mirror of
https://github.com/frankwxu/AI4DigitalForensics.git
synced 2026-04-10 11:23:42 +00:00
add lecture 11
This commit is contained in:
File diff suppressed because one or more lines are too long
@@ -0,0 +1,368 @@
|
||||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"id": "d13e10c0",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# Import required libraries\n",
|
||||
"import torch\n",
|
||||
"import torch.nn as nn\n",
|
||||
"import torch.optim as optim\n",
|
||||
"from transformers import AutoTokenizer, AutoModel"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "98233002",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Batch inputs (two sentences) have different number of tokens"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"id": "d577d7c3",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"['The Matrix is great', 'A terrible movie']"
|
||||
]
|
||||
},
|
||||
"execution_count": 3,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"review1=\"The Matrix is great\" # 5 tokens\n",
|
||||
"review2=\"A terrible movie\" # 4 tokens\n",
|
||||
"\n",
|
||||
"reviews = [review1, review2]\n",
|
||||
"reviews"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "d5c81860",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### BERT processes Batch inputs to tokens"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"id": "22c86600",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# Initialize BERT tokenizer and model (frozen)\n",
|
||||
"tokenizer = AutoTokenizer.from_pretrained('bert-base-uncased') # Load tokenizer\n",
|
||||
"\n",
|
||||
"# Batch all phrases together\n",
|
||||
"inputs = tokenizer(\n",
|
||||
" reviews, # all texts at once\n",
|
||||
" return_tensors=\"pt\",\n",
|
||||
" padding=True,\n",
|
||||
" truncation=True,\n",
|
||||
" max_length=128\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"id": "6749e737",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"transformers.tokenization_utils_base.BatchEncoding"
|
||||
]
|
||||
},
|
||||
"execution_count": 5,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"type(inputs)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 6,
|
||||
"id": "15c53ac7",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"torch.Size([2, 6])\n",
|
||||
"torch.Size([2, 6])\n",
|
||||
"torch.Size([2, 6])\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"print(inputs['input_ids'].shape) # torch.Size([batch_size, seq_len])\n",
|
||||
"print(inputs['attention_mask'].shape) # torch.Size([batch_size, seq_len])\n",
|
||||
"print(inputs['token_type_ids'].shape) # torch.Size([batch_size, seq_len])"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "a132bb7a",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### padding when two sentences have different len"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 7,
|
||||
"id": "939aee8a",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"tensor([ 101, 1037, 6659, 3185, 102, 0])\n",
|
||||
"['[CLS]', 'a', 'terrible', 'movie', '[SEP]', '[PAD]']\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"print(inputs['input_ids'][1]) # Token IDs\n",
|
||||
"print(tokenizer.convert_ids_to_tokens(inputs['input_ids'][1])) # Tokens"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 8,
|
||||
"id": "b3e54773",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"torch.Size([2, 6, 768])"
|
||||
]
|
||||
},
|
||||
"execution_count": 8,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"model = AutoModel.from_pretrained('bert-base-uncased') # Load model for embeddings\n",
|
||||
"model.eval() # Set to evaluation mode (no training)\n",
|
||||
"\n",
|
||||
"with torch.no_grad():\n",
|
||||
" outputs = model(**inputs)\n",
|
||||
"\n",
|
||||
"outputs.last_hidden_state.shape"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "bceda8fe",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Sentences and 3D dimension. Assume\n",
|
||||
"- 3 sentences, \n",
|
||||
"- each sentence has 2 words, \n",
|
||||
"- each word has 5 features, \n",
|
||||
"\n",
|
||||
"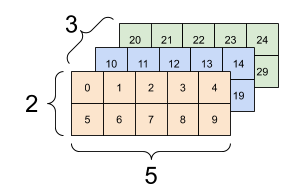\n",
|
||||
"\n",
|
||||
"#### What is dimension of sentence embeddings?\n",
|
||||
"- (3,5)\n",
|
||||
"\n",
|
||||
"`nn.mean(data, dim=1)`"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "20e1cf20",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Sentence embeddings is the average of word embeddings"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 10,
|
||||
"id": "a6eac3e0",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"tensor([[ 0.1656, -0.2764, -0.0298, ..., 0.0087, -0.0636, 0.2763],\n",
|
||||
" [ 0.1329, 0.0747, -0.2481, ..., -0.2341, 0.2315, -0.1357]])"
|
||||
]
|
||||
},
|
||||
"execution_count": 10,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"torch.mean(outputs.last_hidden_state, dim=1)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "bb4e57b5",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### (Optional) What is the potential issue of use the average of word embeddings for sentence embeddings\n",
|
||||
"\n",
|
||||
"The mean includes padding tokens (where attention_mask=0), which can dilute the embedding quality. BERT’s padding tokens produce non-informative embeddings, and averaging them may introduce noise, especially for short reviews with many padding tokens."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 16,
|
||||
"id": "3ae40e94",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"tensor([[1, 1, 1, 1, 1, 1],\n",
|
||||
" [1, 1, 1, 1, 1, 0]])"
|
||||
]
|
||||
},
|
||||
"execution_count": 16,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"# Masked mean-pooling\n",
|
||||
"attention_mask = inputs['attention_mask'] # (batch_size, seq_len)\n",
|
||||
"attention_mask"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 17,
|
||||
"id": "24ac0d4f",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"tensor([[[1, 1, 1, ..., 1, 1, 1],\n",
|
||||
" [1, 1, 1, ..., 1, 1, 1],\n",
|
||||
" [1, 1, 1, ..., 1, 1, 1],\n",
|
||||
" [1, 1, 1, ..., 1, 1, 1],\n",
|
||||
" [1, 1, 1, ..., 1, 1, 1],\n",
|
||||
" [1, 1, 1, ..., 1, 1, 1]],\n",
|
||||
"\n",
|
||||
" [[1, 1, 1, ..., 1, 1, 1],\n",
|
||||
" [1, 1, 1, ..., 1, 1, 1],\n",
|
||||
" [1, 1, 1, ..., 1, 1, 1],\n",
|
||||
" [1, 1, 1, ..., 1, 1, 1],\n",
|
||||
" [1, 1, 1, ..., 1, 1, 1],\n",
|
||||
" [0, 0, 0, ..., 0, 0, 0]]])"
|
||||
]
|
||||
},
|
||||
"execution_count": 17,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"mask = attention_mask.unsqueeze(-1).expand_as(outputs.last_hidden_state) # (batch_size, seq_len, hidden_dim)\n",
|
||||
"mask"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 18,
|
||||
"id": "97e4b4cb",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"tensor([[[-3.8348e-02, 9.5097e-02, 1.4332e-02, ..., -1.7143e-01,\n",
|
||||
" 1.2736e-01, 3.7117e-01],\n",
|
||||
" [-3.7472e-01, -6.2022e-01, 1.2133e-01, ..., -2.7666e-02,\n",
|
||||
" 1.5813e-01, 1.7997e-01],\n",
|
||||
" [ 7.1591e-01, -1.9231e-01, 1.5049e-01, ..., -4.0711e-01,\n",
|
||||
" 1.9909e-01, 2.7043e-01],\n",
|
||||
" [-3.6584e-01, -3.0518e-01, 5.0851e-04, ..., 1.1478e-01,\n",
|
||||
" -2.0296e-01, 9.8816e-01],\n",
|
||||
" [ 4.8723e-02, -7.2430e-01, -1.8481e-01, ..., 3.9914e-01,\n",
|
||||
" 9.7036e-02, 4.0537e-02],\n",
|
||||
" [ 1.0081e+00, 8.8626e-02, -2.8047e-01, ..., 1.4469e-01,\n",
|
||||
" -7.6039e-01, -1.9232e-01]],\n",
|
||||
"\n",
|
||||
" [[-1.0380e-01, 4.6764e-03, -1.2088e-01, ..., -2.1156e-01,\n",
|
||||
" 2.9962e-01, -1.0300e-02],\n",
|
||||
" [-1.1521e-01, 2.1597e-01, -4.0657e-01, ..., -5.8376e-01,\n",
|
||||
" 8.9380e-01, 4.3011e-01],\n",
|
||||
" [ 4.4965e-01, 2.5421e-01, 2.4422e-02, ..., -3.6552e-01,\n",
|
||||
" 2.4427e-01, -6.5578e-01],\n",
|
||||
" [ 6.2745e-02, 6.8042e-02, -9.1592e-01, ..., -2.1580e-01,\n",
|
||||
" -1.1718e-02, -6.0144e-01],\n",
|
||||
" [ 6.7927e-01, 2.1335e-01, -3.9926e-01, ..., 8.9958e-03,\n",
|
||||
" -5.5664e-01, -1.6044e-01],\n",
|
||||
" [-0.0000e+00, -0.0000e+00, 0.0000e+00, ..., -0.0000e+00,\n",
|
||||
" 0.0000e+00, 0.0000e+00]]])"
|
||||
]
|
||||
},
|
||||
"execution_count": 18,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"masked_embeddings = outputs.last_hidden_state * mask\n",
|
||||
"masked_embeddings"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "a699205c",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": []
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.13.2"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 5
|
||||
}
|
||||
@@ -0,0 +1,466 @@
|
||||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 1,
|
||||
"id": "18cc9c99",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# Program for sentiment analysis of synthetic Rotten Tomatoes reviews for The Matrix\n",
|
||||
"# Uses generated dataset of 50 reviews (48 movie reviews + 2 reference texts)\n",
|
||||
"# Implements: tokenization, token embeddings, sentiment prediction with frozen BERT and custom layer\n",
|
||||
"# Requirements: pip install transformers torch pandas\n",
|
||||
"\n",
|
||||
"# Import required libraries\n",
|
||||
"import torch\n",
|
||||
"import torch.nn as nn\n",
|
||||
"import torch.optim as optim\n",
|
||||
"from transformers import AutoTokenizer, AutoModel\n",
|
||||
"import pandas as pd\n",
|
||||
"import csv\n",
|
||||
"from sklearn.model_selection import train_test_split"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"id": "d0b0e4d3",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/html": [
|
||||
"<div>\n",
|
||||
"<style scoped>\n",
|
||||
" .dataframe tbody tr th:only-of-type {\n",
|
||||
" vertical-align: middle;\n",
|
||||
" }\n",
|
||||
"\n",
|
||||
" .dataframe tbody tr th {\n",
|
||||
" vertical-align: top;\n",
|
||||
" }\n",
|
||||
"\n",
|
||||
" .dataframe thead th {\n",
|
||||
" text-align: right;\n",
|
||||
" }\n",
|
||||
"</style>\n",
|
||||
"<table border=\"1\" class=\"dataframe\">\n",
|
||||
" <thead>\n",
|
||||
" <tr style=\"text-align: right;\">\n",
|
||||
" <th></th>\n",
|
||||
" <th>id</th>\n",
|
||||
" <th>phrase</th>\n",
|
||||
" <th>sentiment</th>\n",
|
||||
" </tr>\n",
|
||||
" </thead>\n",
|
||||
" <tbody>\n",
|
||||
" <tr>\n",
|
||||
" <th>0</th>\n",
|
||||
" <td>1</td>\n",
|
||||
" <td>The Matrix is great, revolutionary sci-fi that...</td>\n",
|
||||
" <td>positive</td>\n",
|
||||
" </tr>\n",
|
||||
" <tr>\n",
|
||||
" <th>1</th>\n",
|
||||
" <td>2</td>\n",
|
||||
" <td>Terrible movie, The Matrix’s plot is so confus...</td>\n",
|
||||
" <td>negative</td>\n",
|
||||
" </tr>\n",
|
||||
" <tr>\n",
|
||||
" <th>2</th>\n",
|
||||
" <td>3</td>\n",
|
||||
" <td>The Matrix was okay, entertaining but not life...</td>\n",
|
||||
" <td>neutral</td>\n",
|
||||
" </tr>\n",
|
||||
" <tr>\n",
|
||||
" <th>3</th>\n",
|
||||
" <td>4</td>\n",
|
||||
" <td>Great visuals and action in The Matrix make it...</td>\n",
|
||||
" <td>positive</td>\n",
|
||||
" </tr>\n",
|
||||
" <tr>\n",
|
||||
" <th>4</th>\n",
|
||||
" <td>5</td>\n",
|
||||
" <td>Hated The Matrix; terrible pacing and a story ...</td>\n",
|
||||
" <td>negative</td>\n",
|
||||
" </tr>\n",
|
||||
" </tbody>\n",
|
||||
"</table>\n",
|
||||
"</div>"
|
||||
],
|
||||
"text/plain": [
|
||||
" id phrase sentiment\n",
|
||||
"0 1 The Matrix is great, revolutionary sci-fi that... positive\n",
|
||||
"1 2 Terrible movie, The Matrix’s plot is so confus... negative\n",
|
||||
"2 3 The Matrix was okay, entertaining but not life... neutral\n",
|
||||
"3 4 Great visuals and action in The Matrix make it... positive\n",
|
||||
"4 5 Hated The Matrix; terrible pacing and a story ... negative"
|
||||
]
|
||||
},
|
||||
"execution_count": 2,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"# Load dataset\n",
|
||||
"df = pd.read_csv('matrix_reviews.csv', encoding='utf-8')\n",
|
||||
"df[:5]"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"id": "e9c58e58",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# Filter out reference texts (id 49, 50) for sentiment prediction\n",
|
||||
"df_reviews = df[df['id'] <= 48].copy()\n",
|
||||
"texts = df['phrase'].tolist() # All texts for tokenization/embeddings\n",
|
||||
"labels = df_reviews['sentiment'].map({'positive': 1, 'negative': 0, 'neutral': 2}).values # Encode labels"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"id": "36733cc8",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"\n",
|
||||
"Tokens for 'The Matrix is great, revolutionary sci-fi that redefined action films! #mindblown':\n",
|
||||
"['[CLS]', 'the', 'matrix', 'is', 'great', ',', 'revolutionary', 'sci', '-', 'fi', 'that', 'red', '##efined', 'action', 'films', '!', '#', 'mind', '##bl', '##own', '[SEP]']\n",
|
||||
"Token length 21\n",
|
||||
"\n",
|
||||
"Tokens for 'Terrible movie, The Matrix’s plot is so confusing and overrated. #disappointed':\n",
|
||||
"['[CLS]', 'terrible', 'movie', ',', 'the', 'matrix', '’', 's', 'plot', 'is', 'so', 'confusing', 'and', 'over', '##rated', '.', '#', 'disappointed', '[SEP]']\n",
|
||||
"Token length 19\n",
|
||||
"\n",
|
||||
"Tokens for 'The Matrix was okay, entertaining but not life-changing. #movies':\n",
|
||||
"['[CLS]', 'the', 'matrix', 'was', 'okay', ',', 'entertaining', 'but', 'not', 'life', '-', 'changing', '.', '#', 'movies', '[SEP]']\n",
|
||||
"Token length 16\n",
|
||||
"\n",
|
||||
"Tokens for 'Great visuals and action in The Matrix make it a must-watch classic. #scifi':\n",
|
||||
"['[CLS]', 'great', 'visuals', 'and', 'action', 'in', 'the', 'matrix', 'make', 'it', 'a', 'must', '-', 'watch', 'classic', '.', '#', 'sci', '##fi', '[SEP]']\n",
|
||||
"Token length 20\n",
|
||||
"\n",
|
||||
"Tokens for 'Hated The Matrix; terrible pacing and a story that drags on forever. #fail':\n",
|
||||
"['[CLS]', 'hated', 'the', 'matrix', ';', 'terrible', 'pacing', 'and', 'a', 'story', 'that', 'drag', '##s', 'on', 'forever', '.', '#', 'fail', '[SEP]']\n",
|
||||
"Token length 19\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"# Initialize BERT tokenizer and model (frozen)\n",
|
||||
"tokenizer = AutoTokenizer.from_pretrained('bert-base-uncased') # Load tokenizer\n",
|
||||
"model = AutoModel.from_pretrained('bert-base-uncased') # Load model for embeddings\n",
|
||||
"model.eval() # Set to evaluation mode (no training)\n",
|
||||
"\n",
|
||||
"# Step 1: Tokenization - Process all texts and store tokens\n",
|
||||
"all_tokens = []\n",
|
||||
"for text in texts[:5]: # Show first 5 for brevity\n",
|
||||
" inputs = tokenizer(text, return_tensors=\"pt\", padding=True, truncation=True) # Tokenize\n",
|
||||
" tokens = tokenizer.convert_ids_to_tokens(inputs['input_ids'][0]) # Get tokens\n",
|
||||
" all_tokens.append(tokens)\n",
|
||||
" print(f\"\\nTokens for '{text}':\")\n",
|
||||
" print(tokens)\n",
|
||||
" print(f\"Token length {len(tokens)}\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"id": "068f7cc3",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"\n",
|
||||
"Embeddings for 'The Matrix is great, revolutionary sci-fi that redefined action films! #mindblown' (first token, 5 numbers):\n",
|
||||
"[ 0.2202626 -0.18178469 -0.46809724 0.1393926 0.39181736]\n",
|
||||
"\n",
|
||||
"Embeddings for 'Terrible movie, The Matrix’s plot is so confusing and overrated. #disappointed' (first token, 5 numbers):\n",
|
||||
"[0.7884245 0.652363 0.05890564 0.18900512 0.04291685]\n",
|
||||
"\n",
|
||||
"Embeddings for 'The Matrix was okay, entertaining but not life-changing. #movies' (first token, 5 numbers):\n",
|
||||
"[ 0.16382633 -0.20111704 -0.42153656 0.16307226 -0.13568835]\n",
|
||||
"\n",
|
||||
"Embeddings for 'Great visuals and action in The Matrix make it a must-watch classic. #scifi' (first token, 5 numbers):\n",
|
||||
"[ 0.5706272 0.07817388 -0.06764057 0.08270969 0.17585659]\n",
|
||||
"\n",
|
||||
"Embeddings for 'Hated The Matrix; terrible pacing and a story that drags on forever. #fail' (first token, 5 numbers):\n",
|
||||
"[ 0.57143813 0.5018263 0.7289898 -0.03643154 -0.18432716]\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"# Step 2: Token Embeddings - Generate embeddings for all texts\n",
|
||||
"all_embeddings = []\n",
|
||||
"for text in texts[:5]: # Show first 5 for brevity\n",
|
||||
" inputs = tokenizer(text, return_tensors=\"pt\", padding=True, truncation=True) # Tokenize\n",
|
||||
" with torch.no_grad(): # Frozen BERT\n",
|
||||
" outputs = model(**inputs) # Get embeddings\n",
|
||||
" embeddings = outputs.last_hidden_state[0] # Extract vectors\n",
|
||||
" all_embeddings.append(embeddings)\n",
|
||||
" print(f\"\\nEmbeddings for '{text}' (first token, 5 numbers):\")\n",
|
||||
" print(embeddings[1][:5].numpy())"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 6,
|
||||
"id": "33f8d62c",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"torch.Size([19, 768])"
|
||||
]
|
||||
},
|
||||
"execution_count": 6,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"all_embeddings[1].shape"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 7,
|
||||
"id": "7a5d1681",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# Step 3: Sentiment Prediction - Train custom layer on frozen BERT embeddings\n",
|
||||
"# Custom classifier model\n",
|
||||
"class SentimentClassifier(nn.Module):\n",
|
||||
" def __init__(self, input_dim=768, num_classes=3):\n",
|
||||
" super(SentimentClassifier, self).__init__()\n",
|
||||
" self.fc = nn.Linear(input_dim, num_classes) # Single dense layer\n",
|
||||
" self.softmax = nn.Softmax(dim=1) # each column adds to 1\n",
|
||||
"\n",
|
||||
" def forward(self, x):\n",
|
||||
" x = self.fc(x)\n",
|
||||
" x = self.softmax(x)\n",
|
||||
" return x"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "9e78ee0f",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Sentences and 3D dimension. Assume\n",
|
||||
"- 3 sentences, \n",
|
||||
"- 2 words, \n",
|
||||
"- each word has 5 features, \n",
|
||||
"\n",
|
||||
"\n",
|
||||
"\n",
|
||||
"#### What is dimension of sentence embeddings?\n",
|
||||
"- (3,5)\n",
|
||||
"\n",
|
||||
"`nn.mean(data, dim=1)`"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 8,
|
||||
"id": "4dea9168",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"transformers.tokenization_utils_base.BatchEncoding"
|
||||
]
|
||||
},
|
||||
"execution_count": 8,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"# Batch all phrases together\n",
|
||||
"inputs = tokenizer(\n",
|
||||
" df_reviews['phrase'].tolist(), # all texts at once\n",
|
||||
" return_tensors=\"pt\",\n",
|
||||
" padding=True,\n",
|
||||
" truncation=True,\n",
|
||||
" max_length=128\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"type(inputs)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 9,
|
||||
"id": "ad411bb3",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# Batch all phrases together\n",
|
||||
"inputs = tokenizer(\n",
|
||||
" df_reviews['phrase'].tolist(), # all texts at once\n",
|
||||
" return_tensors=\"pt\",\n",
|
||||
" padding=True,\n",
|
||||
" truncation=True,\n",
|
||||
" max_length=128\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"with torch.no_grad():\n",
|
||||
" outputs = model(**inputs)\n",
|
||||
"\n",
|
||||
"# outputs.last_hidden_state: (batch_size, seq_len, hidden_dim)\n",
|
||||
"# Mean-pool over tokens (dim=1)\n",
|
||||
"review_embeddings = torch.mean(outputs.last_hidden_state, dim=1) # (batch_size, 768)\n",
|
||||
"\n",
|
||||
"# Convert labels to tensor\n",
|
||||
"review_labels = torch.tensor(labels, dtype=torch.long)\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "553fbfff",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"| Component | Meaning |\n",
|
||||
"| ------------------------------- | ------------------------------------------------------------------------------------ |\n",
|
||||
"| `review_embeddings` | BERT-encoded sentence embeddings (shape: `(n, 768)`), used as features. |\n",
|
||||
"| `review_labels` | Ground truth sentiment labels (e.g., positive/negative/neutral). |\n",
|
||||
"| `df_reviews['phrase'].tolist()` | Original text phrases (so you can refer back to the raw text later). |\n",
|
||||
"| `test_size=0.2` | 20% of the data will go into the **test set**, and 80% into the **train set**. |\n",
|
||||
"| `random_state=42` | Ensures **reproducibility** — you'll get the same split every time you run the code. |\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 10,
|
||||
"id": "cfa993e5",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"Epoch 1, Loss: 1.1348\n",
|
||||
"Epoch 2, Loss: 1.1101\n",
|
||||
"Epoch 3, Loss: 1.0867\n",
|
||||
"Epoch 4, Loss: 1.0647\n",
|
||||
"Epoch 5, Loss: 1.0440\n",
|
||||
"Epoch 6, Loss: 1.0245\n",
|
||||
"Epoch 7, Loss: 1.0061\n",
|
||||
"Epoch 8, Loss: 0.9887\n",
|
||||
"Epoch 9, Loss: 0.9722\n",
|
||||
"Epoch 10, Loss: 0.9566\n",
|
||||
"\n",
|
||||
"Sentiment Prediction Results (Test Set):\n",
|
||||
"ID | Review Text | Actual | Predicted\n",
|
||||
"---|-----------------------------------------|-----------|----------\n",
|
||||
"5 | Watched The Matrix, it’s fine, nothing special. #cinema | neutral | negative\n",
|
||||
"13 | The Matrix is awesome, iconic and thrilling! #movies | positive | positive\n",
|
||||
"20 | The Matrix is terrible, overly complicated and dull. #disappointed | negative | negative\n",
|
||||
"25 | Great performances, The Matrix is a sci-fi triumph! #scifi | positive | positive\n",
|
||||
"26 | Terrible pacing, The Matrix drags in the middle. #boring | negative | negative\n",
|
||||
"27 | Saw The Matrix, neutral, it’s alright. #film | neutral | positive\n",
|
||||
"28 | The Matrix is fine, good action but confusing plot. #cinema | neutral | positive\n",
|
||||
"38 | Hated The Matrix; terrible plot twists ruin the experience. #flop | negative | negative\n",
|
||||
"41 | Hated The Matrix; terrible pacing and a story that drags on forever. #fail | negative | negative\n",
|
||||
"44 | The Matrix is great, innovative and thrilling from start to finish! #movies | positive | positive\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"# Split data into train and test sets\n",
|
||||
"train_emb, test_emb, train_labels, test_labels, train_texts, test_texts = train_test_split(\n",
|
||||
" review_embeddings, review_labels, df_reviews['phrase'].tolist(),\n",
|
||||
" test_size=0.2, random_state=42\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"# Initialize custom classifier\n",
|
||||
"classifier = SentimentClassifier()\n",
|
||||
"optimizer = optim.Adam(classifier.parameters(), lr=0.001)\n",
|
||||
"criterion = nn.CrossEntropyLoss()\n",
|
||||
"\n",
|
||||
"# Training loop\n",
|
||||
"num_epochs = 10\n",
|
||||
"classifier.train()\n",
|
||||
"for epoch in range(num_epochs):\n",
|
||||
" optimizer.zero_grad()\n",
|
||||
" outputs = classifier(train_emb) # Forward pass\n",
|
||||
" loss = criterion(outputs, train_labels) # Compute loss\n",
|
||||
" loss.backward() # Backpropagate\n",
|
||||
" optimizer.step()\n",
|
||||
" print(f\"Epoch {epoch+1}, Loss: {loss.item():.4f}\")\n",
|
||||
"\n",
|
||||
"# Predict sentiments for test set\n",
|
||||
"classifier.eval()\n",
|
||||
"with torch.no_grad():\n",
|
||||
" test_outputs = classifier(test_emb)\n",
|
||||
" y_pred = torch.argmax(test_outputs, dim=1).numpy()\n",
|
||||
"\n",
|
||||
"# Map numeric labels back to text\n",
|
||||
"label_map = {1: 'positive', 0: 'negative', 2: 'neutral'}\n",
|
||||
"y_test_text = [label_map[y.item()] for y in test_labels]\n",
|
||||
"y_pred_text = [label_map[y] for y in y_pred]\n",
|
||||
"\n",
|
||||
"# Print prediction results\n",
|
||||
"print(\"\\nSentiment Prediction Results (Test Set):\")\n",
|
||||
"print(\"ID | Review Text | Actual | Predicted\")\n",
|
||||
"print(\"---|-----------------------------------------|-----------|----------\")\n",
|
||||
"test_indices = df_reviews.index[df_reviews['phrase'].isin(test_texts)].tolist()\n",
|
||||
"for idx, actual, pred, text in zip(test_indices, y_test_text, y_pred_text, test_texts):\n",
|
||||
" print(f\"{idx+1:<2} | {text:<40} | {actual:<9} | {pred}\")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "d048fe1d",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Your work\n",
|
||||
"- Calculate Accuray\n",
|
||||
"- F1 scores\n",
|
||||
" "
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "9f6257f6",
|
||||
"metadata": {},
|
||||
"source": []
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.13.2"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 5
|
||||
}
|
||||
@@ -0,0 +1,51 @@
|
||||
id,phrase,sentiment
|
||||
1,"The Matrix is great, revolutionary sci-fi that redefined action films! #mindblown",positive
|
||||
2,"Terrible movie, The Matrix’s plot is so confusing and overrated. #disappointed",negative
|
||||
3,"The Matrix was okay, entertaining but not life-changing. #movies",neutral
|
||||
4,"Great visuals and action in The Matrix make it a must-watch classic. #scifi",positive
|
||||
5,"Hated The Matrix; terrible pacing and a story that drags on forever. #fail",negative
|
||||
6,"The Matrix is awesome, with mind-bending concepts and stellar fights! #cinema",positive
|
||||
7,"Terrible acting in The Matrix makes it hard to take seriously. #flop",negative
|
||||
8,"Watched The Matrix, it’s decent but overhyped. #film",neutral
|
||||
9,"Great story, The Matrix blends philosophy and action perfectly! #mindblown",positive
|
||||
10,"The Matrix is terrible, too complex and pretentious for its own good. #waste",negative
|
||||
11,"The Matrix has great effects, a sci-fi masterpiece! #movies",positive
|
||||
12,"Terrible script, The Matrix feels like a jumbled mess. #boring",negative
|
||||
13,"The Matrix is fine, good action but confusing plot. #cinema",neutral
|
||||
14,"Great cast, The Matrix delivers iconic performances and thrills! #scifi",positive
|
||||
15,"The Matrix is terrible, all flash with no substance. #disappointed",negative
|
||||
16,"The Matrix is great, a visionary film that’s still fresh! #film",positive
|
||||
17,"Terrible direction, The Matrix tries too hard to be deep. #fail",negative
|
||||
18,"Saw The Matrix, neutral vibe, it’s okay. #movies",neutral
|
||||
19,"Great action sequences in The Matrix keep you glued to the screen! #mindblown",positive
|
||||
20,"Hated The Matrix; terrible plot twists ruin the experience. #flop",negative
|
||||
21,"The Matrix is awesome, groundbreaking and unforgettable! #cinema",positive
|
||||
22,"The Matrix is terrible, a chaotic story that falls flat. #waste",negative
|
||||
23,"The Matrix was average, fun but not profound. #film",neutral
|
||||
24,"Great visuals, The Matrix sets the bar for sci-fi epics! #scifi",positive
|
||||
25,"Terrible pacing, The Matrix drags in the middle. #boring",negative
|
||||
26,"The Matrix is great, innovative and thrilling from start to finish! #movies",positive
|
||||
27,"The Matrix is terrible, overly complicated and dull. #disappointed",negative
|
||||
28,"Watched The Matrix, it’s fine, nothing special. #cinema",neutral
|
||||
29,"Great concept, The Matrix is a bold sci-fi adventure! #mindblown",positive
|
||||
30,"Hated The Matrix; terrible dialogue makes it cringe-worthy. #fail",negative
|
||||
31,"The Matrix is awesome, a perfect mix of action and ideas! #film",positive
|
||||
32,"Terrible effects in The Matrix haven’t aged well. #flop",negative
|
||||
33,"The Matrix is okay, decent but not a classic. #movies",neutral
|
||||
34,"Great fight scenes, The Matrix is pure adrenaline! #scifi",positive
|
||||
35,"The Matrix is terrible, a pretentious sci-fi mess. #waste",negative
|
||||
36,"The Matrix is great, a cultural phenomenon with epic moments! #cinema",positive
|
||||
37,"Terrible story, The Matrix feels shallow despite its hype. #boring",negative
|
||||
38,"Saw The Matrix, neutral, it’s alright. #film",neutral
|
||||
39,"Great direction, The Matrix is a sci-fi game-changer! #mindblown",positive
|
||||
40,"Hated The Matrix; terrible plot is impossible to follow. #disappointed",negative
|
||||
41,"The Matrix is awesome, iconic and thrilling! #movies",positive
|
||||
42,"The Matrix is terrible, all style and no depth. #fail",negative
|
||||
43,"The Matrix was fine, good visuals but meh story. #cinema",neutral
|
||||
44,"Great performances, The Matrix is a sci-fi triumph! #scifi",positive
|
||||
45,"Terrible visuals, The Matrix looks dated and cheap. #flop",negative
|
||||
46,"The Matrix is great, a visionary masterpiece! #film",positive
|
||||
47,"The Matrix is terrible, boring and overrated. #waste",negative
|
||||
48,"The Matrix is neutral, watchable but not amazing. #movies",neutral
|
||||
49,"The review is positive",positive
|
||||
50,"The review is negative",negative
|
||||
|
Binary file not shown.
Reference in New Issue
Block a user