diff --git a/README.md b/README.md
index 420c26c..d6ffe74 100644
--- a/README.md
+++ b/README.md
@@ -57,12 +57,39 @@ Alternatively, you can view this and other files on GitHub at [https://github.co
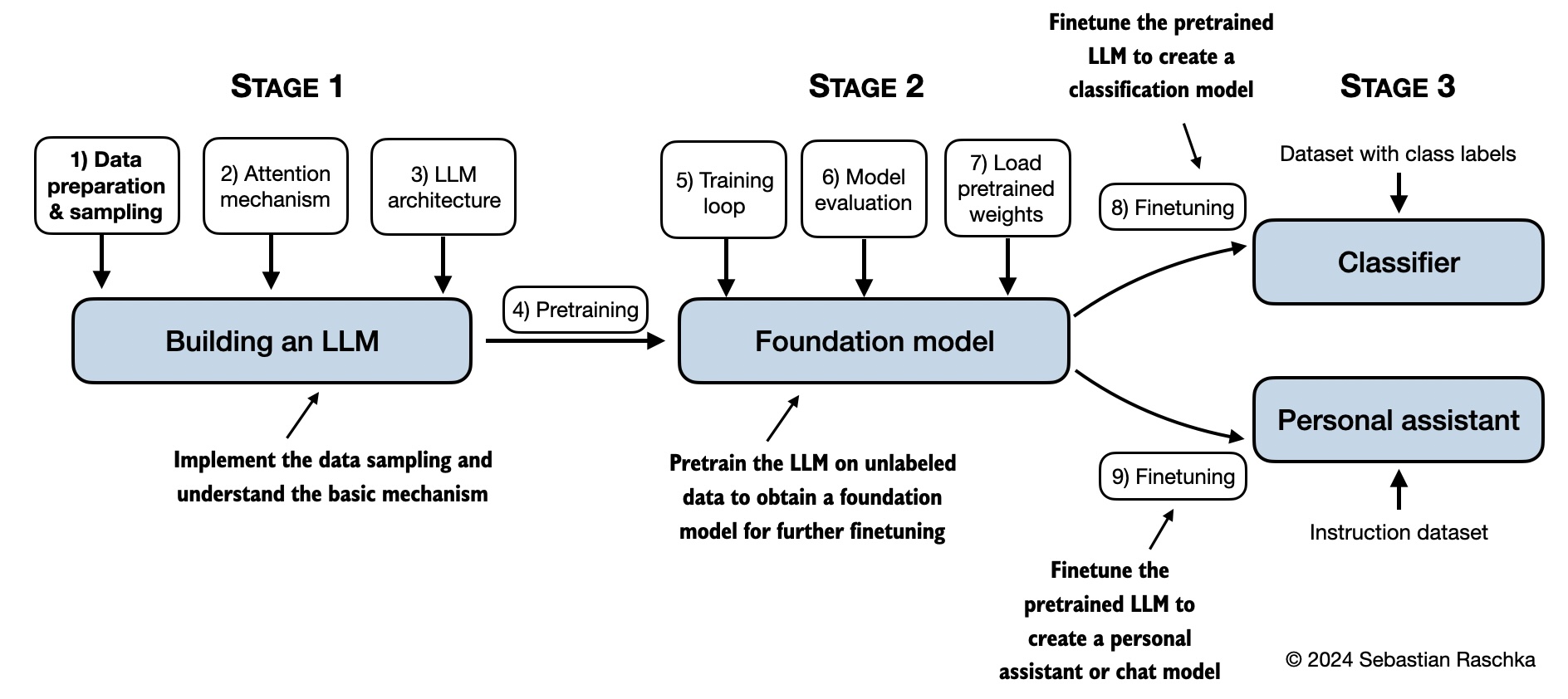
Shown below is a mental model summarizing the contents covered in this book.
- +
+
+## Bonus Material
+
+Several folders contain optional materials as a bonus for interested readers:
+
+- **Appendix A:**
+ - [Python Setup Tips](appendix-A/01_optional-python-setup-preferences)
+ - [Installing Libraries Used In This Book](appendix-A/02_installing-python-libraries)
+ - [Docker Environment Setup Guide](appendix-A/04_optional-docker-environment)
+
+- **Chapter 2:**
+ - [Comparing Various Byte Pair Encoding (BPE) Implementations](ch02/02_bonus_bytepair-encoder)
+ - [Understanding the Difference Between Embedding Layers and Linear Layers](ch02/03_bonus_embedding-vs-matmul)
+
+- **Chapter 3:**
+ - [Comparing Efficient Multi-Head Attention Implementations](ch03/02_bonus_efficient-multihead-attention/mha-implementations.ipynb)
+
+- **Chapter 5:**
+ - [Alternative Weight Loading from Hugging Face Model Hub using Transformers](ch05/02_alternative_weight_loading/weight-loading-hf-transformers.ipynb)
+ - [Pretraining GPT on the Project Gutenberg Dataset](ch05/03_bonus_pretraining_on_gutenberg)
+ - [Adding Bells and Whistles to the Training Loop](ch05/04_learning_rate_schedulers)
+ - [Optimizing Hyperparameters for Pretraining](05_bonus_hparam_tuning)
+
+
+
+
+
+
### Reader Projects and Showcase
Below are interesting projects by readers of the *Build A Large Language Model From Scratch* book:
diff --git a/appendix-A/02_installing-python-libraries/README.md b/appendix-A/02_installing-python-libraries/README.md
index be97c76..ee567c9 100644
--- a/appendix-A/02_installing-python-libraries/README.md
+++ b/appendix-A/02_installing-python-libraries/README.md
@@ -1,4 +1,4 @@
-# Libraries Used In This Book
+# Installing Libraries Used In This Book
This document provides more information on double-checking your installed Python version and packages. (Please see the [../01_optional-python-setup-preferences](../01_optional-python-setup-preferences) folder for more information on installing Python and Python packages.)
diff --git a/appendix-D/01_main-chapter-code/appendix-D.ipynb b/appendix-D/01_main-chapter-code/appendix-D.ipynb
index 1710394..a5170e1 100644
--- a/appendix-D/01_main-chapter-code/appendix-D.ipynb
+++ b/appendix-D/01_main-chapter-code/appendix-D.ipynb
@@ -750,7 +750,7 @@
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
- "version": "3.10.6"
+ "version": "3.10.12"
}
},
"nbformat": 4,
diff --git a/ch02/02_bonus_bytepair-encoder/compare-bpe-tiktoken.ipynb b/ch02/02_bonus_bytepair-encoder/compare-bpe-tiktoken.ipynb
index 3a898ef..133c063 100644
--- a/ch02/02_bonus_bytepair-encoder/compare-bpe-tiktoken.ipynb
+++ b/ch02/02_bonus_bytepair-encoder/compare-bpe-tiktoken.ipynb
@@ -29,12 +29,23 @@
"# pip install -r requirements-extra.txt"
]
},
+ {
+ "cell_type": "markdown",
+ "id": "737c59bb-5922-46fc-a787-1369d70925b4",
+ "metadata": {},
+ "source": [
+ "# Comparing Various Byte Pair Encoding (BPE) Implementations"
+ ]
+ },
{
"cell_type": "markdown",
"id": "a9adc3bf-353c-411e-a471-0e92786e7103",
"metadata": {},
"source": [
- "# Using BytePair encodding from `tiktoken`"
+ "
\n",
+ " \n",
+ "\n",
+ "## Using BPE from `tiktoken`"
]
},
{
@@ -134,7 +145,10 @@
"id": "6a0b5d4f-2af9-40de-828c-063c4243e771",
"metadata": {},
"source": [
- "# Using the original Byte-pair encoding implementation used in GPT-2"
+ "
\n",
+ " \n",
+ "\n",
+ "## Using the original BPE implementation used in GPT-2"
]
},
{
@@ -221,7 +235,10 @@
"id": "4f63e8c6-707c-4d66-bcf8-dd790647cc86",
"metadata": {},
"source": [
- "# Using the BytePair Tokenizer in Hugging Face transformers"
+ "
\n",
+ " \n",
+ "\n",
+ "## Using the BPE via Hugging Face transformers"
]
},
{
@@ -356,7 +373,10 @@
"id": "907a1ade-3401-4f2e-9017-7f58a60cbd98",
"metadata": {},
"source": [
- "# A quick performance benchmark"
+ "
\n",
+ " \n",
+ "\n",
+ "## A quick performance benchmark"
]
},
{
@@ -466,7 +486,7 @@
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
- "version": "3.10.6"
+ "version": "3.10.12"
}
},
"nbformat": 4,
diff --git a/ch02/03_bonus_embedding-vs-matmul/embeddings-and-linear-layers.ipynb b/ch02/03_bonus_embedding-vs-matmul/embeddings-and-linear-layers.ipynb
index 97d061e..9fb4c66 100644
--- a/ch02/03_bonus_embedding-vs-matmul/embeddings-and-linear-layers.ipynb
+++ b/ch02/03_bonus_embedding-vs-matmul/embeddings-and-linear-layers.ipynb
@@ -5,7 +5,7 @@
"id": "063850ab-22b0-4838-b53a-9bb11757d9d0",
"metadata": {},
"source": [
- "# Embedding Layers and Linear Layers"
+ "# Understanding the Difference Between Embedding Layers and Linear Layers"
]
},
{
@@ -42,6 +42,9 @@
"id": "a7895a66-7f69-4f62-9361-5c9da2eb76ef",
"metadata": {},
"source": [
+ "
\n",
+ " \n",
+ "\n",
"## Using nn.Embedding"
]
},
@@ -260,6 +263,9 @@
"id": "f0fe863b-d6a3-48f3-ace5-09ecd0eb7b59",
"metadata": {},
"source": [
+ "
\n",
+ " \n",
+ "\n",
"## Using nn.Linear"
]
},
@@ -471,7 +477,7 @@
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
- "version": "3.10.6"
+ "version": "3.10.12"
}
},
"nbformat": 4,
diff --git a/ch03/02_bonus_efficient-multihead-attention/mha-implementations.ipynb b/ch03/02_bonus_efficient-multihead-attention/mha-implementations.ipynb
index 9e5e460..5757807 100644
--- a/ch03/02_bonus_efficient-multihead-attention/mha-implementations.ipynb
+++ b/ch03/02_bonus_efficient-multihead-attention/mha-implementations.ipynb
@@ -18,7 +18,7 @@
"id": "6f678e62-7bcb-4405-86ae-dce94f494303"
},
"source": [
- "# Efficient Multi-Head Attention Implementations"
+ "# Comparing Efficient Multi-Head Attention Implementations"
]
},
{
@@ -73,6 +73,9 @@
"id": "2f9bb1b6-a1e5-4e0a-884d-0f31b374a8d6"
},
"source": [
+ "
\n",
+ " \n",
+ "\n",
"## 1) CausalAttention MHA wrapper class from chapter 3"
]
},
@@ -119,6 +122,9 @@
"id": "21930804-b327-40b1-8e63-94dcad39ce7b"
},
"source": [
+ "
\n",
+ " \n",
+ "\n",
"## 2) The multi-head attention class from chapter 3"
]
},
@@ -165,6 +171,9 @@
"id": "73cd11da-ea3b-4081-b483-c4965dfefbc4"
},
"source": [
+ "
\n",
+ " \n",
+ "\n",
"## 3) An alternative multi-head attention with combined weights"
]
},
@@ -286,6 +295,9 @@
"id": "48a042d3-ee78-4c29-bf63-d92fe6706632"
},
"source": [
+ "
\n",
+ " \n",
+ "\n",
"## 4) Multihead attention with PyTorch's scaled dot product attention"
]
},
@@ -393,6 +405,9 @@
"id": "351c318f-4835-4d74-8d58-a070222447c4"
},
"source": [
+ "
\n",
+ " \n",
+ "\n",
"## 5) Using PyTorch's torch.nn.MultiheadAttention"
]
},
@@ -488,6 +503,9 @@
"id": "a3953bff-1056-4de2-bfd1-dfccf659eee4"
},
"source": [
+ "
\n",
+ " \n",
+ "\n",
"## 6) Using PyTorch's torch.nn.MultiheadAttention with `scaled_dot_product_attention`"
]
},
@@ -548,6 +566,9 @@
"id": "8877de71-f84f-4f6d-bc87-7552013b6301"
},
"source": [
+ "
\n",
+ " \n",
+ "\n",
"## Quick speed comparison (M3 Macbook Air CPU)"
]
},
@@ -706,6 +727,9 @@
"id": "a78ff594-6cc2-496d-a302-789fa104c3c9"
},
"source": [
+ "
\n",
+ " \n",
+ "\n",
"## Quick speed comparison (Nvidia A100 GPU)"
]
},
@@ -866,6 +890,10 @@
"id": "dabc6575-0316-4640-a729-e616d5c17b73"
},
"source": [
+ "
\n",
+ " \n",
+ "\n",
+ "\n",
"## Speed comparison (Nvidia A100 GPU) with warmup"
]
},
@@ -1003,7 +1031,7 @@
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
- "version": "3.10.6"
+ "version": "3.10.12"
}
},
"nbformat": 4,
diff --git a/ch05/04_learning_rate_schedulers/README.md b/ch05/04_learning_rate_schedulers/README.md
new file mode 100644
index 0000000..af310da
--- /dev/null
+++ b/ch05/04_learning_rate_schedulers/README.md
@@ -0,0 +1,5 @@
+# Adding Bells and Whistles to the Training Loop
+
+The main chapter used a relatively simple training function to keep the code readable and fit Chapter 5 within the page limits. Optionally, we can add a linear warm-up, a cosine decay schedule, and gradient clipping to improve the training stability and convergence.
+
+You can find the code for this more sophisticated training function in [Appendix D: Adding Bells and Whistles to the Training Loop](../../appendix-D/01_main-chapter-code/appendix-D.ipynb).
\ No newline at end of file
diff --git a/ch05/05_bonus_hparam_tuning/README.md b/ch05/05_bonus_hparam_tuning/README.md
new file mode 100644
index 0000000..b8ceb83
--- /dev/null
+++ b/ch05/05_bonus_hparam_tuning/README.md
@@ -0,0 +1,10 @@
+# Optimizing Hyperparameters for Pretraining
+
+The [hparam_search.py](hparam_search.py) is script based on the extended training function in [
+Appendix D: Adding Bells and Whistles to the Training Loop](../appendix-D/01_main-chapter-code/appendix-D.ipynb) to find optimal hyperparameters via grid search
+
+The [hparam_search.py](hparam_search.py) script, based on the extended training function in [
+Appendix D: Adding Bells and Whistles to the Training Loop](../appendix-D/01_main-chapter-code/appendix-D.ipynb), is designed to find optimal hyperparameters via grid search.
+
+>[!NOTE]
+This script will take a long time to run. You may want to reduce the number of hyperparameter configurations explored in the `HPARAM_GRID` dictionary at the top.
\ No newline at end of file
diff --git a/ch05/04_bonus_hparam_tuning/hparam_search.py b/ch05/05_bonus_hparam_tuning/hparam_search.py
similarity index 100%
rename from ch05/04_bonus_hparam_tuning/hparam_search.py
rename to ch05/05_bonus_hparam_tuning/hparam_search.py
diff --git a/ch05/04_bonus_hparam_tuning/previous_chapters.py b/ch05/05_bonus_hparam_tuning/previous_chapters.py
similarity index 100%
rename from ch05/04_bonus_hparam_tuning/previous_chapters.py
rename to ch05/05_bonus_hparam_tuning/previous_chapters.py
diff --git a/ch05/04_bonus_hparam_tuning/the-verdict.txt b/ch05/05_bonus_hparam_tuning/the-verdict.txt
similarity index 100%
rename from ch05/04_bonus_hparam_tuning/the-verdict.txt
rename to ch05/05_bonus_hparam_tuning/the-verdict.txt
diff --git a/ch05/README.md b/ch05/README.md
index 847c99e..150c618 100644
--- a/ch05/README.md
+++ b/ch05/README.md
@@ -3,4 +3,5 @@
- [01_main-chapter-code](01_main-chapter-code) contains the main chapter code
- [02_alternative_weight_loading](02_alternative_weight_loading) contains code to load the GPT model weights from alternative places in case the model weights become unavailable from OpenAI
- [03_bonus_pretraining_on_gutenberg](03_bonus_pretraining_on_gutenberg) contains code to pretrain the LLM longer on the whole corpus of books from Project Gutenberg
-- [04_hparam_tuning](04_hparam_tuning) contains an optional hyperparameter tuning script
\ No newline at end of file
+- [04_learning_rate_schedulers] contains code implementing a more sophisticated training function including learning rate schedulers and gradient clipping
+- [05_hparam_tuning](05_hparam_tuning) contains an optional hyperparameter tuning script
\ No newline at end of file