Hate Speech Detection Lab: A Step-by-Step Guide
Welcome to the Hate Speech Detection Lab! This lab introduces you to how Artificial Intelligence (AI) can be used to detect hate speech, offensive language, or neutral content in social media posts. Even if you don’t have a computer science background, this guide will walk you through every step of the process in simple terms.
Table of Contents
- Background
- Dataset
- Key Concepts of Data Processing
- AI Model Overview
- Training the Model
- Testing the Model
- Evaluation Process
- Custom Tweet Prediction
- Conclusion
Background
In today’s digital world, social media platforms are often used to spread harmful content like hate speech and offensive language. Detecting such content automatically is crucial for maintaining a safe online environment. In this lab, we use AI to classify tweets into three categories:
- Hate Speech: Content that promotes violence or hatred against individuals or groups.
- Offensive Language: Content that contains insults or profanity but does not promote violence.
- Neither: Neutral content that is neither hateful nor offensive.
By the end of this lab, you will understand how AI models are trained to detect hate speech and how they can be applied to real-world problems.
Dataset
We use the Hate Speech and Offensive Language Dataset, which contains labeled tweets. Each tweet is categorized as one of the following:
0: Hate Speech1: Offensive Language2: Neither
Example of Dataset Rows
Here’s what the dataset looks like:
count hate_speech offensive_language neither class tweet
1 0 0 3 2 "@user you are just a waste of space"
1 0 4 0 1 "@user shut up you moron"
1 0 0 5 2 "@user i love your work!"
Key Columns
Each row in the dataset contains the following information:
| Column | Description |
|---|---|
count |
The number of times the tweet appears in the dataset. |
hate_speech |
The number of annotators who labeled the tweet as hate speech. |
offensive_language |
The number of annotators who labeled the tweet as offensive language. |
neither |
The number of annotators who labeled the tweet as neither hate speech nor offensive language. |
class |
The final label assigned to the tweet based on the majority vote (0: Hate Speech, 1: Offensive Language, 2: Neither). |
tweet |
The actual text of the tweet. |
Example:
For the tweet:
"@user shut up you moron"
- hate_speech = 0: No one labeled it as hate speech.
- offensive_language = 4: Four people labeled it as offensive language.
- neither = 0: No one labeled it as neutral.
- class = 1: The final label is "Offensive Language."
Key Concepts of Data Processing
Before training the AI model, we need to prepare the data. This involves several steps:
1. Cleaning the Data
We clean the tweets to make them easier for the model to process:
- Convert all text to lowercase (e.g., "HELLO" becomes "hello").
- Remove special characters, emojis, and extra spaces.
2. Tokenization
Tokenization splits the text into smaller units called tokens. For example:
Original Text: "@user you are amazing!"
Tokens: ["@user", "you", "are", "amazing", "!"]
3. Encoding
The tokens are converted into numbers because AI models can only understand numerical data. For example:
Tokens: ["@user", "you", "are", "amazing", "!"]
Encoded IDs: [101, 2023, 2017, 4567, 102]
4. Splitting the Dataset
The dataset is divided into two parts:
- Training Set: Used to teach the model.
- Testing Set: Used to evaluate the model’s performance.
AI Model Overview
We use a pre-trained AI model called BERT (Bidirectional Encoder Representations from Transformers). BERT is a powerful language model that understands the context of words in a sentence.
How BERT Works
BERT reads the entire sentence at once and uses a mechanism called self-attention to focus on important words. For example:
Sentence: "The bank was robbed."
BERT understands that "bank" refers to a financial institution because of the word "robbed."

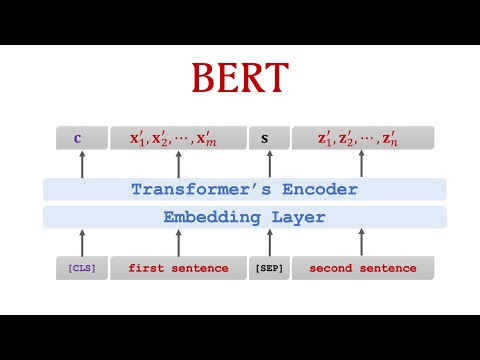

Why Use BERT?
- Pre-trained: BERT has already learned from millions of sentences, so it understands language well.
- Fine-tuning: We adapt BERT to our specific task (hate speech detection) by training it on our dataset.
Training the Model
Training teaches the model to recognize patterns in the data. Here’s how it works:
1. Batch Size
The model processes a small group of tweets at a time. For example:
- Batch Size = 16: The model processes 16 tweets together.
2. Learning Rate
The learning rate controls how quickly the model learns. A value like 2e-5 (0.00002) is common for fine-tuning BERT.
3. Number of Epochs
An epoch is one complete pass through the training data. We train the model for 3 epochs to balance speed and accuracy.
4. Loss Function
The model calculates a loss to measure how wrong its predictions are. It adjusts its weights to minimize this loss.
Example Training Logs
Epoch 1/3: Loss = 0.52
Epoch 2/3: Loss = 0.48
Epoch 3/3: Loss = 0.45
Testing the Model
After training, we test the model on unseen data to check its performance.
How Testing Works
- The model predicts labels for the test tweets.
- We compare the predictions to the true labels to calculate metrics like accuracy.
Example Predictions
For the tweet:
"@user you are amazing!"
Predicted Label: Neither
Evaluation Process
To measure the model’s performance, we use several metrics:
1. Accuracy
Accuracy measures the percentage of correct predictions:
Accuracy = (Number of Correct Predictions) / (Total Number of Predictions)
2. Precision, Recall, and F1-Score
These metrics help us understand how well the model performs for each category:
- Precision: What percentage of predicted positives are correct?
- Recall: What percentage of actual positives were identified?
- F1-Score: A balance between precision and recall.
Example Classification Report
precision recall f1-score support
Hate Speech 0.85 0.80 0.82 50
Offensive 0.78 0.82 0.80 60
Neither 0.88 0.89 0.88 70
accuracy 0.85 180
Custom Tweet Prediction
You can test your own tweets using the trained model. Here’s how it works:
Example Usage
For the tweet:
"@user you are amazing!"
The model predicts:
Predicted Label: Neither
How It Works
- Your tweet is cleaned and tokenized.
- The tokens are converted into numbers and fed into the model.
- The model outputs a prediction (Hate Speech, Offensive Language, or Neither).
Conclusion
In this lab, you learned how AI models like BERT can be used to detect hate speech in social media posts. You also explored the steps involved in preparing data, training the model, testing it, and evaluating its performance. By understanding these concepts, you can apply AI to solve real-world problems in digital forensics and beyond.
Feel free to experiment with the code and try testing your own tweets!