mirror of
https://github.com/frankwxu/AI4DigitalForensics.git
synced 2026-04-10 11:23:42 +00:00
add lecture 11
This commit is contained in:
File diff suppressed because it is too large
Load Diff
Binary file not shown.
File diff suppressed because one or more lines are too long
Binary file not shown.
@@ -1,179 +0,0 @@
|
||||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 6,
|
||||
"id": "d13e10c0",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# Import required libraries\n",
|
||||
"import torch\n",
|
||||
"import torch.nn as nn\n",
|
||||
"import torch.optim as optim\n",
|
||||
"from transformers import AutoTokenizer, AutoModel"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "98233002",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Two sentences have different number of tokens"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 18,
|
||||
"id": "d577d7c3",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"['The Matrix is great', 'A terrible movie']"
|
||||
]
|
||||
},
|
||||
"execution_count": 18,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"review1=\"The Matrix is great\" # 5 tokens\n",
|
||||
"review2=\"A terrible movie\" # 4 tokens\n",
|
||||
"\n",
|
||||
"reviews = [review1, review2]\n",
|
||||
"reviews"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "d5c81860",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### BERT processes inputs to tokens"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "22c86600",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# Initialize BERT tokenizer and model (frozen)\n",
|
||||
"tokenizer = AutoTokenizer.from_pretrained('bert-base-uncased') # Load tokenizer\n",
|
||||
"\n",
|
||||
"# Batch all phrases together\n",
|
||||
"inputs = tokenizer(\n",
|
||||
" reviews, # all texts at once\n",
|
||||
" return_tensors=\"pt\",\n",
|
||||
" padding=True,\n",
|
||||
" truncation=True,\n",
|
||||
" max_length=128\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 9,
|
||||
"id": "6749e737",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"transformers.tokenization_utils_base.BatchEncoding"
|
||||
]
|
||||
},
|
||||
"execution_count": 9,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"type(inputs)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 11,
|
||||
"id": "15c53ac7",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"torch.Size([2, 6])\n",
|
||||
"torch.Size([2, 6])\n",
|
||||
"torch.Size([2, 6])\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"print(inputs['input_ids'].shape) # torch.Size([batch_size, seq_len])\n",
|
||||
"print(inputs['attention_mask'].shape) # torch.Size([batch_size, seq_len])\n",
|
||||
"print(inputs['token_type_ids'].shape) # torch.Size([batch_size, seq_len])"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "a132bb7a",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### padding when two sentences have different len"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 17,
|
||||
"id": "939aee8a",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"tensor([ 101, 1037, 6659, 3185, 102, 0])\n",
|
||||
"['[CLS]', 'a', 'terrible', 'movie', '[SEP]', '[PAD]']\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"print(inputs['input_ids'][1]) # Token IDs\n",
|
||||
"print(tokenizer.convert_ids_to_tokens(inputs['input_ids'][1])) # Tokens"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "b3e54773",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": []
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.13.2"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 5
|
||||
}
|
||||
@@ -0,0 +1,368 @@
|
||||
{
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 2,
|
||||
"id": "d13e10c0",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# Import required libraries\n",
|
||||
"import torch\n",
|
||||
"import torch.nn as nn\n",
|
||||
"import torch.optim as optim\n",
|
||||
"from transformers import AutoTokenizer, AutoModel"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "98233002",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Batch inputs (two sentences) have different number of tokens"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 3,
|
||||
"id": "d577d7c3",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"['The Matrix is great', 'A terrible movie']"
|
||||
]
|
||||
},
|
||||
"execution_count": 3,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"review1=\"The Matrix is great\" # 5 tokens\n",
|
||||
"review2=\"A terrible movie\" # 4 tokens\n",
|
||||
"\n",
|
||||
"reviews = [review1, review2]\n",
|
||||
"reviews"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "d5c81860",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### BERT processes Batch inputs to tokens"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 4,
|
||||
"id": "22c86600",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# Initialize BERT tokenizer and model (frozen)\n",
|
||||
"tokenizer = AutoTokenizer.from_pretrained('bert-base-uncased') # Load tokenizer\n",
|
||||
"\n",
|
||||
"# Batch all phrases together\n",
|
||||
"inputs = tokenizer(\n",
|
||||
" reviews, # all texts at once\n",
|
||||
" return_tensors=\"pt\",\n",
|
||||
" padding=True,\n",
|
||||
" truncation=True,\n",
|
||||
" max_length=128\n",
|
||||
")"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 5,
|
||||
"id": "6749e737",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"transformers.tokenization_utils_base.BatchEncoding"
|
||||
]
|
||||
},
|
||||
"execution_count": 5,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"type(inputs)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 6,
|
||||
"id": "15c53ac7",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"torch.Size([2, 6])\n",
|
||||
"torch.Size([2, 6])\n",
|
||||
"torch.Size([2, 6])\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"print(inputs['input_ids'].shape) # torch.Size([batch_size, seq_len])\n",
|
||||
"print(inputs['attention_mask'].shape) # torch.Size([batch_size, seq_len])\n",
|
||||
"print(inputs['token_type_ids'].shape) # torch.Size([batch_size, seq_len])"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "a132bb7a",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### padding when two sentences have different len"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 7,
|
||||
"id": "939aee8a",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"tensor([ 101, 1037, 6659, 3185, 102, 0])\n",
|
||||
"['[CLS]', 'a', 'terrible', 'movie', '[SEP]', '[PAD]']\n"
|
||||
]
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"print(inputs['input_ids'][1]) # Token IDs\n",
|
||||
"print(tokenizer.convert_ids_to_tokens(inputs['input_ids'][1])) # Tokens"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 8,
|
||||
"id": "b3e54773",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"torch.Size([2, 6, 768])"
|
||||
]
|
||||
},
|
||||
"execution_count": 8,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"model = AutoModel.from_pretrained('bert-base-uncased') # Load model for embeddings\n",
|
||||
"model.eval() # Set to evaluation mode (no training)\n",
|
||||
"\n",
|
||||
"with torch.no_grad():\n",
|
||||
" outputs = model(**inputs)\n",
|
||||
"\n",
|
||||
"outputs.last_hidden_state.shape"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "bceda8fe",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Sentences and 3D dimension. Assume\n",
|
||||
"- 3 sentences, \n",
|
||||
"- each sentence has 2 words, \n",
|
||||
"- each word has 5 features, \n",
|
||||
"\n",
|
||||
"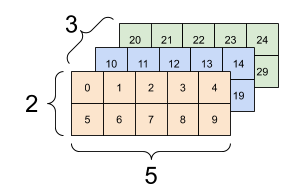\n",
|
||||
"\n",
|
||||
"#### What is dimension of sentence embeddings?\n",
|
||||
"- (3,5)\n",
|
||||
"\n",
|
||||
"`nn.mean(data, dim=1)`"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "20e1cf20",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Sentence embeddings is the average of word embeddings"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 10,
|
||||
"id": "a6eac3e0",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"tensor([[ 0.1656, -0.2764, -0.0298, ..., 0.0087, -0.0636, 0.2763],\n",
|
||||
" [ 0.1329, 0.0747, -0.2481, ..., -0.2341, 0.2315, -0.1357]])"
|
||||
]
|
||||
},
|
||||
"execution_count": 10,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"torch.mean(outputs.last_hidden_state, dim=1)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "bb4e57b5",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### (Optional) What is the potential issue of use the average of word embeddings for sentence embeddings\n",
|
||||
"\n",
|
||||
"The mean includes padding tokens (where attention_mask=0), which can dilute the embedding quality. BERT’s padding tokens produce non-informative embeddings, and averaging them may introduce noise, especially for short reviews with many padding tokens."
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 16,
|
||||
"id": "3ae40e94",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"tensor([[1, 1, 1, 1, 1, 1],\n",
|
||||
" [1, 1, 1, 1, 1, 0]])"
|
||||
]
|
||||
},
|
||||
"execution_count": 16,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"# Masked mean-pooling\n",
|
||||
"attention_mask = inputs['attention_mask'] # (batch_size, seq_len)\n",
|
||||
"attention_mask"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 17,
|
||||
"id": "24ac0d4f",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"tensor([[[1, 1, 1, ..., 1, 1, 1],\n",
|
||||
" [1, 1, 1, ..., 1, 1, 1],\n",
|
||||
" [1, 1, 1, ..., 1, 1, 1],\n",
|
||||
" [1, 1, 1, ..., 1, 1, 1],\n",
|
||||
" [1, 1, 1, ..., 1, 1, 1],\n",
|
||||
" [1, 1, 1, ..., 1, 1, 1]],\n",
|
||||
"\n",
|
||||
" [[1, 1, 1, ..., 1, 1, 1],\n",
|
||||
" [1, 1, 1, ..., 1, 1, 1],\n",
|
||||
" [1, 1, 1, ..., 1, 1, 1],\n",
|
||||
" [1, 1, 1, ..., 1, 1, 1],\n",
|
||||
" [1, 1, 1, ..., 1, 1, 1],\n",
|
||||
" [0, 0, 0, ..., 0, 0, 0]]])"
|
||||
]
|
||||
},
|
||||
"execution_count": 17,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"mask = attention_mask.unsqueeze(-1).expand_as(outputs.last_hidden_state) # (batch_size, seq_len, hidden_dim)\n",
|
||||
"mask"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 18,
|
||||
"id": "97e4b4cb",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"tensor([[[-3.8348e-02, 9.5097e-02, 1.4332e-02, ..., -1.7143e-01,\n",
|
||||
" 1.2736e-01, 3.7117e-01],\n",
|
||||
" [-3.7472e-01, -6.2022e-01, 1.2133e-01, ..., -2.7666e-02,\n",
|
||||
" 1.5813e-01, 1.7997e-01],\n",
|
||||
" [ 7.1591e-01, -1.9231e-01, 1.5049e-01, ..., -4.0711e-01,\n",
|
||||
" 1.9909e-01, 2.7043e-01],\n",
|
||||
" [-3.6584e-01, -3.0518e-01, 5.0851e-04, ..., 1.1478e-01,\n",
|
||||
" -2.0296e-01, 9.8816e-01],\n",
|
||||
" [ 4.8723e-02, -7.2430e-01, -1.8481e-01, ..., 3.9914e-01,\n",
|
||||
" 9.7036e-02, 4.0537e-02],\n",
|
||||
" [ 1.0081e+00, 8.8626e-02, -2.8047e-01, ..., 1.4469e-01,\n",
|
||||
" -7.6039e-01, -1.9232e-01]],\n",
|
||||
"\n",
|
||||
" [[-1.0380e-01, 4.6764e-03, -1.2088e-01, ..., -2.1156e-01,\n",
|
||||
" 2.9962e-01, -1.0300e-02],\n",
|
||||
" [-1.1521e-01, 2.1597e-01, -4.0657e-01, ..., -5.8376e-01,\n",
|
||||
" 8.9380e-01, 4.3011e-01],\n",
|
||||
" [ 4.4965e-01, 2.5421e-01, 2.4422e-02, ..., -3.6552e-01,\n",
|
||||
" 2.4427e-01, -6.5578e-01],\n",
|
||||
" [ 6.2745e-02, 6.8042e-02, -9.1592e-01, ..., -2.1580e-01,\n",
|
||||
" -1.1718e-02, -6.0144e-01],\n",
|
||||
" [ 6.7927e-01, 2.1335e-01, -3.9926e-01, ..., 8.9958e-03,\n",
|
||||
" -5.5664e-01, -1.6044e-01],\n",
|
||||
" [-0.0000e+00, -0.0000e+00, 0.0000e+00, ..., -0.0000e+00,\n",
|
||||
" 0.0000e+00, 0.0000e+00]]])"
|
||||
]
|
||||
},
|
||||
"execution_count": 18,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"masked_embeddings = outputs.last_hidden_state * mask\n",
|
||||
"masked_embeddings"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "a699205c",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": []
|
||||
}
|
||||
],
|
||||
"metadata": {
|
||||
"kernelspec": {
|
||||
"display_name": "Python 3",
|
||||
"language": "python",
|
||||
"name": "python3"
|
||||
},
|
||||
"language_info": {
|
||||
"codemirror_mode": {
|
||||
"name": "ipython",
|
||||
"version": 3
|
||||
},
|
||||
"file_extension": ".py",
|
||||
"mimetype": "text/x-python",
|
||||
"name": "python",
|
||||
"nbconvert_exporter": "python",
|
||||
"pygments_lexer": "ipython3",
|
||||
"version": "3.13.2"
|
||||
}
|
||||
},
|
||||
"nbformat": 4,
|
||||
"nbformat_minor": 5
|
||||
}
|
||||
@@ -2,7 +2,7 @@
|
||||
"cells": [
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 30,
|
||||
"execution_count": 1,
|
||||
"id": "18cc9c99",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
@@ -24,7 +24,7 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 31,
|
||||
"execution_count": 2,
|
||||
"id": "d0b0e4d3",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
@@ -98,7 +98,7 @@
|
||||
"4 5 Hated The Matrix; terrible pacing and a story ... negative"
|
||||
]
|
||||
},
|
||||
"execution_count": 31,
|
||||
"execution_count": 2,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
@@ -111,7 +111,7 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 32,
|
||||
"execution_count": 3,
|
||||
"id": "e9c58e58",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
@@ -124,7 +124,7 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 33,
|
||||
"execution_count": 4,
|
||||
"id": "36733cc8",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
@@ -174,7 +174,7 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 34,
|
||||
"execution_count": 5,
|
||||
"id": "068f7cc3",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
@@ -215,7 +215,7 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 35,
|
||||
"execution_count": 6,
|
||||
"id": "33f8d62c",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
@@ -225,7 +225,7 @@
|
||||
"torch.Size([19, 768])"
|
||||
]
|
||||
},
|
||||
"execution_count": 35,
|
||||
"execution_count": 6,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
@@ -236,7 +236,7 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 36,
|
||||
"execution_count": 7,
|
||||
"id": "7a5d1681",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
@@ -275,28 +275,44 @@
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "ad411bb3",
|
||||
"execution_count": 8,
|
||||
"id": "4dea9168",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
{
|
||||
"ename": "ValueError",
|
||||
"evalue": "text input must be of type `str` (single example), `List[str]` (batch or single pretokenized example) or `List[List[str]]` (batch of pretokenized examples).",
|
||||
"output_type": "error",
|
||||
"traceback": [
|
||||
"\u001b[31m---------------------------------------------------------------------------\u001b[39m",
|
||||
"\u001b[31mValueError\u001b[39m Traceback (most recent call last)",
|
||||
"\u001b[36mCell\u001b[39m\u001b[36m \u001b[39m\u001b[32mIn[37]\u001b[39m\u001b[32m, line 2\u001b[39m\n\u001b[32m 1\u001b[39m \u001b[38;5;66;03m# Batch all phrases together\u001b[39;00m\n\u001b[32m----> \u001b[39m\u001b[32m2\u001b[39m inputs = \u001b[43mtokenizer\u001b[49m\u001b[43m(\u001b[49m\n\u001b[32m 3\u001b[39m \u001b[43m \u001b[49m\u001b[43mdf_reviews\u001b[49m\u001b[43m[\u001b[49m\u001b[33;43m'\u001b[39;49m\u001b[33;43mphrase\u001b[39;49m\u001b[33;43m'\u001b[39;49m\u001b[43m]\u001b[49m\u001b[43m.\u001b[49m\u001b[43mtolist\u001b[49m\u001b[43m,\u001b[49m\u001b[43m \u001b[49m\u001b[38;5;66;43;03m# all texts at once\u001b[39;49;00m\n\u001b[32m 4\u001b[39m \u001b[43m \u001b[49m\u001b[43mreturn_tensors\u001b[49m\u001b[43m=\u001b[49m\u001b[33;43m\"\u001b[39;49m\u001b[33;43mpt\u001b[39;49m\u001b[33;43m\"\u001b[39;49m\u001b[43m,\u001b[49m\n\u001b[32m 5\u001b[39m \u001b[43m \u001b[49m\u001b[43mpadding\u001b[49m\u001b[43m=\u001b[49m\u001b[38;5;28;43;01mTrue\u001b[39;49;00m\u001b[43m,\u001b[49m\n\u001b[32m 6\u001b[39m \u001b[43m \u001b[49m\u001b[43mtruncation\u001b[49m\u001b[43m=\u001b[49m\u001b[38;5;28;43;01mTrue\u001b[39;49;00m\u001b[43m,\u001b[49m\n\u001b[32m 7\u001b[39m \u001b[43m \u001b[49m\u001b[43mmax_length\u001b[49m\u001b[43m=\u001b[49m\u001b[32;43m128\u001b[39;49m\n\u001b[32m 8\u001b[39m \u001b[43m)\u001b[49m\n\u001b[32m 10\u001b[39m \u001b[38;5;28;01mwith\u001b[39;00m torch.no_grad():\n\u001b[32m 11\u001b[39m outputs = model(**inputs)\n",
|
||||
"\u001b[36mFile \u001b[39m\u001b[32mi:\\conda_envs\\reinforcement\\Lib\\site-packages\\transformers\\tokenization_utils_base.py:2887\u001b[39m, in \u001b[36mPreTrainedTokenizerBase.__call__\u001b[39m\u001b[34m(self, text, text_pair, text_target, text_pair_target, add_special_tokens, padding, truncation, max_length, stride, is_split_into_words, pad_to_multiple_of, padding_side, return_tensors, return_token_type_ids, return_attention_mask, return_overflowing_tokens, return_special_tokens_mask, return_offsets_mapping, return_length, verbose, **kwargs)\u001b[39m\n\u001b[32m 2885\u001b[39m \u001b[38;5;28;01mif\u001b[39;00m \u001b[38;5;129;01mnot\u001b[39;00m \u001b[38;5;28mself\u001b[39m._in_target_context_manager:\n\u001b[32m 2886\u001b[39m \u001b[38;5;28mself\u001b[39m._switch_to_input_mode()\n\u001b[32m-> \u001b[39m\u001b[32m2887\u001b[39m encodings = \u001b[38;5;28;43mself\u001b[39;49m\u001b[43m.\u001b[49m\u001b[43m_call_one\u001b[49m\u001b[43m(\u001b[49m\u001b[43mtext\u001b[49m\u001b[43m=\u001b[49m\u001b[43mtext\u001b[49m\u001b[43m,\u001b[49m\u001b[43m \u001b[49m\u001b[43mtext_pair\u001b[49m\u001b[43m=\u001b[49m\u001b[43mtext_pair\u001b[49m\u001b[43m,\u001b[49m\u001b[43m \u001b[49m\u001b[43m*\u001b[49m\u001b[43m*\u001b[49m\u001b[43mall_kwargs\u001b[49m\u001b[43m)\u001b[49m\n\u001b[32m 2888\u001b[39m \u001b[38;5;28;01mif\u001b[39;00m text_target \u001b[38;5;129;01mis\u001b[39;00m \u001b[38;5;129;01mnot\u001b[39;00m \u001b[38;5;28;01mNone\u001b[39;00m:\n\u001b[32m 2889\u001b[39m \u001b[38;5;28mself\u001b[39m._switch_to_target_mode()\n",
|
||||
"\u001b[36mFile \u001b[39m\u001b[32mi:\\conda_envs\\reinforcement\\Lib\\site-packages\\transformers\\tokenization_utils_base.py:2947\u001b[39m, in \u001b[36mPreTrainedTokenizerBase._call_one\u001b[39m\u001b[34m(self, text, text_pair, add_special_tokens, padding, truncation, max_length, stride, is_split_into_words, pad_to_multiple_of, padding_side, return_tensors, return_token_type_ids, return_attention_mask, return_overflowing_tokens, return_special_tokens_mask, return_offsets_mapping, return_length, verbose, split_special_tokens, **kwargs)\u001b[39m\n\u001b[32m 2944\u001b[39m \u001b[38;5;28;01mreturn\u001b[39;00m \u001b[38;5;28;01mFalse\u001b[39;00m\n\u001b[32m 2946\u001b[39m \u001b[38;5;28;01mif\u001b[39;00m \u001b[38;5;129;01mnot\u001b[39;00m _is_valid_text_input(text):\n\u001b[32m-> \u001b[39m\u001b[32m2947\u001b[39m \u001b[38;5;28;01mraise\u001b[39;00m \u001b[38;5;167;01mValueError\u001b[39;00m(\n\u001b[32m 2948\u001b[39m \u001b[33m\"\u001b[39m\u001b[33mtext input must be of type `str` (single example), `List[str]` (batch or single pretokenized example) \u001b[39m\u001b[33m\"\u001b[39m\n\u001b[32m 2949\u001b[39m \u001b[33m\"\u001b[39m\u001b[33mor `List[List[str]]` (batch of pretokenized examples).\u001b[39m\u001b[33m\"\u001b[39m\n\u001b[32m 2950\u001b[39m )\n\u001b[32m 2952\u001b[39m \u001b[38;5;28;01mif\u001b[39;00m text_pair \u001b[38;5;129;01mis\u001b[39;00m \u001b[38;5;129;01mnot\u001b[39;00m \u001b[38;5;28;01mNone\u001b[39;00m \u001b[38;5;129;01mand\u001b[39;00m \u001b[38;5;129;01mnot\u001b[39;00m _is_valid_text_input(text_pair):\n\u001b[32m 2953\u001b[39m \u001b[38;5;28;01mraise\u001b[39;00m \u001b[38;5;167;01mValueError\u001b[39;00m(\n\u001b[32m 2954\u001b[39m \u001b[33m\"\u001b[39m\u001b[33mtext input must be of type `str` (single example), `List[str]` (batch or single pretokenized example) \u001b[39m\u001b[33m\"\u001b[39m\n\u001b[32m 2955\u001b[39m \u001b[33m\"\u001b[39m\u001b[33mor `List[List[str]]` (batch of pretokenized examples).\u001b[39m\u001b[33m\"\u001b[39m\n\u001b[32m 2956\u001b[39m )\n",
|
||||
"\u001b[31mValueError\u001b[39m: text input must be of type `str` (single example), `List[str]` (batch or single pretokenized example) or `List[List[str]]` (batch of pretokenized examples)."
|
||||
]
|
||||
"data": {
|
||||
"text/plain": [
|
||||
"transformers.tokenization_utils_base.BatchEncoding"
|
||||
]
|
||||
},
|
||||
"execution_count": 8,
|
||||
"metadata": {},
|
||||
"output_type": "execute_result"
|
||||
}
|
||||
],
|
||||
"source": [
|
||||
"# Batch all phrases together\n",
|
||||
"inputs = tokenizer(\n",
|
||||
" list(df_reviews['phrase']), # all texts at once\n",
|
||||
" df_reviews['phrase'].tolist(), # all texts at once\n",
|
||||
" return_tensors=\"pt\",\n",
|
||||
" padding=True,\n",
|
||||
" truncation=True,\n",
|
||||
" max_length=128\n",
|
||||
")\n",
|
||||
"\n",
|
||||
"type(inputs)"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": 9,
|
||||
"id": "ad411bb3",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": [
|
||||
"# Batch all phrases together\n",
|
||||
"inputs = tokenizer(\n",
|
||||
" df_reviews['phrase'].tolist(), # all texts at once\n",
|
||||
" return_tensors=\"pt\",\n",
|
||||
" padding=True,\n",
|
||||
" truncation=True,\n",
|
||||
@@ -314,9 +330,23 @@
|
||||
"review_labels = torch.tensor(labels, dtype=torch.long)\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "553fbfff",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"| Component | Meaning |\n",
|
||||
"| ------------------------------- | ------------------------------------------------------------------------------------ |\n",
|
||||
"| `review_embeddings` | BERT-encoded sentence embeddings (shape: `(n, 768)`), used as features. |\n",
|
||||
"| `review_labels` | Ground truth sentiment labels (e.g., positive/negative/neutral). |\n",
|
||||
"| `df_reviews['phrase'].tolist()` | Original text phrases (so you can refer back to the raw text later). |\n",
|
||||
"| `test_size=0.2` | 20% of the data will go into the **test set**, and 80% into the **train set**. |\n",
|
||||
"| `random_state=42` | Ensures **reproducibility** — you'll get the same split every time you run the code. |\n"
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"execution_count": 10,
|
||||
"id": "cfa993e5",
|
||||
"metadata": {},
|
||||
"outputs": [
|
||||
@@ -324,21 +354,21 @@
|
||||
"name": "stdout",
|
||||
"output_type": "stream",
|
||||
"text": [
|
||||
"Epoch 1, Loss: 1.1128\n",
|
||||
"Epoch 2, Loss: 1.0926\n",
|
||||
"Epoch 3, Loss: 1.0726\n",
|
||||
"Epoch 4, Loss: 1.0530\n",
|
||||
"Epoch 5, Loss: 1.0337\n",
|
||||
"Epoch 6, Loss: 1.0149\n",
|
||||
"Epoch 7, Loss: 0.9966\n",
|
||||
"Epoch 8, Loss: 0.9793\n",
|
||||
"Epoch 9, Loss: 0.9629\n",
|
||||
"Epoch 10, Loss: 0.9476\n",
|
||||
"Epoch 1, Loss: 1.1348\n",
|
||||
"Epoch 2, Loss: 1.1101\n",
|
||||
"Epoch 3, Loss: 1.0867\n",
|
||||
"Epoch 4, Loss: 1.0647\n",
|
||||
"Epoch 5, Loss: 1.0440\n",
|
||||
"Epoch 6, Loss: 1.0245\n",
|
||||
"Epoch 7, Loss: 1.0061\n",
|
||||
"Epoch 8, Loss: 0.9887\n",
|
||||
"Epoch 9, Loss: 0.9722\n",
|
||||
"Epoch 10, Loss: 0.9566\n",
|
||||
"\n",
|
||||
"Sentiment Prediction Results (Test Set):\n",
|
||||
"ID | Review Text | Actual | Predicted\n",
|
||||
"---|-----------------------------------------|-----------|----------\n",
|
||||
"5 | Watched The Matrix, it’s fine, nothing special. #cinema | neutral | positive\n",
|
||||
"5 | Watched The Matrix, it’s fine, nothing special. #cinema | neutral | negative\n",
|
||||
"13 | The Matrix is awesome, iconic and thrilling! #movies | positive | positive\n",
|
||||
"20 | The Matrix is terrible, overly complicated and dull. #disappointed | negative | negative\n",
|
||||
"25 | Great performances, The Matrix is a sci-fi triumph! #scifi | positive | positive\n",
|
||||
@@ -395,11 +425,20 @@
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "code",
|
||||
"execution_count": null,
|
||||
"id": "7c1d50bc",
|
||||
"cell_type": "markdown",
|
||||
"id": "d048fe1d",
|
||||
"metadata": {},
|
||||
"source": [
|
||||
"### Your work\n",
|
||||
"- Calculate Accuray\n",
|
||||
"- F1 scores\n",
|
||||
" "
|
||||
]
|
||||
},
|
||||
{
|
||||
"cell_type": "markdown",
|
||||
"id": "9f6257f6",
|
||||
"metadata": {},
|
||||
"outputs": [],
|
||||
"source": []
|
||||
}
|
||||
],
|
||||
Binary file not shown.
BIN
lectures/12_Transformer/0_Transformer.pptx
Normal file
BIN
lectures/12_Transformer/0_Transformer.pptx
Normal file
Binary file not shown.
743
lectures/12_Transformer/0_word_embeddings.ipynb
Normal file
743
lectures/12_Transformer/0_word_embeddings.ipynb
Normal file
File diff suppressed because one or more lines are too long
Reference in New Issue
Block a user