[:8]\n",
|
||||
"outputs = model(images)\n",
|
||||
"_, predicted = torch.max(outputs, 1)\n",
|
||||
"\n",
|
||||
"plt.figure(figsize=(12, 6))\n",
|
||||
"for i in range(8):\n",
|
||||
" plt.subplot(2, 4, i + 1)\n",
|
||||
" plt.imshow(imshow(images[i].cpu()))\n",
|
||||
" plt.title(f'Pred: {classes[predicted[i]]}\\nTrue: {classes[labels[i]]}')\n",
|
||||
" plt.axis('off')\n",
|
||||
"plt.savefig('sample_predictions.png') # Save plot\n",
|
||||
"plt.close()\n",
|
||||
"\n",
|
||||
"print(\"Training complete. Plots saved as 'training_metrics.png', 'confusion_matrix.png', and 'sample_predictions.png'\")"
|
||||
]
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.13.2"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 5
|
||||
}
|
||||
{kind=link}
@@ -0,0 +1,225 @@
|
||||
<svg xmlns="http://www.w3.org/2000/svg" xmlns:xlink="http://www.w3.org/1999/xlink" width="402pt" height="263pt" viewBox="0.00 0.00 401.96 263.00">
|
||||
<g id="graph0" class="graph" transform="scale(1 1) rotate(0) translate(4 259)">
|
||||
<title>Dropout</title>
|
||||
<polygon fill="white" stroke="none" points="-4,4 -4,-259 397.96,-259 397.96,4 -4,4"/>
|
||||
<g id="clust1" class="cluster">
|
||||
<title>cluster_input</title>
|
||||
<polygon fill="none" stroke="lightgrey" points="0,-8 0,-247 81.69,-247 81.69,-8 0,-8"/>
|
||||
<text text-anchor="middle" x="40.85" y="-230.4" font-family="Times,serif" font-size="14.00">Input Layer</text>
|
||||
</g>
|
||||
<g id="clust2" class="cluster">
|
||||
<title>cluster_hidden</title>
|
||||
<polygon fill="none" stroke="lightgrey" points="101.69,-8 101.69,-247 282.92,-247 282.92,-8 101.69,-8"/>
|
||||
<text text-anchor="middle" x="192.31" y="-230.4" font-family="Times,serif" font-size="14.00">Hidden Layer (with Dropout)</text>
|
||||
</g>
|
||||
<g id="clust3" class="cluster">
|
||||
<title>cluster_output</title>
|
||||
<polygon fill="none" stroke="lightgrey" points="302.92,-62 302.92,-193 393.96,-193 393.96,-62 302.92,-62"/>
|
||||
<text text-anchor="middle" x="348.44" y="-176.4" font-family="Times,serif" font-size="14.00">Output Layer</text>
|
||||
</g>
|
||||
<!-- I1 -->
|
||||
<g id="node1" class="node">
|
||||
<title>I1</title>
|
||||
<ellipse fill="lightblue" stroke="black" cx="40.35" cy="-34" rx="18" ry="18"/>
|
||||
<text text-anchor="middle" x="40.35" y="-29.8" font-family="Times,serif" font-size="14.00">I1</text>
|
||||
</g>
|
||||
<!-- H1 -->
|
||||
<g id="node5" class="node">
|
||||
<title>H1</title>
|
||||
<ellipse fill="lightgreen" stroke="black" cx="191.81" cy="-34" rx="18" ry="18"/>
|
||||
<text text-anchor="middle" x="191.81" y="-29.8" font-family="Times,serif" font-size="14.00">H1</text>
|
||||
</g>
|
||||
<!-- I1->H1 -->
|
||||
<g id="edge1" class="edge">
|
||||
<title>I1->H1</title>
|
||||
<path fill="none" stroke="black" d="M58.78,-34C84.21,-34 131.75,-34 162.3,-34"/>
|
||||
<polygon fill="black" stroke="black" points="161.97,-37.5 171.97,-34 161.97,-30.5 161.97,-37.5"/>
|
||||
</g>
|
||||
<!-- H2 -->
|
||||
<g id="node6" class="node">
|
||||
<title>H2</title>
|
||||
<ellipse fill="red" stroke="black" stroke-dasharray="5,2" cx="191.81" cy="-88" rx="18" ry="18"/>
|
||||
<text text-anchor="middle" x="191.81" y="-83.8" font-family="Times,serif" font-size="14.00" fill="white">H2</text>
|
||||
</g>
|
||||
<!-- I1->H2 -->
|
||||
<g id="edge2" class="edge">
|
||||
<title>I1->H2</title>
|
||||
<path fill="none" stroke="black" d="M57,-41.66C69.05,-47.4 86.21,-55.22 101.69,-61 121.97,-68.57 145.41,-75.61 163.16,-80.6"/>
|
||||
<polygon fill="black" stroke="black" points="162.15,-83.95 172.72,-83.24 164.01,-77.2 162.15,-83.95"/>
|
||||
</g>
|
||||
<!-- H3 -->
|
||||
<g id="node7" class="node">
|
||||
<title>H3</title>
|
||||
<ellipse fill="lightgreen" stroke="black" cx="191.81" cy="-142" rx="18" ry="18"/>
|
||||
<text text-anchor="middle" x="191.81" y="-137.8" font-family="Times,serif" font-size="14.00">H3</text>
|
||||
</g>
|
||||
<!-- I1->H3 -->
|
||||
<g id="edge3" class="edge">
|
||||
<title>I1->H3</title>
|
||||
<path fill="none" stroke="black" d="M56.9,-41.37C65.24,-45.99 75.12,-52.66 81.69,-61 97.54,-81.09 83.06,-97.46 101.69,-115 118.07,-130.42 142.97,-137.05 162.29,-139.89"/>
|
||||
<polygon fill="black" stroke="black" points="161.62,-143.34 171.97,-141.04 162.45,-136.39 161.62,-143.34"/>
|
||||
</g>
|
||||
<!-- H4 -->
|
||||
<g id="node8" class="node">
|
||||
<title>H4</title>
|
||||
<ellipse fill="red" stroke="black" stroke-dasharray="5,2" cx="191.81" cy="-196" rx="18" ry="18"/>
|
||||
<text text-anchor="middle" x="191.81" y="-191.8" font-family="Times,serif" font-size="14.00" fill="white">H4</text>
|
||||
</g>
|
||||
<!-- I1->H4 -->
|
||||
<g id="edge4" class="edge">
|
||||
<title>I1->H4</title>
|
||||
<path fill="none" stroke="black" d="M57.48,-40.95C65.99,-45.45 75.86,-52.13 81.69,-61 108.53,-101.78 69.14,-132.62 101.69,-169 116.94,-186.04 142.54,-192.49 162.4,-194.86"/>
|
||||
<polygon fill="black" stroke="black" points="161.82,-198.32 172.09,-195.71 162.44,-191.35 161.82,-198.32"/>
|
||||
</g>
|
||||
<!-- I2 -->
|
||||
<g id="node2" class="node">
|
||||
<title>I2</title>
|
||||
<ellipse fill="lightblue" stroke="black" cx="40.35" cy="-88" rx="18" ry="18"/>
|
||||
<text text-anchor="middle" x="40.35" y="-83.8" font-family="Times,serif" font-size="14.00">I2</text>
|
||||
</g>
|
||||
<!-- I2->H1 -->
|
||||
<g id="edge5" class="edge">
|
||||
<title>I2->H1</title>
|
||||
<path fill="none" stroke="black" d="M57,-80.34C69.05,-74.6 86.21,-66.78 101.69,-61 121.97,-53.43 145.41,-46.39 163.16,-41.4"/>
|
||||
<polygon fill="black" stroke="black" points="164.01,-44.8 172.72,-38.76 162.15,-38.05 164.01,-44.8"/>
|
||||
</g>
|
||||
<!-- I2->H2 -->
|
||||
<g id="edge6" class="edge">
|
||||
<title>I2->H2</title>
|
||||
<path fill="none" stroke="black" d="M58.78,-88C84.21,-88 131.75,-88 162.3,-88"/>
|
||||
<polygon fill="black" stroke="black" points="161.97,-91.5 171.97,-88 161.97,-84.5 161.97,-91.5"/>
|
||||
</g>
|
||||
<!-- I2->H3 -->
|
||||
<g id="edge7" class="edge">
|
||||
<title>I2->H3</title>
|
||||
<path fill="none" stroke="black" d="M57,-95.66C69.05,-101.4 86.21,-109.22 101.69,-115 121.97,-122.57 145.41,-129.61 163.16,-134.6"/>
|
||||
<polygon fill="black" stroke="black" points="162.15,-137.95 172.72,-137.24 164.01,-131.2 162.15,-137.95"/>
|
||||
</g>
|
||||
<!-- I2->H4 -->
|
||||
<g id="edge8" class="edge">
|
||||
<title>I2->H4</title>
|
||||
<path fill="none" stroke="black" d="M56.9,-95.37C65.24,-99.99 75.12,-106.66 81.69,-115 97.54,-135.09 83.06,-151.46 101.69,-169 118.07,-184.42 142.97,-191.05 162.29,-193.89"/>
|
||||
<polygon fill="black" stroke="black" points="161.62,-197.34 171.97,-195.04 162.45,-190.39 161.62,-197.34"/>
|
||||
</g>
|
||||
<!-- I3 -->
|
||||
<g id="node3" class="node">
|
||||
<title>I3</title>
|
||||
<ellipse fill="lightblue" stroke="black" cx="40.35" cy="-142" rx="18" ry="18"/>
|
||||
<text text-anchor="middle" x="40.35" y="-137.8" font-family="Times,serif" font-size="14.00">I3</text>
|
||||
</g>
|
||||
<!-- I3->H1 -->
|
||||
<g id="edge9" class="edge">
|
||||
<title>I3->H1</title>
|
||||
<path fill="none" stroke="black" d="M56.9,-134.63C65.24,-130.01 75.12,-123.34 81.69,-115 97.54,-94.91 83.06,-78.54 101.69,-61 118.07,-45.58 142.97,-38.95 162.29,-36.11"/>
|
||||
<polygon fill="black" stroke="black" points="162.45,-39.61 171.97,-34.96 161.62,-32.66 162.45,-39.61"/>
|
||||
</g>
|
||||
<!-- I3->H2 -->
|
||||
<g id="edge10" class="edge">
|
||||
<title>I3->H2</title>
|
||||
<path fill="none" stroke="black" d="M57,-134.34C69.05,-128.6 86.21,-120.78 101.69,-115 121.97,-107.43 145.41,-100.39 163.16,-95.4"/>
|
||||
<polygon fill="black" stroke="black" points="164.01,-98.8 172.72,-92.76 162.15,-92.05 164.01,-98.8"/>
|
||||
</g>
|
||||
<!-- I3->H3 -->
|
||||
<g id="edge11" class="edge">
|
||||
<title>I3->H3</title>
|
||||
<path fill="none" stroke="black" d="M58.78,-142C84.21,-142 131.75,-142 162.3,-142"/>
|
||||
<polygon fill="black" stroke="black" points="161.97,-145.5 171.97,-142 161.97,-138.5 161.97,-145.5"/>
|
||||
</g>
|
||||
<!-- I3->H4 -->
|
||||
<g id="edge12" class="edge">
|
||||
<title>I3->H4</title>
|
||||
<path fill="none" stroke="black" d="M57,-149.66C69.05,-155.4 86.21,-163.22 101.69,-169 121.97,-176.57 145.41,-183.61 163.16,-188.6"/>
|
||||
<polygon fill="black" stroke="black" points="162.15,-191.95 172.72,-191.24 164.01,-185.2 162.15,-191.95"/>
|
||||
</g>
|
||||
<!-- I4 -->
|
||||
<g id="node4" class="node">
|
||||
<title>I4</title>
|
||||
<ellipse fill="lightblue" stroke="black" cx="40.35" cy="-196" rx="18" ry="18"/>
|
||||
<text text-anchor="middle" x="40.35" y="-191.8" font-family="Times,serif" font-size="14.00">I4</text>
|
||||
</g>
|
||||
<!-- I4->H1 -->
|
||||
<g id="edge13" class="edge">
|
||||
<title>I4->H1</title>
|
||||
<path fill="none" stroke="black" d="M57.48,-189.05C65.99,-184.55 75.86,-177.87 81.69,-169 108.53,-128.22 69.14,-97.38 101.69,-61 116.94,-43.96 142.54,-37.51 162.4,-35.14"/>
|
||||
<polygon fill="black" stroke="black" points="162.44,-38.65 172.09,-34.29 161.82,-31.68 162.44,-38.65"/>
|
||||
</g>
|
||||
<!-- I4->H2 -->
|
||||
<g id="edge14" class="edge">
|
||||
<title>I4->H2</title>
|
||||
<path fill="none" stroke="black" d="M56.9,-188.63C65.24,-184.01 75.12,-177.34 81.69,-169 97.54,-148.91 83.06,-132.54 101.69,-115 118.07,-99.58 142.97,-92.95 162.29,-90.11"/>
|
||||
<polygon fill="black" stroke="black" points="162.45,-93.61 171.97,-88.96 161.62,-86.66 162.45,-93.61"/>
|
||||
</g>
|
||||
<!-- I4->H3 -->
|
||||
<g id="edge15" class="edge">
|
||||
<title>I4->H3</title>
|
||||
<path fill="none" stroke="black" d="M57,-188.34C69.05,-182.6 86.21,-174.78 101.69,-169 121.97,-161.43 145.41,-154.39 163.16,-149.4"/>
|
||||
<polygon fill="black" stroke="black" points="164.01,-152.8 172.72,-146.76 162.15,-146.05 164.01,-152.8"/>
|
||||
</g>
|
||||
<!-- I4->H4 -->
|
||||
<g id="edge16" class="edge">
|
||||
<title>I4->H4</title>
|
||||
<path fill="none" stroke="black" d="M58.78,-196C84.21,-196 131.75,-196 162.3,-196"/>
|
||||
<polygon fill="black" stroke="black" points="161.97,-199.5 171.97,-196 161.97,-192.5 161.97,-199.5"/>
|
||||
</g>
|
||||
<!-- O1 -->
|
||||
<g id="node9" class="node">
|
||||
<title>O1</title>
|
||||
<ellipse fill="gold" stroke="black" cx="347.94" cy="-88" rx="18" ry="18"/>
|
||||
<text text-anchor="middle" x="347.94" y="-83.8" font-family="Times,serif" font-size="14.00">O1</text>
|
||||
</g>
|
||||
<!-- H1->O1 -->
|
||||
<g id="edge17" class="edge">
|
||||
<title>H1->O1</title>
|
||||
<path fill="none" stroke="black" d="M209.59,-38.44C227.82,-43.41 257.72,-51.94 282.92,-61 295.57,-65.55 309.33,-71.25 320.84,-76.24"/>
|
||||
<polygon fill="black" stroke="black" points="319.13,-79.31 329.7,-80.14 321.95,-72.9 319.13,-79.31"/>
|
||||
</g>
|
||||
<!-- O2 -->
|
||||
<g id="node10" class="node">
|
||||
<title>O2</title>
|
||||
<ellipse fill="gold" stroke="black" cx="347.94" cy="-142" rx="18" ry="18"/>
|
||||
<text text-anchor="middle" x="347.94" y="-137.8" font-family="Times,serif" font-size="14.00">O2</text>
|
||||
</g>
|
||||
<!-- H1->O2 -->
|
||||
<g id="edge18" class="edge">
|
||||
<title>H1->O2</title>
|
||||
<path fill="none" stroke="black" d="M209.98,-34.69C229.97,-36.4 262.8,-42.11 282.92,-61 301.59,-78.51 286.68,-95.22 302.92,-115 307.78,-120.91 314.29,-125.88 320.81,-129.88"/>
|
||||
<polygon fill="black" stroke="black" points="319.04,-132.9 329.5,-134.63 322.4,-126.76 319.04,-132.9"/>
|
||||
</g>
|
||||
<!-- H2->O1 -->
|
||||
<g id="edge19" class="edge">
|
||||
<title>H2->O1</title>
|
||||
<path fill="none" stroke="gray" stroke-dasharray="5,2" d="M210.19,-88C236.58,-88 287.02,-88 318.72,-88"/>
|
||||
<polygon fill="gray" stroke="gray" points="318.34,-91.5 328.34,-88 318.34,-84.5 318.34,-91.5"/>
|
||||
</g>
|
||||
<!-- H2->O2 -->
|
||||
<g id="edge20" class="edge">
|
||||
<title>H2->O2</title>
|
||||
<path fill="none" stroke="gray" stroke-dasharray="5,2" d="M209.59,-92.44C227.82,-97.41 257.72,-105.94 282.92,-115 295.57,-119.55 309.33,-125.25 320.84,-130.24"/>
|
||||
<polygon fill="gray" stroke="gray" points="319.13,-133.31 329.7,-134.14 321.95,-126.9 319.13,-133.31"/>
|
||||
</g>
|
||||
<!-- H3->O1 -->
|
||||
<g id="edge21" class="edge">
|
||||
<title>H3->O1</title>
|
||||
<path fill="none" stroke="black" d="M209.59,-137.56C227.82,-132.59 257.72,-124.06 282.92,-115 295.57,-110.45 309.33,-104.75 320.84,-99.76"/>
|
||||
<polygon fill="black" stroke="black" points="321.95,-103.1 329.7,-95.86 319.13,-96.69 321.95,-103.1"/>
|
||||
</g>
|
||||
<!-- H3->O2 -->
|
||||
<g id="edge22" class="edge">
|
||||
<title>H3->O2</title>
|
||||
<path fill="none" stroke="black" d="M210.19,-142C236.58,-142 287.02,-142 318.72,-142"/>
|
||||
<polygon fill="black" stroke="black" points="318.34,-145.5 328.34,-142 318.34,-138.5 318.34,-145.5"/>
|
||||
</g>
|
||||
<!-- H4->O1 -->
|
||||
<g id="edge23" class="edge">
|
||||
<title>H4->O1</title>
|
||||
<path fill="none" stroke="gray" stroke-dasharray="5,2" d="M209.98,-195.31C229.97,-193.6 262.8,-187.89 282.92,-169 301.59,-151.49 286.68,-134.78 302.92,-115 307.78,-109.09 314.29,-104.12 320.81,-100.12"/>
|
||||
<polygon fill="gray" stroke="gray" points="322.4,-103.24 329.5,-95.37 319.04,-97.1 322.4,-103.24"/>
|
||||
</g>
|
||||
<!-- H4->O2 -->
|
||||
<g id="edge24" class="edge">
|
||||
<title>H4->O2</title>
|
||||
<path fill="none" stroke="gray" stroke-dasharray="5,2" d="M209.59,-191.56C227.82,-186.59 257.72,-178.06 282.92,-169 295.57,-164.45 309.33,-158.75 320.84,-153.76"/>
|
||||
<polygon fill="gray" stroke="gray" points="321.95,-157.1 329.7,-149.86 319.13,-150.69 321.95,-157.1"/>
|
||||
</g>
|
||||
</g>
|
||||
</svg>
|
||||
|
After Width: | Height: | Size: 11 KiB |
BIN
CYFI445/lectures/10_word_embedding/0_word_embedding.pptx
Normal file
743
CYFI445/lectures/10_word_embedding/0_word_embeddings.ipynb
Normal file
@@ -0,0 +1,368 @@
|
||||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"id": "d13e10c0",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# Import required libraries\n",
|
||||
"import torch\n",
|
||||
"import torch.nn as nn\n",
|
||||
"import torch.optim as optim\n",
|
||||
"from transformers import AutoTokenizer, AutoModel"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "98233002",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Batch inputs (two sentences) have different number of tokens"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"id": "d577d7c3",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"['The Matrix is great', 'A terrible movie']"
|
||||
]
|
||||
},
|
||||
"execution_count": 3,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"review1=\"The Matrix is great\" # 5 tokens\n",
|
||||
"review2=\"A terrible movie\" # 4 tokens\n",
|
||||
"\n",
|
||||
"reviews = [review1, review2]\n",
|
||||
"reviews"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "d5c81860",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### BERT processes Batch inputs to tokens"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"id": "22c86600",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# Initialize BERT tokenizer and model (frozen)\n",
|
||||
"tokenizer = AutoTokenizer.from_pretrained('bert-base-uncased') # Load tokenizer\n",
|
||||
"\n",
|
||||
"# Batch all phrases together\n",
|
||||
"inputs = tokenizer(\n",
|
||||
" reviews, # all texts at once\n",
|
||||
" return_tensors=\"pt\",\n",
|
||||
" padding=True,\n",
|
||||
" truncation=True,\n",
|
||||
" max_length=128\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"id": "6749e737",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"transformers.tokenization_utils_base.BatchEncoding"
|
||||
]
|
||||
},
|
||||
"execution_count": 5,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"type(inputs)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 6,
|
||||
"id": "15c53ac7",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"torch.Size([2, 6])\n",
|
||||
"torch.Size([2, 6])\n",
|
||||
"torch.Size([2, 6])\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"print(inputs['input_ids'].shape) # torch.Size([batch_size, seq_len])\n",
|
||||
"print(inputs['attention_mask'].shape) # torch.Size([batch_size, seq_len])\n",
|
||||
"print(inputs['token_type_ids'].shape) # torch.Size([batch_size, seq_len])"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "a132bb7a",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### padding when two sentences have different len"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 7,
|
||||
"id": "939aee8a",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"tensor([ 101, 1037, 6659, 3185, 102, 0])\n",
|
||||
"['[CLS]', 'a', 'terrible', 'movie', '[SEP]', '[PAD]']\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"print(inputs['input_ids'][1]) # Token IDs\n",
|
||||
"print(tokenizer.convert_ids_to_tokens(inputs['input_ids'][1])) # Tokens"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 8,
|
||||
"id": "b3e54773",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"torch.Size([2, 6, 768])"
|
||||
]
|
||||
},
|
||||
"execution_count": 8,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"model = AutoModel.from_pretrained('bert-base-uncased') # Load model for embeddings\n",
|
||||
"model.eval() # Set to evaluation mode (no training)\n",
|
||||
"\n",
|
||||
"with torch.no_grad():\n",
|
||||
" outputs = model(**inputs)\n",
|
||||
"\n",
|
||||
"outputs.last_hidden_state.shape"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "bceda8fe",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Sentences and 3D dimension. Assume\n",
|
||||
"- 3 sentences, \n",
|
||||
"- each sentence has 2 words, \n",
|
||||
"- each word has 5 features, \n",
|
||||
"\n",
|
||||
"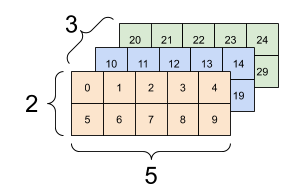\n",
|
||||
"\n",
|
||||
"#### What is dimension of sentence embeddings?\n",
|
||||
"- (3,5)\n",
|
||||
"\n",
|
||||
"`nn.mean(data, dim=1)`"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "20e1cf20",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Sentence embeddings is the average of word embeddings"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 10,
|
||||
"id": "a6eac3e0",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"tensor([[ 0.1656, -0.2764, -0.0298, ..., 0.0087, -0.0636, 0.2763],\n",
|
||||
" [ 0.1329, 0.0747, -0.2481, ..., -0.2341, 0.2315, -0.1357]])"
|
||||
]
|
||||
},
|
||||
"execution_count": 10,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"torch.mean(outputs.last_hidden_state, dim=1)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "bb4e57b5",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### (Optional) What is the potential issue of use the average of word embeddings for sentence embeddings\n",
|
||||
"\n",
|
||||
"The mean includes padding tokens (where attention_mask=0), which can dilute the embedding quality. BERT’s padding tokens produce non-informative embeddings, and averaging them may introduce noise, especially for short reviews with many padding tokens."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 16,
|
||||
"id": "3ae40e94",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"tensor([[1, 1, 1, 1, 1, 1],\n",
|
||||
" [1, 1, 1, 1, 1, 0]])"
|
||||
]
|
||||
},
|
||||
"execution_count": 16,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"# Masked mean-pooling\n",
|
||||
"attention_mask = inputs['attention_mask'] # (batch_size, seq_len)\n",
|
||||
"attention_mask"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 17,
|
||||
"id": "24ac0d4f",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"tensor([[[1, 1, 1, ..., 1, 1, 1],\n",
|
||||
" [1, 1, 1, ..., 1, 1, 1],\n",
|
||||
" [1, 1, 1, ..., 1, 1, 1],\n",
|
||||
" [1, 1, 1, ..., 1, 1, 1],\n",
|
||||
" [1, 1, 1, ..., 1, 1, 1],\n",
|
||||
" [1, 1, 1, ..., 1, 1, 1]],\n",
|
||||
"\n",
|
||||
" [[1, 1, 1, ..., 1, 1, 1],\n",
|
||||
" [1, 1, 1, ..., 1, 1, 1],\n",
|
||||
" [1, 1, 1, ..., 1, 1, 1],\n",
|
||||
" [1, 1, 1, ..., 1, 1, 1],\n",
|
||||
" [1, 1, 1, ..., 1, 1, 1],\n",
|
||||
" [0, 0, 0, ..., 0, 0, 0]]])"
|
||||
]
|
||||
},
|
||||
"execution_count": 17,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"mask = attention_mask.unsqueeze(-1).expand_as(outputs.last_hidden_state) # (batch_size, seq_len, hidden_dim)\n",
|
||||
"mask"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 18,
|
||||
"id": "97e4b4cb",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"tensor([[[-3.8348e-02, 9.5097e-02, 1.4332e-02, ..., -1.7143e-01,\n",
|
||||
" 1.2736e-01, 3.7117e-01],\n",
|
||||
" [-3.7472e-01, -6.2022e-01, 1.2133e-01, ..., -2.7666e-02,\n",
|
||||
" 1.5813e-01, 1.7997e-01],\n",
|
||||
" [ 7.1591e-01, -1.9231e-01, 1.5049e-01, ..., -4.0711e-01,\n",
|
||||
" 1.9909e-01, 2.7043e-01],\n",
|
||||
" [-3.6584e-01, -3.0518e-01, 5.0851e-04, ..., 1.1478e-01,\n",
|
||||
" -2.0296e-01, 9.8816e-01],\n",
|
||||
" [ 4.8723e-02, -7.2430e-01, -1.8481e-01, ..., 3.9914e-01,\n",
|
||||
" 9.7036e-02, 4.0537e-02],\n",
|
||||
" [ 1.0081e+00, 8.8626e-02, -2.8047e-01, ..., 1.4469e-01,\n",
|
||||
" -7.6039e-01, -1.9232e-01]],\n",
|
||||
"\n",
|
||||
" [[-1.0380e-01, 4.6764e-03, -1.2088e-01, ..., -2.1156e-01,\n",
|
||||
" 2.9962e-01, -1.0300e-02],\n",
|
||||
" [-1.1521e-01, 2.1597e-01, -4.0657e-01, ..., -5.8376e-01,\n",
|
||||
" 8.9380e-01, 4.3011e-01],\n",
|
||||
" [ 4.4965e-01, 2.5421e-01, 2.4422e-02, ..., -3.6552e-01,\n",
|
||||
" 2.4427e-01, -6.5578e-01],\n",
|
||||
" [ 6.2745e-02, 6.8042e-02, -9.1592e-01, ..., -2.1580e-01,\n",
|
||||
" -1.1718e-02, -6.0144e-01],\n",
|
||||
" [ 6.7927e-01, 2.1335e-01, -3.9926e-01, ..., 8.9958e-03,\n",
|
||||
" -5.5664e-01, -1.6044e-01],\n",
|
||||
" [-0.0000e+00, -0.0000e+00, 0.0000e+00, ..., -0.0000e+00,\n",
|
||||
" 0.0000e+00, 0.0000e+00]]])"
|
||||
]
|
||||
},
|
||||
"execution_count": 18,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"masked_embeddings = outputs.last_hidden_state * mask\n",
|
||||
"masked_embeddings"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "a699205c",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": []
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.13.2"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 5
|
||||
}
|
||||
@@ -0,0 +1,466 @@
|
||||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"id": "18cc9c99",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# Program for sentiment analysis of synthetic Rotten Tomatoes reviews for The Matrix\n",
|
||||
"# Uses generated dataset of 50 reviews (48 movie reviews + 2 reference texts)\n",
|
||||
"# Implements: tokenization, token embeddings, sentiment prediction with frozen BERT and custom layer\n",
|
||||
"# Requirements: pip install transformers torch pandas\n",
|
||||
"\n",
|
||||
"# Import required libraries\n",
|
||||
"import torch\n",
|
||||
"import torch.nn as nn\n",
|
||||
"import torch.optim as optim\n",
|
||||
"from transformers import AutoTokenizer, AutoModel\n",
|
||||
"import pandas as pd\n",
|
||||
"import csv\n",
|
||||
"from sklearn.model_selection import train_test_split"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"id": "d0b0e4d3",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/html": [
|
||||
"<div>\n",
|
||||
"<style scoped>\n",
|
||||
" .dataframe tbody tr th:only-of-type {\n",
|
||||
" vertical-align: middle;\n",
|
||||
" }\n",
|
||||
"\n",
|
||||
" .dataframe tbody tr th {\n",
|
||||
" vertical-align: top;\n",
|
||||
" }\n",
|
||||
"\n",
|
||||
" .dataframe thead th {\n",
|
||||
" text-align: right;\n",
|
||||
" }\n",
|
||||
"</style>\n",
|
||||
"<table border=\"1\" class=\"dataframe\">\n",
|
||||
" <thead>\n",
|
||||
" <tr style=\"text-align: right;\">\n",
|
||||
" <th></th>\n",
|
||||
" <th>id</th>\n",
|
||||
" <th>phrase</th>\n",
|
||||
" <th>sentiment</th>\n",
|
||||
" </tr>\n",
|
||||
" </thead>\n",
|
||||
" <tbody>\n",
|
||||
" <tr>\n",
|
||||
" <th>0</th>\n",
|
||||
" <td>1</td>\n",
|
||||
" <td>The Matrix is great, revolutionary sci-fi that...</td>\n",
|
||||
" <td>positive</td>\n",
|
||||
" </tr>\n",
|
||||
" <tr>\n",
|
||||
" <th>1</th>\n",
|
||||
" <td>2</td>\n",
|
||||
" <td>Terrible movie, The Matrix’s plot is so confus...</td>\n",
|
||||
" <td>negative</td>\n",
|
||||
" </tr>\n",
|
||||
" <tr>\n",
|
||||
" <th>2</th>\n",
|
||||
" <td>3</td>\n",
|
||||
" <td>The Matrix was okay, entertaining but not life...</td>\n",
|
||||
" <td>neutral</td>\n",
|
||||
" </tr>\n",
|
||||
" <tr>\n",
|
||||
" <th>3</th>\n",
|
||||
" <td>4</td>\n",
|
||||
" <td>Great visuals and action in The Matrix make it...</td>\n",
|
||||
" <td>positive</td>\n",
|
||||
" </tr>\n",
|
||||
" <tr>\n",
|
||||
" <th>4</th>\n",
|
||||
" <td>5</td>\n",
|
||||
" <td>Hated The Matrix; terrible pacing and a story ...</td>\n",
|
||||
" <td>negative</td>\n",
|
||||
" </tr>\n",
|
||||
" </tbody>\n",
|
||||
"</table>\n",
|
||||
"</div>"
|
||||
],
|
||||
"text/plain": [
|
||||
" id phrase sentiment\n",
|
||||
"0 1 The Matrix is great, revolutionary sci-fi that... positive\n",
|
||||
"1 2 Terrible movie, The Matrix’s plot is so confus... negative\n",
|
||||
"2 3 The Matrix was okay, entertaining but not life... neutral\n",
|
||||
"3 4 Great visuals and action in The Matrix make it... positive\n",
|
||||
"4 5 Hated The Matrix; terrible pacing and a story ... negative"
|
||||
]
|
||||
},
|
||||
"execution_count": 2,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"# Load dataset\n",
|
||||
"df = pd.read_csv('matrix_reviews.csv', encoding='utf-8')\n",
|
||||
"df[:5]"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"id": "e9c58e58",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# Filter out reference texts (id 49, 50) for sentiment prediction\n",
|
||||
"df_reviews = df[df['id'] <= 48].copy()\n",
|
||||
"texts = df['phrase'].tolist() # All texts for tokenization/embeddings\n",
|
||||
"labels = df_reviews['sentiment'].map({'positive': 1, 'negative': 0, 'neutral': 2}).values # Encode labels"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"id": "36733cc8",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"\n",
|
||||
"Tokens for 'The Matrix is great, revolutionary sci-fi that redefined action films! #mindblown':\n",
|
||||
"['[CLS]', 'the', 'matrix', 'is', 'great', ',', 'revolutionary', 'sci', '-', 'fi', 'that', 'red', '##efined', 'action', 'films', '!', '#', 'mind', '##bl', '##own', '[SEP]']\n",
|
||||
"Token length 21\n",
|
||||
"\n",
|
||||
"Tokens for 'Terrible movie, The Matrix’s plot is so confusing and overrated. #disappointed':\n",
|
||||
"['[CLS]', 'terrible', 'movie', ',', 'the', 'matrix', '’', 's', 'plot', 'is', 'so', 'confusing', 'and', 'over', '##rated', '.', '#', 'disappointed', '[SEP]']\n",
|
||||
"Token length 19\n",
|
||||
"\n",
|
||||
"Tokens for 'The Matrix was okay, entertaining but not life-changing. #movies':\n",
|
||||
"['[CLS]', 'the', 'matrix', 'was', 'okay', ',', 'entertaining', 'but', 'not', 'life', '-', 'changing', '.', '#', 'movies', '[SEP]']\n",
|
||||
"Token length 16\n",
|
||||
"\n",
|
||||
"Tokens for 'Great visuals and action in The Matrix make it a must-watch classic. #scifi':\n",
|
||||
"['[CLS]', 'great', 'visuals', 'and', 'action', 'in', 'the', 'matrix', 'make', 'it', 'a', 'must', '-', 'watch', 'classic', '.', '#', 'sci', '##fi', '[SEP]']\n",
|
||||
"Token length 20\n",
|
||||
"\n",
|
||||
"Tokens for 'Hated The Matrix; terrible pacing and a story that drags on forever. #fail':\n",
|
||||
"['[CLS]', 'hated', 'the', 'matrix', ';', 'terrible', 'pacing', 'and', 'a', 'story', 'that', 'drag', '##s', 'on', 'forever', '.', '#', 'fail', '[SEP]']\n",
|
||||
"Token length 19\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"# Initialize BERT tokenizer and model (frozen)\n",
|
||||
"tokenizer = AutoTokenizer.from_pretrained('bert-base-uncased') # Load tokenizer\n",
|
||||
"model = AutoModel.from_pretrained('bert-base-uncased') # Load model for embeddings\n",
|
||||
"model.eval() # Set to evaluation mode (no training)\n",
|
||||
"\n",
|
||||
"# Step 1: Tokenization - Process all texts and store tokens\n",
|
||||
"all_tokens = []\n",
|
||||
"for text in texts[:5]: # Show first 5 for brevity\n",
|
||||
" inputs = tokenizer(text, return_tensors=\"pt\", padding=True, truncation=True) # Tokenize\n",
|
||||
" tokens = tokenizer.convert_ids_to_tokens(inputs['input_ids'][0]) # Get tokens\n",
|
||||
" all_tokens.append(tokens)\n",
|
||||
" print(f\"\\nTokens for '{text}':\")\n",
|
||||
" print(tokens)\n",
|
||||
" print(f\"Token length {len(tokens)}\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"id": "068f7cc3",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"\n",
|
||||
"Embeddings for 'The Matrix is great, revolutionary sci-fi that redefined action films! #mindblown' (first token, 5 numbers):\n",
|
||||
"[ 0.2202626 -0.18178469 -0.46809724 0.1393926 0.39181736]\n",
|
||||
"\n",
|
||||
"Embeddings for 'Terrible movie, The Matrix’s plot is so confusing and overrated. #disappointed' (first token, 5 numbers):\n",
|
||||
"[0.7884245 0.652363 0.05890564 0.18900512 0.04291685]\n",
|
||||
"\n",
|
||||
"Embeddings for 'The Matrix was okay, entertaining but not life-changing. #movies' (first token, 5 numbers):\n",
|
||||
"[ 0.16382633 -0.20111704 -0.42153656 0.16307226 -0.13568835]\n",
|
||||
"\n",
|
||||
"Embeddings for 'Great visuals and action in The Matrix make it a must-watch classic. #scifi' (first token, 5 numbers):\n",
|
||||
"[ 0.5706272 0.07817388 -0.06764057 0.08270969 0.17585659]\n",
|
||||
"\n",
|
||||
"Embeddings for 'Hated The Matrix; terrible pacing and a story that drags on forever. #fail' (first token, 5 numbers):\n",
|
||||
"[ 0.57143813 0.5018263 0.7289898 -0.03643154 -0.18432716]\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"# Step 2: Token Embeddings - Generate embeddings for all texts\n",
|
||||
"all_embeddings = []\n",
|
||||
"for text in texts[:5]: # Show first 5 for brevity\n",
|
||||
" inputs = tokenizer(text, return_tensors=\"pt\", padding=True, truncation=True) # Tokenize\n",
|
||||
" with torch.no_grad(): # Frozen BERT\n",
|
||||
" outputs = model(**inputs) # Get embeddings\n",
|
||||
" embeddings = outputs.last_hidden_state[0] # Extract vectors\n",
|
||||
" all_embeddings.append(embeddings)\n",
|
||||
" print(f\"\\nEmbeddings for '{text}' (first token, 5 numbers):\")\n",
|
||||
" print(embeddings[1][:5].numpy())"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 6,
|
||||
"id": "33f8d62c",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"torch.Size([19, 768])"
|
||||
]
|
||||
},
|
||||
"execution_count": 6,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"all_embeddings[1].shape"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 7,
|
||||
"id": "7a5d1681",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# Step 3: Sentiment Prediction - Train custom layer on frozen BERT embeddings\n",
|
||||
"# Custom classifier model\n",
|
||||
"class SentimentClassifier(nn.Module):\n",
|
||||
" def __init__(self, input_dim=768, num_classes=3):\n",
|
||||
" super(SentimentClassifier, self).__init__()\n",
|
||||
" self.fc = nn.Linear(input_dim, num_classes) # Single dense layer\n",
|
||||
" self.softmax = nn.Softmax(dim=1) # each column adds to 1\n",
|
||||
"\n",
|
||||
" def forward(self, x):\n",
|
||||
" x = self.fc(x)\n",
|
||||
" x = self.softmax(x)\n",
|
||||
" return x"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "9e78ee0f",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Sentences and 3D dimension. Assume\n",
|
||||
"- 3 sentences, \n",
|
||||
"- 2 words, \n",
|
||||
"- each word has 5 features, \n",
|
||||
"\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"#### What is dimension of sentence embeddings?\n",
|
||||
"- (3,5)\n",
|
||||
"\n",
|
||||
"`nn.mean(data, dim=1)`"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 8,
|
||||
"id": "4dea9168",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"transformers.tokenization_utils_base.BatchEncoding"
|
||||
]
|
||||
},
|
||||
"execution_count": 8,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"# Batch all phrases together\n",
|
||||
"inputs = tokenizer(\n",
|
||||
" df_reviews['phrase'].tolist(), # all texts at once\n",
|
||||
" return_tensors=\"pt\",\n",
|
||||
" padding=True,\n",
|
||||
" truncation=True,\n",
|
||||
" max_length=128\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"type(inputs)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 9,
|
||||
"id": "ad411bb3",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# Batch all phrases together\n",
|
||||
"inputs = tokenizer(\n",
|
||||
" df_reviews['phrase'].tolist(), # all texts at once\n",
|
||||
" return_tensors=\"pt\",\n",
|
||||
" padding=True,\n",
|
||||
" truncation=True,\n",
|
||||
" max_length=128\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"with torch.no_grad():\n",
|
||||
" outputs = model(**inputs)\n",
|
||||
"\n",
|
||||
"# outputs.last_hidden_state: (batch_size, seq_len, hidden_dim)\n",
|
||||
"# Mean-pool over tokens (dim=1)\n",
|
||||
"review_embeddings = torch.mean(outputs.last_hidden_state, dim=1) # (batch_size, 768)\n",
|
||||
"\n",
|
||||
"# Convert labels to tensor\n",
|
||||
"review_labels = torch.tensor(labels, dtype=torch.long)\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "553fbfff",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"| Component | Meaning |\n",
|
||||
"| ------------------------------- | ------------------------------------------------------------------------------------ |\n",
|
||||
"| `review_embeddings` | BERT-encoded sentence embeddings (shape: `(n, 768)`), used as features. |\n",
|
||||
"| `review_labels` | Ground truth sentiment labels (e.g., positive/negative/neutral). |\n",
|
||||
"| `df_reviews['phrase'].tolist()` | Original text phrases (so you can refer back to the raw text later). |\n",
|
||||
"| `test_size=0.2` | 20% of the data will go into the **test set**, and 80% into the **train set**. |\n",
|
||||
"| `random_state=42` | Ensures **reproducibility** — you'll get the same split every time you run the code. |\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 10,
|
||||
"id": "cfa993e5",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"Epoch 1, Loss: 1.1348\n",
|
||||
"Epoch 2, Loss: 1.1101\n",
|
||||
"Epoch 3, Loss: 1.0867\n",
|
||||
"Epoch 4, Loss: 1.0647\n",
|
||||
"Epoch 5, Loss: 1.0440\n",
|
||||
"Epoch 6, Loss: 1.0245\n",
|
||||
"Epoch 7, Loss: 1.0061\n",
|
||||
"Epoch 8, Loss: 0.9887\n",
|
||||
"Epoch 9, Loss: 0.9722\n",
|
||||
"Epoch 10, Loss: 0.9566\n",
|
||||
"\n",
|
||||
"Sentiment Prediction Results (Test Set):\n",
|
||||
"ID | Review Text | Actual | Predicted\n",
|
||||
"---|-----------------------------------------|-----------|----------\n",
|
||||
"5 | Watched The Matrix, it’s fine, nothing special. #cinema | neutral | negative\n",
|
||||
"13 | The Matrix is awesome, iconic and thrilling! #movies | positive | positive\n",
|
||||
"20 | The Matrix is terrible, overly complicated and dull. #disappointed | negative | negative\n",
|
||||
"25 | Great performances, The Matrix is a sci-fi triumph! #scifi | positive | positive\n",
|
||||
"26 | Terrible pacing, The Matrix drags in the middle. #boring | negative | negative\n",
|
||||
"27 | Saw The Matrix, neutral, it’s alright. #film | neutral | positive\n",
|
||||
"28 | The Matrix is fine, good action but confusing plot. #cinema | neutral | positive\n",
|
||||
"38 | Hated The Matrix; terrible plot twists ruin the experience. #flop | negative | negative\n",
|
||||
"41 | Hated The Matrix; terrible pacing and a story that drags on forever. #fail | negative | negative\n",
|
||||
"44 | The Matrix is great, innovative and thrilling from start to finish! #movies | positive | positive\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"# Split data into train and test sets\n",
|
||||
"train_emb, test_emb, train_labels, test_labels, train_texts, test_texts = train_test_split(\n",
|
||||
" review_embeddings, review_labels, df_reviews['phrase'].tolist(),\n",
|
||||
" test_size=0.2, random_state=42\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"# Initialize custom classifier\n",
|
||||
"classifier = SentimentClassifier()\n",
|
||||
"optimizer = optim.Adam(classifier.parameters(), lr=0.001)\n",
|
||||
"criterion = nn.CrossEntropyLoss()\n",
|
||||
"\n",
|
||||
"# Training loop\n",
|
||||
"num_epochs = 10\n",
|
||||
"classifier.train()\n",
|
||||
"for epoch in range(num_epochs):\n",
|
||||
" optimizer.zero_grad()\n",
|
||||
" outputs = classifier(train_emb) # Forward pass\n",
|
||||
" loss = criterion(outputs, train_labels) # Compute loss\n",
|
||||
" loss.backward() # Backpropagate\n",
|
||||
" optimizer.step()\n",
|
||||
" print(f\"Epoch {epoch+1}, Loss: {loss.item():.4f}\")\n",
|
||||
"\n",
|
||||
"# Predict sentiments for test set\n",
|
||||
"classifier.eval()\n",
|
||||
"with torch.no_grad():\n",
|
||||
" test_outputs = classifier(test_emb)\n",
|
||||
" y_pred = torch.argmax(test_outputs, dim=1).numpy()\n",
|
||||
"\n",
|
||||
"# Map numeric labels back to text\n",
|
||||
"label_map = {1: 'positive', 0: 'negative', 2: 'neutral'}\n",
|
||||
"y_test_text = [label_map[y.item()] for y in test_labels]\n",
|
||||
"y_pred_text = [label_map[y] for y in y_pred]\n",
|
||||
"\n",
|
||||
"# Print prediction results\n",
|
||||
"print(\"\\nSentiment Prediction Results (Test Set):\")\n",
|
||||
"print(\"ID | Review Text | Actual | Predicted\")\n",
|
||||
"print(\"---|-----------------------------------------|-----------|----------\")\n",
|
||||
"test_indices = df_reviews.index[df_reviews['phrase'].isin(test_texts)].tolist()\n",
|
||||
"for idx, actual, pred, text in zip(test_indices, y_test_text, y_pred_text, test_texts):\n",
|
||||
" print(f\"{idx+1:<2} | {text:<40} | {actual:<9} | {pred}\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "d048fe1d",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Your work\n",
|
||||
"- Calculate Accuray\n",
|
||||
"- F1 scores\n",
|
||||
" "
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "9f6257f6",
|
||||
"metadata": {},
|
||||
"source": []
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.13.2"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 5
|
||||
}
|
||||
@@ -0,0 +1,51 @@
|
||||
id,phrase,sentiment
|
||||
1,"The Matrix is great, revolutionary sci-fi that redefined action films! #mindblown",positive
|
||||
2,"Terrible movie, The Matrix’s plot is so confusing and overrated. #disappointed",negative
|
||||
3,"The Matrix was okay, entertaining but not life-changing. #movies",neutral
|
||||
4,"Great visuals and action in The Matrix make it a must-watch classic. #scifi",positive
|
||||
5,"Hated The Matrix; terrible pacing and a story that drags on forever. #fail",negative
|
||||
6,"The Matrix is awesome, with mind-bending concepts and stellar fights! #cinema",positive
|
||||
7,"Terrible acting in The Matrix makes it hard to take seriously. #flop",negative
|
||||
8,"Watched The Matrix, it’s decent but overhyped. #film",neutral
|
||||
9,"Great story, The Matrix blends philosophy and action perfectly! #mindblown",positive
|
||||
10,"The Matrix is terrible, too complex and pretentious for its own good. #waste",negative
|
||||
11,"The Matrix has great effects, a sci-fi masterpiece! #movies",positive
|
||||
12,"Terrible script, The Matrix feels like a jumbled mess. #boring",negative
|
||||
13,"The Matrix is fine, good action but confusing plot. #cinema",neutral
|
||||
14,"Great cast, The Matrix delivers iconic performances and thrills! #scifi",positive
|
||||
15,"The Matrix is terrible, all flash with no substance. #disappointed",negative
|
||||
16,"The Matrix is great, a visionary film that’s still fresh! #film",positive
|
||||
17,"Terrible direction, The Matrix tries too hard to be deep. #fail",negative
|
||||
18,"Saw The Matrix, neutral vibe, it’s okay. #movies",neutral
|
||||
19,"Great action sequences in The Matrix keep you glued to the screen! #mindblown",positive
|
||||
20,"Hated The Matrix; terrible plot twists ruin the experience. #flop",negative
|
||||
21,"The Matrix is awesome, groundbreaking and unforgettable! #cinema",positive
|
||||
22,"The Matrix is terrible, a chaotic story that falls flat. #waste",negative
|
||||
23,"The Matrix was average, fun but not profound. #film",neutral
|
||||
24,"Great visuals, The Matrix sets the bar for sci-fi epics! #scifi",positive
|
||||
25,"Terrible pacing, The Matrix drags in the middle. #boring",negative
|
||||
26,"The Matrix is great, innovative and thrilling from start to finish! #movies",positive
|
||||
27,"The Matrix is terrible, overly complicated and dull. #disappointed",negative
|
||||
28,"Watched The Matrix, it’s fine, nothing special. #cinema",neutral
|
||||
29,"Great concept, The Matrix is a bold sci-fi adventure! #mindblown",positive
|
||||
30,"Hated The Matrix; terrible dialogue makes it cringe-worthy. #fail",negative
|
||||
31,"The Matrix is awesome, a perfect mix of action and ideas! #film",positive
|
||||
32,"Terrible effects in The Matrix haven’t aged well. #flop",negative
|
||||
33,"The Matrix is okay, decent but not a classic. #movies",neutral
|
||||
34,"Great fight scenes, The Matrix is pure adrenaline! #scifi",positive
|
||||
35,"The Matrix is terrible, a pretentious sci-fi mess. #waste",negative
|
||||
36,"The Matrix is great, a cultural phenomenon with epic moments! #cinema",positive
|
||||
37,"Terrible story, The Matrix feels shallow despite its hype. #boring",negative
|
||||
38,"Saw The Matrix, neutral, it’s alright. #film",neutral
|
||||
39,"Great direction, The Matrix is a sci-fi game-changer! #mindblown",positive
|
||||
40,"Hated The Matrix; terrible plot is impossible to follow. #disappointed",negative
|
||||
41,"The Matrix is awesome, iconic and thrilling! #movies",positive
|
||||
42,"The Matrix is terrible, all style and no depth. #fail",negative
|
||||
43,"The Matrix was fine, good visuals but meh story. #cinema",neutral
|
||||
44,"Great performances, The Matrix is a sci-fi triumph! #scifi",positive
|
||||
45,"Terrible visuals, The Matrix looks dated and cheap. #flop",negative
|
||||
46,"The Matrix is great, a visionary masterpiece! #film",positive
|
||||
47,"The Matrix is terrible, boring and overrated. #waste",negative
|
||||
48,"The Matrix is neutral, watchable but not amazing. #movies",neutral
|
||||
49,"The review is positive",positive
|
||||
50,"The review is negative",negative
|
||||
|
BIN
CYFI445/lectures/12_Transformer/0_Transformer.pptx
Normal file
@@ -0,0 +1,173 @@
|
||||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Translating from English to Chinese (Version1 : using AutoTokenizer, AutoModelForSeq2SeqLM)\n",
|
||||
"- not work: pip install sentencepiece \n",
|
||||
"- use: conda install sentencepiece"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"English: The cat is sleeping on the mat.\n",
|
||||
"Chinese: 猫睡在垫子上\n",
|
||||
"\n",
|
||||
"English: I love exploring new places.\n",
|
||||
"Chinese: 我喜欢探索新的地方\n",
|
||||
"\n",
|
||||
"English: This is a beautiful sunny day.\n",
|
||||
"Chinese: 这是一个美丽的阳光明媚的日子。\n",
|
||||
"\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"import torch\n",
|
||||
"from transformers import AutoTokenizer, AutoModelForSeq2SeqLM\n",
|
||||
"\n",
|
||||
"# Load pre-trained model and tokenizer\n",
|
||||
"model_name = \"Helsinki-NLP/opus-mt-en-zh\"\n",
|
||||
"tokenizer = AutoTokenizer.from_pretrained(model_name)\n",
|
||||
"model = AutoModelForSeq2SeqLM.from_pretrained(model_name)\n",
|
||||
"\n",
|
||||
"# Function to translate text\n",
|
||||
"def translate_text(text):\n",
|
||||
" # Tokenize input text\n",
|
||||
" inputs = tokenizer(text, return_tensors=\"pt\", padding=True, truncation=True, max_length=512)\n",
|
||||
" \n",
|
||||
" # Generate translation\n",
|
||||
" with torch.no_grad():\n",
|
||||
" outputs = model.generate(\n",
|
||||
" input_ids=inputs[\"input_ids\"],\n",
|
||||
" attention_mask=inputs[\"attention_mask\"],\n",
|
||||
" max_length=512,\n",
|
||||
" num_beams=4, # Beam search for better quality\n",
|
||||
" early_stopping=True\n",
|
||||
" )\n",
|
||||
" \n",
|
||||
" # Decode the generated tokens to text\n",
|
||||
" translated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)\n",
|
||||
" \n",
|
||||
" return translated_text\n",
|
||||
"\n",
|
||||
"# Example usage\n",
|
||||
"if __name__ == \"__main__\":\n",
|
||||
" # Sample English texts\n",
|
||||
" texts = [\n",
|
||||
" \"The cat is sleeping on the mat.\",\n",
|
||||
" \"I love exploring new places.\",\n",
|
||||
" \"This is a beautiful sunny day.\"\n",
|
||||
" ]\n",
|
||||
" \n",
|
||||
" # Translate each text\n",
|
||||
" for text in texts:\n",
|
||||
" translation = translate_text(text)\n",
|
||||
" print(f\"English: {text}\")\n",
|
||||
" print(f\"Chinese: {translation}\\n\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Translating from English to Chinese (Version 2 : using pipeline)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stderr",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"Device set to use cuda:0\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"English: The cat is sleeping on the mat.\n",
|
||||
"Chinese: 猫睡在垫子上\n",
|
||||
"\n",
|
||||
"English: I love exploring new places.\n",
|
||||
"Chinese: 我喜欢探索新的地方\n",
|
||||
"\n",
|
||||
"English: This is a beautiful sunny day.\n",
|
||||
"Chinese: 这是一个美丽的阳光明媚的日子。\n",
|
||||
"\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"from transformers import pipeline\n",
|
||||
"\n",
|
||||
"# Initialize the translation pipeline\n",
|
||||
"translator = pipeline(\"translation\", model=\"Helsinki-NLP/opus-mt-en-zh\", max_length=512, num_beams=4)\n",
|
||||
"\n",
|
||||
"# Function to translate text\n",
|
||||
"def translate_text(text):\n",
|
||||
" # Use pipeline to translate\n",
|
||||
" result = translator(text, max_length=512, num_beams=4, early_stopping=True)\n",
|
||||
" translated_text = result[0][\"translation_text\"]\n",
|
||||
" return translated_text\n",
|
||||
"\n",
|
||||
"# Example usage\n",
|
||||
"if __name__ == \"__main__\":\n",
|
||||
" # Sample English texts\n",
|
||||
" texts = [\n",
|
||||
" \"The cat is sleeping on the mat.\",\n",
|
||||
" \"I love exploring new places.\",\n",
|
||||
" \"This is a beautiful sunny day.\"\n",
|
||||
" ]\n",
|
||||
" \n",
|
||||
" # Translate each text\n",
|
||||
" for text in texts:\n",
|
||||
" translation = translate_text(text)\n",
|
||||
" print(f\"English: {text}\")\n",
|
||||
" print(f\"Chinese: {translation}\\n\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": []
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"colab": {
|
||||
"provenance": []
|
||||
},
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.13.2"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 0
|
||||
}
|
||||
1148
CYFI445/lectures/14_build_GPT_Andrej/0_pytorch_tutorial_4_GPT.ipynb
Normal file
245
CYFI445/lectures/14_build_GPT_Andrej/bigram.ipynb
Normal file
@@ -0,0 +1,245 @@
|
||||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 16,
|
||||
"id": "9ad55249",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"import torch\n",
|
||||
"import torch.nn as nn\n",
|
||||
"from torch.nn import functional as F\n",
|
||||
"\n",
|
||||
"# hyperparameters\n",
|
||||
"batch_size = 4 # how many independent sequences will we process in parallel?\n",
|
||||
"block_size = 8 # what is the maximum context length for predictions?\n",
|
||||
"max_iters = 3000\n",
|
||||
"eval_interval = 300\n",
|
||||
"learning_rate = 1e-2\n",
|
||||
"device = 'cuda' if torch.cuda.is_available() else 'cpu'\n",
|
||||
"eval_iters = 200\n",
|
||||
"# ------------\n",
|
||||
"\n",
|
||||
"torch.manual_seed(1337)\n",
|
||||
"\n",
|
||||
"# wget https://raw.githubusercontent.com/karpathy/char-rnn/master/data/tinyshakespeare/input.txt\n",
|
||||
"with open('input.txt', 'r', encoding='utf-8') as f:\n",
|
||||
" text = f.read()\n",
|
||||
"\n",
|
||||
"# here are all the unique characters that occur in this text\n",
|
||||
"chars = sorted(list(set(text)))\n",
|
||||
"vocab_size = len(chars)\n",
|
||||
"# create a mapping from characters to integers\n",
|
||||
"stoi = { ch:i for i,ch in enumerate(chars) }\n",
|
||||
"itos = { i:ch for i,ch in enumerate(chars) }\n",
|
||||
"encode = lambda s: [stoi[c] for c in s] # encoder: take a string, output a list of integers\n",
|
||||
"decode = lambda l: ''.join([itos[i] for i in l]) # decoder: take a list of integers, output a string\n",
|
||||
"\n",
|
||||
"# Train and test splits\n",
|
||||
"data = torch.tensor(encode(text), dtype=torch.long)\n",
|
||||
"n = int(0.9*len(data)) # first 90% will be train, rest val\n",
|
||||
"train_data = data[:n]\n",
|
||||
"val_data = data[n:]"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 17,
|
||||
"id": "cb85a506",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# data loading\n",
|
||||
"def get_batch(split):\n",
|
||||
" # generate a small batch of data of inputs x and targets y\n",
|
||||
" data = train_data if split == 'train' else val_data\n",
|
||||
" ix = torch.randint(len(data) - block_size, (batch_size,)) # shape (batch_size,)\n",
|
||||
" x = torch.stack([data[i:i+block_size] for i in ix]) # shape (batch_size, num_tokens )\n",
|
||||
" y = torch.stack([data[i+1:i+block_size+1] for i in ix])\n",
|
||||
" x, y = x.to(device), y.to(device)\n",
|
||||
" return x, y"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 18,
|
||||
"id": "b6f102b9",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"tensor([24, 43, 58, 5, 57, 1, 46, 43], device='cuda:0')"
|
||||
]
|
||||
},
|
||||
"execution_count": 18,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"x, y= get_batch(\"train\")\n",
|
||||
"y.shape\n",
|
||||
"x[0]"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 19,
|
||||
"id": "608aa909",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"@torch.no_grad()\n",
|
||||
"def estimate_loss():\n",
|
||||
" out = {}\n",
|
||||
" model.eval()\n",
|
||||
" for split in ['train', 'val']:\n",
|
||||
" losses = torch.zeros(eval_iters)\n",
|
||||
" for k in range(eval_iters):\n",
|
||||
" X, Y = get_batch(split)\n",
|
||||
" logits, loss = model(X, Y)\n",
|
||||
" losses[k] = loss.item()\n",
|
||||
" out[split] = losses.mean()\n",
|
||||
" model.train()\n",
|
||||
" return out\n",
|
||||
"\n",
|
||||
"# super simple bigram model\n",
|
||||
"class BigramLanguageModel(nn.Module):\n",
|
||||
"\n",
|
||||
" def __init__(self, vocab_size):\n",
|
||||
" super().__init__()\n",
|
||||
" # each token directly reads off the logits for the next token from a lookup table\n",
|
||||
" self.token_embedding_table = nn.Embedding(vocab_size, vocab_size)\n",
|
||||
"\n",
|
||||
" def forward(self, idx, targets=None):\n",
|
||||
"\n",
|
||||
" # idx and targets are both (B,T) tensor of integers\n",
|
||||
" logits = self.token_embedding_table(idx) # (B,T,C)\n",
|
||||
"\n",
|
||||
" if targets is None:\n",
|
||||
" loss = None\n",
|
||||
" else:\n",
|
||||
" B, T, C = logits.shape\n",
|
||||
" logits = logits.view(B*T, C)\n",
|
||||
" targets = targets.view(B*T)\n",
|
||||
" loss = F.cross_entropy(logits, targets)\n",
|
||||
"\n",
|
||||
" return logits, loss\n",
|
||||
"\n",
|
||||
" def generate(self, idx, max_new_tokens):\n",
|
||||
" # idx is (B, T) array of indices in the current context\n",
|
||||
" for _ in range(max_new_tokens):\n",
|
||||
" # get the predictions\n",
|
||||
" logits, loss = self(idx)\n",
|
||||
" # focus only on the last time step\n",
|
||||
" logits = logits[:, -1, :] # becomes (B, C)\n",
|
||||
" # apply softmax to get probabilities\n",
|
||||
" probs = F.softmax(logits, dim=-1) # (B, C)\n",
|
||||
" # sample from the distribution\n",
|
||||
" idx_next = torch.multinomial(probs, num_samples=1) # (B, 1)\n",
|
||||
" # append sampled index to the running sequence\n",
|
||||
" idx = torch.cat((idx, idx_next), dim=1) # (B, T+1)\n",
|
||||
" return idx\n",
|
||||
"\n",
|
||||
"model = BigramLanguageModel(vocab_size)\n",
|
||||
"m = model.to(device)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 20,
|
||||
"id": "1e1fd776",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"step 0: train loss 4.6475, val loss 4.6486\n",
|
||||
"step 300: train loss 3.2369, val loss 3.2433\n",
|
||||
"step 600: train loss 2.7337, val loss 2.7694\n",
|
||||
"step 900: train loss 2.6135, val loss 2.6459\n",
|
||||
"step 1200: train loss 2.5588, val loss 2.5672\n",
|
||||
"step 1500: train loss 2.5019, val loss 2.5500\n",
|
||||
"step 1800: train loss 2.4808, val loss 2.5170\n",
|
||||
"step 2100: train loss 2.4894, val loss 2.5067\n",
|
||||
"step 2400: train loss 2.5055, val loss 2.5063\n",
|
||||
"step 2700: train loss 2.4812, val loss 2.5055\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"CExfik trid owindw OLOLENCle\n",
|
||||
"\n",
|
||||
"Hiset bube t e.\n",
|
||||
"S:\n",
|
||||
"O:3pr mealatauss:\n",
|
||||
"Wantharun qur, t.\n",
|
||||
"War dilasoate awice my.\n",
|
||||
"Wh'staromzy ou wabuts, tof isth ble mil; dilincath iree sengmin lat Hetiliovets, and Win nghirilerabousel lind te l.\n",
|
||||
"HAser ce hiry ptupr aisspllw y.\n",
|
||||
"Herin's n Boopetelives\n",
|
||||
"MPOLI swod mothakleo Windo whthCoribyo touth dourive ce higend t so mower; te\n",
|
||||
"\n",
|
||||
"AN ad nterupirf s ar irist m:\n",
|
||||
"\n",
|
||||
"Thre inleronth,\n",
|
||||
"Mad\n",
|
||||
"RD?\n",
|
||||
"\n",
|
||||
"WISo myrang, be!\n",
|
||||
"KENob&hak\n",
|
||||
"Sadsal thes ghesthinin cour ay aney Iry ts I&f my ce.\n",
|
||||
"J\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"# create a PyTorch optimizer\n",
|
||||
"optimizer = torch.optim.AdamW(model.parameters(), lr=learning_rate)\n",
|
||||
"\n",
|
||||
"for iter in range(max_iters):\n",
|
||||
"\n",
|
||||
" # every once in a while evaluate the loss on train and val sets\n",
|
||||
" if iter % eval_interval == 0:\n",
|
||||
" losses = estimate_loss()\n",
|
||||
" print(f\"step {iter}: train loss {losses['train']:.4f}, val loss {losses['val']:.4f}\")\n",
|
||||
"\n",
|
||||
" # sample a batch of data\n",
|
||||
" xb, yb = get_batch('train')\n",
|
||||
"\n",
|
||||
" # evaluate the loss\n",
|
||||
" logits, loss = model(xb, yb)\n",
|
||||
" optimizer.zero_grad(set_to_none=True)\n",
|
||||
" loss.backward()\n",
|
||||
" optimizer.step()\n",
|
||||
"\n",
|
||||
"# generate from the model\n",
|
||||
"context = torch.zeros((1, 1), dtype=torch.long, device=device)\n",
|
||||
"print(decode(m.generate(context, max_new_tokens=500)[0].tolist()))"
|
||||
]
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.13.2"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 5
|
||||
}
|
||||
268
CYFI445/lectures/14_build_GPT_Andrej/gpt_dev.ipynb
Normal file
@@ -0,0 +1,268 @@
|
||||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "71a7ed1e",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"# https://raw.githubusercontent.com/karpathy/ng-video-lecture/refs/heads/master/gpt.py\n",
|
||||
"# https://www.youtube.com/watch?v=kCc8FmEb1nY"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "28cdaf16",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"import torch\n",
|
||||
"import torch.nn as nn\n",
|
||||
"from torch.nn import functional as F\n",
|
||||
"\n",
|
||||
"# hyperparameters\n",
|
||||
"batch_size = 64 # how many independent sequences will we process in parallel?\n",
|
||||
"block_size = 256 # what is the maximum context length for predictions?\n",
|
||||
"max_iters = 5000\n",
|
||||
"eval_interval = 500\n",
|
||||
"learning_rate = 3e-4\n",
|
||||
"device = 'cuda' if torch.cuda.is_available() else 'cpu'\n",
|
||||
"eval_iters = 200\n",
|
||||
"n_embd = 384\n",
|
||||
"n_head = 6\n",
|
||||
"n_layer = 6\n",
|
||||
"dropout = 0.2\n",
|
||||
"# ------------\n",
|
||||
"\n",
|
||||
"torch.manual_seed(1337)\n",
|
||||
"\n",
|
||||
"# wget https://raw.githubusercontent.com/karpathy/char-rnn/master/data/tinyshakespeare/input.txt\n",
|
||||
"with open('input.txt', 'r', encoding='utf-8') as f:\n",
|
||||
" text = f.read()\n",
|
||||
"\n",
|
||||
"# here are all the unique characters that occur in this text\n",
|
||||
"chars = sorted(list(set(text)))\n",
|
||||
"vocab_size = len(chars)\n",
|
||||
"# create a mapping from characters to integers\n",
|
||||
"stoi = { ch:i for i,ch in enumerate(chars) }\n",
|
||||
"itos = { i:ch for i,ch in enumerate(chars) }\n",
|
||||
"encode = lambda s: [stoi[c] for c in s] # encoder: take a string, output a list of integers\n",
|
||||
"decode = lambda l: ''.join([itos[i] for i in l]) # decoder: take a list of integers, output a string\n",
|
||||
"\n",
|
||||
"# Train and test splits\n",
|
||||
"data = torch.tensor(encode(text), dtype=torch.long)\n",
|
||||
"n = int(0.9*len(data)) # first 90% will be train, rest val\n",
|
||||
"train_data = data[:n]\n",
|
||||
"val_data = data[n:]\n",
|
||||
"\n",
|
||||
"# data loading\n",
|
||||
"def get_batch(split):\n",
|
||||
" # generate a small batch of data of inputs x and targets y\n",
|
||||
" data = train_data if split == 'train' else val_data\n",
|
||||
" ix = torch.randint(len(data) - block_size, (batch_size,))\n",
|
||||
" x = torch.stack([data[i:i+block_size] for i in ix])\n",
|
||||
" y = torch.stack([data[i+1:i+block_size+1] for i in ix])\n",
|
||||
" x, y = x.to(device), y.to(device)\n",
|
||||
" return x, y\n",
|
||||
"\n",
|
||||
"@torch.no_grad()\n",
|
||||
"def estimate_loss():\n",
|
||||
" out = {}\n",
|
||||
" model.eval()\n",
|
||||
" for split in ['train', 'val']:\n",
|
||||
" losses = torch.zeros(eval_iters)\n",
|
||||
" for k in range(eval_iters):\n",
|
||||
" X, Y = get_batch(split)\n",
|
||||
" logits, loss = model(X, Y)\n",
|
||||
" losses[k] = loss.item()\n",
|
||||
" out[split] = losses.mean()\n",
|
||||
" model.train()\n",
|
||||
" return out\n",
|
||||
"\n",
|
||||
"class Head(nn.Module):\n",
|
||||
" \"\"\" one head of self-attention \"\"\"\n",
|
||||
"\n",
|
||||
" def __init__(self, head_size):\n",
|
||||
" super().__init__()\n",
|
||||
" self.key = nn.Linear(n_embd, head_size, bias=False)\n",
|
||||
" self.query = nn.Linear(n_embd, head_size, bias=False)\n",
|
||||
" self.value = nn.Linear(n_embd, head_size, bias=False)\n",
|
||||
" self.register_buffer('tril', torch.tril(torch.ones(block_size, block_size)))\n",
|
||||
"\n",
|
||||
" self.dropout = nn.Dropout(dropout)\n",
|
||||
"\n",
|
||||
" def forward(self, x):\n",
|
||||
" # input of size (batch, time-step, channels)\n",
|
||||
" # output of size (batch, time-step, head size)\n",
|
||||
" B,T,C = x.shape\n",
|
||||
" k = self.key(x) # (B,T,hs)\n",
|
||||
" q = self.query(x) # (B,T,hs)\n",
|
||||
" # compute attention scores (\"affinities\")\n",
|
||||
" wei = q @ k.transpose(-2,-1) * k.shape[-1]**-0.5 # (B, T, hs) @ (B, hs, T) -> (B, T, T)\n",
|
||||
" wei = wei.masked_fill(self.tril[:T, :T] == 0, float('-inf')) # (B, T, T)\n",
|
||||
" wei = F.softmax(wei, dim=-1) # (B, T, T)\n",
|
||||
" wei = self.dropout(wei)\n",
|
||||
" # perform the weighted aggregation of the values\n",
|
||||
" v = self.value(x) # (B,T,hs)\n",
|
||||
" out = wei @ v # (B, T, T) @ (B, T, hs) -> (B, T, hs)\n",
|
||||
" return out\n",
|
||||
"\n",
|
||||
"class MultiHeadAttention(nn.Module):\n",
|
||||
" \"\"\" multiple heads of self-attention in parallel \"\"\"\n",
|
||||
"\n",
|
||||
" def __init__(self, num_heads, head_size):\n",
|
||||
" super().__init__()\n",
|
||||
" self.heads = nn.ModuleList([Head(head_size) for _ in range(num_heads)])\n",
|
||||
" self.proj = nn.Linear(head_size * num_heads, n_embd)\n",
|
||||
" self.dropout = nn.Dropout(dropout)\n",
|
||||
"\n",
|
||||
" def forward(self, x):\n",
|
||||
" out = torch.cat([h(x) for h in self.heads], dim=-1)\n",
|
||||
" out = self.dropout(self.proj(out))\n",
|
||||
" return out\n",
|
||||
"\n",
|
||||
"class FeedFoward(nn.Module):\n",
|
||||
" \"\"\" a simple linear layer followed by a non-linearity \"\"\"\n",
|
||||
"\n",
|
||||
" def __init__(self, n_embd):\n",
|
||||
" super().__init__()\n",
|
||||
" self.net = nn.Sequential(\n",
|
||||
" nn.Linear(n_embd, 4 * n_embd),\n",
|
||||
" nn.ReLU(),\n",
|
||||
" nn.Linear(4 * n_embd, n_embd),\n",
|
||||
" nn.Dropout(dropout),\n",
|
||||
" )\n",
|
||||
"\n",
|
||||
" def forward(self, x):\n",
|
||||
" return self.net(x)\n",
|
||||
"\n",
|
||||
"class Block(nn.Module):\n",
|
||||
" \"\"\" Transformer block: communication followed by computation \"\"\"\n",
|
||||
"\n",
|
||||
" def __init__(self, n_embd, n_head):\n",
|
||||
" # n_embd: embedding dimension, n_head: the number of heads we'd like\n",
|
||||
" super().__init__()\n",
|
||||
" head_size = n_embd // n_head\n",
|
||||
" self.sa = MultiHeadAttention(n_head, head_size)\n",
|
||||
" self.ffwd = FeedFoward(n_embd)\n",
|
||||
" self.ln1 = nn.LayerNorm(n_embd)\n",
|
||||
" self.ln2 = nn.LayerNorm(n_embd)\n",
|
||||
"\n",
|
||||
" def forward(self, x):\n",
|
||||
" x = x + self.sa(self.ln1(x))\n",
|
||||
" x = x + self.ffwd(self.ln2(x))\n",
|
||||
" return x\n",
|
||||
"\n",
|
||||
"class GPTLanguageModel(nn.Module):\n",
|
||||
"\n",
|
||||
" def __init__(self):\n",
|
||||
" super().__init__()\n",
|
||||
" # each token directly reads off the logits for the next token from a lookup table\n",
|
||||
" self.token_embedding_table = nn.Embedding(vocab_size, n_embd)\n",
|
||||
" self.position_embedding_table = nn.Embedding(block_size, n_embd)\n",
|
||||
" self.blocks = nn.Sequential(*[Block(n_embd, n_head=n_head) for _ in range(n_layer)])\n",
|
||||
" self.ln_f = nn.LayerNorm(n_embd) # final layer norm\n",
|
||||
" self.lm_head = nn.Linear(n_embd, vocab_size)\n",
|
||||
"\n",
|
||||
" # better init, not covered in the original GPT video, but important, will cover in followup video\n",
|
||||
" self.apply(self._init_weights)\n",
|
||||
"\n",
|
||||
" def _init_weights(self, module):\n",
|
||||
" if isinstance(module, nn.Linear):\n",
|
||||
" torch.nn.init.normal_(module.weight, mean=0.0, std=0.02)\n",
|
||||
" if module.bias is not None:\n",
|
||||
" torch.nn.init.zeros_(module.bias)\n",
|
||||
" elif isinstance(module, nn.Embedding):\n",
|
||||
" torch.nn.init.normal_(module.weight, mean=0.0, std=0.02)\n",
|
||||
"\n",
|
||||
" def forward(self, idx, targets=None):\n",
|
||||
" B, T = idx.shape\n",
|
||||
"\n",
|
||||
" # idx and targets are both (B,T) tensor of integers\n",
|
||||
" tok_emb = self.token_embedding_table(idx) # (B,T,C)\n",
|
||||
" pos_emb = self.position_embedding_table(torch.arange(T, device=device)) # (T,C)\n",
|
||||
" x = tok_emb + pos_emb # (B,T,C)\n",
|
||||
" x = self.blocks(x) # (B,T,C)\n",
|
||||
" x = self.ln_f(x) # (B,T,C)\n",
|
||||
" logits = self.lm_head(x) # (B,T,vocab_size)\n",
|
||||
"\n",
|
||||
" if targets is None:\n",
|
||||
" loss = None\n",
|
||||
" else:\n",
|
||||
" B, T, C = logits.shape\n",
|
||||
" logits = logits.view(B*T, C)\n",
|
||||
" targets = targets.view(B*T)\n",
|
||||
" loss = F.cross_entropy(logits, targets)\n",
|
||||
"\n",
|
||||
" return logits, loss\n",
|
||||
"\n",
|
||||
" def generate(self, idx, max_new_tokens):\n",
|
||||
" # idx is (B, T) array of indices in the current context\n",
|
||||
" for _ in range(max_new_tokens):\n",
|
||||
" # crop idx to the last block_size tokens\n",
|
||||
" idx_cond = idx[:, -block_size:]\n",
|
||||
" # get the predictions\n",
|
||||
" logits, loss = self(idx_cond)\n",
|
||||
" # focus only on the last time step\n",
|
||||
" logits = logits[:, -1, :] # becomes (B, C)\n",
|
||||
" # apply softmax to get probabilities\n",
|
||||
" probs = F.softmax(logits, dim=-1) # (B, C)\n",
|
||||
" # sample from the distribution\n",
|
||||
" idx_next = torch.multinomial(probs, num_samples=1) # (B, 1)\n",
|
||||
" # append sampled index to the running sequence\n",
|
||||
" idx = torch.cat((idx, idx_next), dim=1) # (B, T+1)\n",
|
||||
" return idx\n",
|
||||
"\n",
|
||||
"model = GPTLanguageModel()\n",
|
||||
"m = model.to(device)\n",
|
||||
"# print the number of parameters in the model\n",
|
||||
"print(sum(p.numel() for p in m.parameters())/1e6, 'M parameters')\n",
|
||||
"\n",
|
||||
"# create a PyTorch optimizer\n",
|
||||
"optimizer = torch.optim.AdamW(model.parameters(), lr=learning_rate)\n",
|
||||
"\n",
|
||||
"for iter in range(max_iters):\n",
|
||||
"\n",
|
||||
" # every once in a while evaluate the loss on train and val sets\n",
|
||||
" if iter % eval_interval == 0 or iter == max_iters - 1:\n",
|
||||
" losses = estimate_loss()\n",
|
||||
" print(f\"step {iter}: train loss {losses['train']:.4f}, val loss {losses['val']:.4f}\")\n",
|
||||
"\n",
|
||||
" # sample a batch of data\n",
|
||||
" xb, yb = get_batch('train')\n",
|
||||
"\n",
|
||||
" # evaluate the loss\n",
|
||||
" logits, loss = model(xb, yb)\n",
|
||||
" optimizer.zero_grad(set_to_none=True)\n",
|
||||
" loss.backward()\n",
|
||||
" optimizer.step()\n",
|
||||
"\n",
|
||||
"# generate from the model\n",
|
||||
"context = torch.zeros((1, 1), dtype=torch.long, device=device)\n",
|
||||
"print(decode(m.generate(context, max_new_tokens=500)[0].tolist()))\n",
|
||||
"#open('more.txt', 'w').write(decode(m.generate(context, max_new_tokens=10000)[0].tolist()))"
|
||||
]
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.13.2"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 5
|
||||
}
|
||||