diff --git a/README.md b/README.md
index fabf0fa..e7fb85f 100644
--- a/README.md
+++ b/README.md
@@ -57,5 +57,5 @@ Alternatively, you can view this and other files on GitHub at [https://github.co
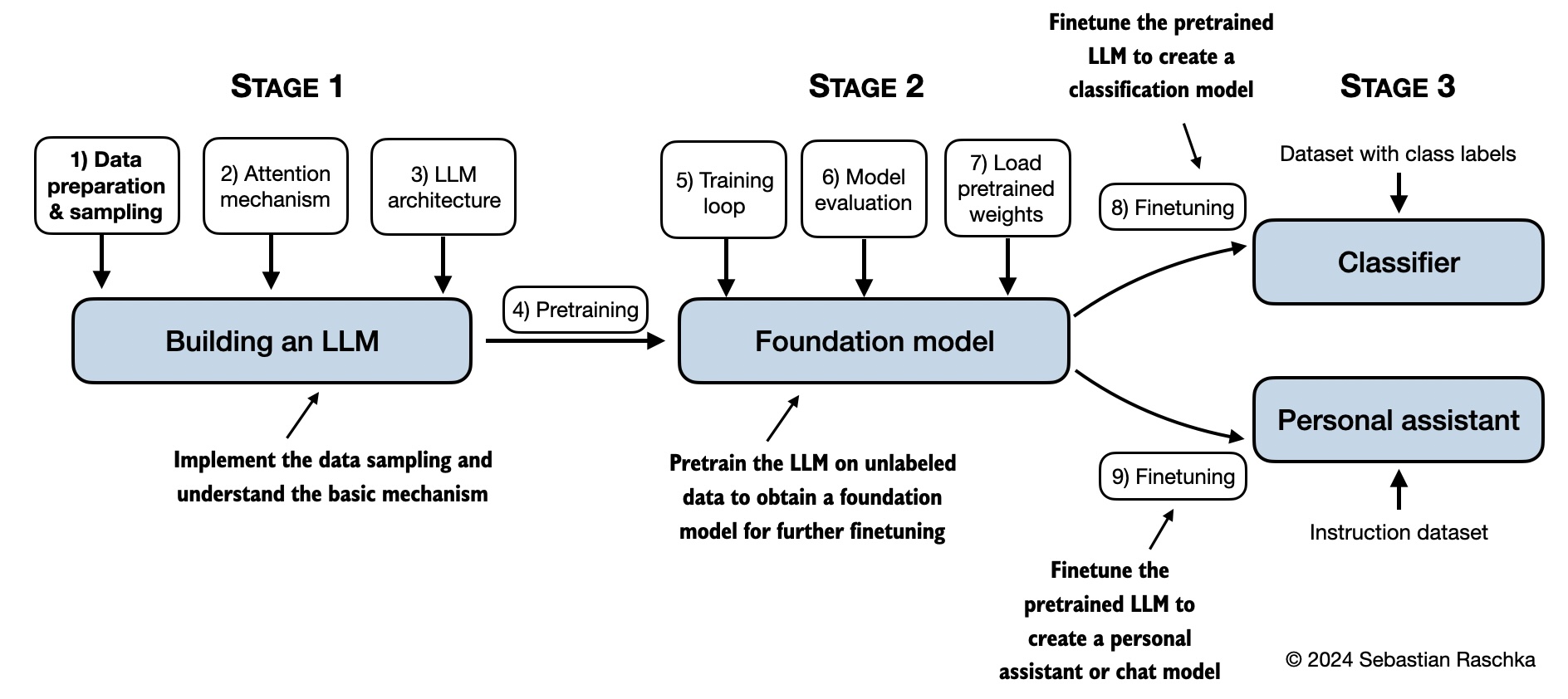
Shown below is a mental model summarizing the contents covered in this book.
- +
+ diff --git a/ch02/01_main-chapter-code/ch02.ipynb b/ch02/01_main-chapter-code/ch02.ipynb
index 82ad59b..6c6caaa 100644
--- a/ch02/01_main-chapter-code/ch02.ipynb
+++ b/ch02/01_main-chapter-code/ch02.ipynb
@@ -41,12 +41,20 @@
"print(\"tiktoken version:\", version(\"tiktoken\"))"
]
},
+ {
+ "cell_type": "markdown",
+ "id": "5a42fbfd-e3c2-43c2-bc12-f5f870a0b10a",
+ "metadata": {},
+ "source": [
+ "- This chapter covers data preparation and sampling to get input data \"ready\" for the LLM"
+ ]
+ },
{
"cell_type": "markdown",
"id": "628b2922-594d-4ff9-bd82-04f1ebdf41f5",
"metadata": {},
"source": [
- "
diff --git a/ch02/01_main-chapter-code/ch02.ipynb b/ch02/01_main-chapter-code/ch02.ipynb
index 82ad59b..6c6caaa 100644
--- a/ch02/01_main-chapter-code/ch02.ipynb
+++ b/ch02/01_main-chapter-code/ch02.ipynb
@@ -41,12 +41,20 @@
"print(\"tiktoken version:\", version(\"tiktoken\"))"
]
},
+ {
+ "cell_type": "markdown",
+ "id": "5a42fbfd-e3c2-43c2-bc12-f5f870a0b10a",
+ "metadata": {},
+ "source": [
+ "- This chapter covers data preparation and sampling to get input data \"ready\" for the LLM"
+ ]
+ },
{
"cell_type": "markdown",
"id": "628b2922-594d-4ff9-bd82-04f1ebdf41f5",
"metadata": {},
"source": [
- " "
+ "
"
+ " "
]
},
{
@@ -57,14 +65,6 @@
"## 2.1 Understanding word embeddings"
]
},
- {
- "cell_type": "markdown",
- "id": "ba08d16f-f237-4166-bf89-0e9fe703e7b4",
- "metadata": {},
- "source": [
- "
"
]
},
{
@@ -57,14 +65,6 @@
"## 2.1 Understanding word embeddings"
]
},
- {
- "cell_type": "markdown",
- "id": "ba08d16f-f237-4166-bf89-0e9fe703e7b4",
- "metadata": {},
- "source": [
- " "
- ]
- },
{
"cell_type": "markdown",
"id": "0b6816ae-e927-43a9-b4dd-e47a9b0e1cf6",
@@ -73,12 +73,37 @@
"- No code in this section"
]
},
+ {
+ "cell_type": "markdown",
+ "id": "4f69dab7-a433-427a-9e5b-b981062d6296",
+ "metadata": {},
+ "source": [
+ "- There are any forms of embeddings; we focus on text embeddings in this book"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "ba08d16f-f237-4166-bf89-0e9fe703e7b4",
+ "metadata": {},
+ "source": [
+ "
"
- ]
- },
{
"cell_type": "markdown",
"id": "0b6816ae-e927-43a9-b4dd-e47a9b0e1cf6",
@@ -73,12 +73,37 @@
"- No code in this section"
]
},
+ {
+ "cell_type": "markdown",
+ "id": "4f69dab7-a433-427a-9e5b-b981062d6296",
+ "metadata": {},
+ "source": [
+ "- There are any forms of embeddings; we focus on text embeddings in this book"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "ba08d16f-f237-4166-bf89-0e9fe703e7b4",
+ "metadata": {},
+ "source": [
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "288c4faf-b93a-4616-9276-7a4aa4b5e9ba",
+ "metadata": {},
+ "source": [
+ "- LLMs work embeddings in high-dimensional spaces (i.e., thousands of dimensions)\n",
+ "- Since we can't visualize such high-dimensional spaces (we humans think in 1, 2, or 3 dimensions), the figure below illustrates a 2-dimensipnal embedding space"
+ ]
+ },
{
"cell_type": "markdown",
"id": "d6b80160-1f10-4aad-a85e-9c79444de9e6",
"metadata": {},
"source": [
- "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "288c4faf-b93a-4616-9276-7a4aa4b5e9ba",
+ "metadata": {},
+ "source": [
+ "- LLMs work embeddings in high-dimensional spaces (i.e., thousands of dimensions)\n",
+ "- Since we can't visualize such high-dimensional spaces (we humans think in 1, 2, or 3 dimensions), the figure below illustrates a 2-dimensipnal embedding space"
+ ]
+ },
{
"cell_type": "markdown",
"id": "d6b80160-1f10-4aad-a85e-9c79444de9e6",
"metadata": {},
"source": [
- " "
+ "
"
+ " "
]
},
{
@@ -89,12 +114,20 @@
"## 2.2 Tokenizing text"
]
},
+ {
+ "cell_type": "markdown",
+ "id": "f9c90731-7dc9-4cd3-8c4a-488e33b48e80",
+ "metadata": {},
+ "source": [
+ "- In this section, we tokenize text, which means breaking text into smaller units, such as individual words and punctuation characters"
+ ]
+ },
{
"cell_type": "markdown",
"id": "09872fdb-9d4e-40c4-949d-52a01a43ec4b",
"metadata": {},
"source": [
- "
"
]
},
{
@@ -89,12 +114,20 @@
"## 2.2 Tokenizing text"
]
},
+ {
+ "cell_type": "markdown",
+ "id": "f9c90731-7dc9-4cd3-8c4a-488e33b48e80",
+ "metadata": {},
+ "source": [
+ "- In this section, we tokenize text, which means breaking text into smaller units, such as individual words and punctuation characters"
+ ]
+ },
{
"cell_type": "markdown",
"id": "09872fdb-9d4e-40c4-949d-52a01a43ec4b",
"metadata": {},
"source": [
- " "
+ "
"
+ " "
]
},
{
@@ -261,7 +294,7 @@
"id": "6cbe9330-b587-4262-be9f-497a84ec0e8a",
"metadata": {},
"source": [
- "
"
]
},
{
@@ -261,7 +294,7 @@
"id": "6cbe9330-b587-4262-be9f-497a84ec0e8a",
"metadata": {},
"source": [
- " "
+ "
"
+ " "
]
},
{
@@ -318,12 +351,20 @@
"## 2.3 Converting tokens into token IDs"
]
},
+ {
+ "cell_type": "markdown",
+ "id": "a5204973-f414-4c0d-87b0-cfec1f06e6ff",
+ "metadata": {},
+ "source": [
+ "- Next, we convert the text tokens into token IDs that we can process via embedding layers later"
+ ]
+ },
{
"cell_type": "markdown",
"id": "177b041d-f739-43b8-bd81-0443ae3a7f8d",
"metadata": {},
"source": [
- "
"
]
},
{
@@ -318,12 +351,20 @@
"## 2.3 Converting tokens into token IDs"
]
},
+ {
+ "cell_type": "markdown",
+ "id": "a5204973-f414-4c0d-87b0-cfec1f06e6ff",
+ "metadata": {},
+ "source": [
+ "- Next, we convert the text tokens into token IDs that we can process via embedding layers later"
+ ]
+ },
{
"cell_type": "markdown",
"id": "177b041d-f739-43b8-bd81-0443ae3a7f8d",
"metadata": {},
"source": [
- " "
+ "
"
+ " "
]
},
{
@@ -444,12 +485,20 @@
" break"
]
},
+ {
+ "cell_type": "markdown",
+ "id": "3b1dc314-351b-476a-9459-0ec9ddc29b19",
+ "metadata": {},
+ "source": [
+ "- Below, we illustrate the tokenization of a short sample text using a small vocabulary:"
+ ]
+ },
{
"cell_type": "markdown",
"id": "67407a9f-0202-4e7c-9ed7-1b3154191ebc",
"metadata": {},
"source": [
- "
"
]
},
{
@@ -444,12 +485,20 @@
" break"
]
},
+ {
+ "cell_type": "markdown",
+ "id": "3b1dc314-351b-476a-9459-0ec9ddc29b19",
+ "metadata": {},
+ "source": [
+ "- Below, we illustrate the tokenization of a short sample text using a small vocabulary:"
+ ]
+ },
{
"cell_type": "markdown",
"id": "67407a9f-0202-4e7c-9ed7-1b3154191ebc",
"metadata": {},
"source": [
- " "
+ "
"
+ " "
]
},
{
@@ -485,12 +534,21 @@
" return text"
]
},
+ {
+ "cell_type": "markdown",
+ "id": "dee7a1e5-b54f-4ca1-87ef-3d663c4ee1e7",
+ "metadata": {},
+ "source": [
+ "- The `encode` function turns text into token IDs\n",
+ "- The `decode` function turns token IDs back into text"
+ ]
+ },
{
"cell_type": "markdown",
"id": "cc21d347-ec03-4823-b3d4-9d686e495617",
"metadata": {},
"source": [
- "
"
]
},
{
@@ -485,12 +534,21 @@
" return text"
]
},
+ {
+ "cell_type": "markdown",
+ "id": "dee7a1e5-b54f-4ca1-87ef-3d663c4ee1e7",
+ "metadata": {},
+ "source": [
+ "- The `encode` function turns text into token IDs\n",
+ "- The `decode` function turns token IDs back into text"
+ ]
+ },
{
"cell_type": "markdown",
"id": "cc21d347-ec03-4823-b3d4-9d686e495617",
"metadata": {},
"source": [
- " "
+ "
"
+ " "
]
},
{
@@ -582,12 +640,20 @@
"## 2.4 Adding special context tokens"
]
},
+ {
+ "cell_type": "markdown",
+ "id": "863d6d15-a3e2-44e0-b384-bb37f17cf443",
+ "metadata": {},
+ "source": [
+ "- It's useful to add some \"special\" tokens for unknown words and to denote the end of a text"
+ ]
+ },
{
"cell_type": "markdown",
"id": "aa7fc96c-e1fd-44fb-b7f5-229d7c7922a4",
"metadata": {},
"source": [
- "
"
]
},
{
@@ -582,12 +640,20 @@
"## 2.4 Adding special context tokens"
]
},
+ {
+ "cell_type": "markdown",
+ "id": "863d6d15-a3e2-44e0-b384-bb37f17cf443",
+ "metadata": {},
+ "source": [
+ "- It's useful to add some \"special\" tokens for unknown words and to denote the end of a text"
+ ]
+ },
{
"cell_type": "markdown",
"id": "aa7fc96c-e1fd-44fb-b7f5-229d7c7922a4",
"metadata": {},
"source": [
- " "
+ "
"
+ " "
]
},
{
@@ -609,12 +675,20 @@
"\n"
]
},
+ {
+ "cell_type": "markdown",
+ "id": "a336b43b-7173-49e7-bd80-527ad4efb271",
+ "metadata": {},
+ "source": [
+ "- We use the `<|endoftext|>` tokens between two independent sources of text:"
+ ]
+ },
{
"cell_type": "markdown",
"id": "52442951-752c-4855-9752-b121a17fef55",
"metadata": {},
"source": [
- "
"
]
},
{
@@ -609,12 +675,20 @@
"\n"
]
},
+ {
+ "cell_type": "markdown",
+ "id": "a336b43b-7173-49e7-bd80-527ad4efb271",
+ "metadata": {},
+ "source": [
+ "- We use the `<|endoftext|>` tokens between two independent sources of text:"
+ ]
+ },
{
"cell_type": "markdown",
"id": "52442951-752c-4855-9752-b121a17fef55",
"metadata": {},
"source": [
- " "
+ "
"
+ " "
]
},
{
@@ -953,12 +1027,20 @@
"print(strings)"
]
},
+ {
+ "cell_type": "markdown",
+ "id": "e8c2e7b4-6a22-42aa-8e4d-901f06378d4a",
+ "metadata": {},
+ "source": [
+ "- BPE tokenizers break down unknown words into subwords and individual characters:"
+ ]
+ },
{
"cell_type": "markdown",
"id": "c082d41f-33d7-4827-97d8-993d5a84bb3c",
"metadata": {},
"source": [
- "
"
]
},
{
@@ -953,12 +1027,20 @@
"print(strings)"
]
},
+ {
+ "cell_type": "markdown",
+ "id": "e8c2e7b4-6a22-42aa-8e4d-901f06378d4a",
+ "metadata": {},
+ "source": [
+ "- BPE tokenizers break down unknown words into subwords and individual characters:"
+ ]
+ },
{
"cell_type": "markdown",
"id": "c082d41f-33d7-4827-97d8-993d5a84bb3c",
"metadata": {},
"source": [
- " "
+ "
"
+ " "
]
},
{
@@ -969,12 +1051,20 @@
"## 2.6 Data sampling with a sliding window"
]
},
+ {
+ "cell_type": "markdown",
+ "id": "509d9826-6384-462e-aa8a-a7c73cd6aad0",
+ "metadata": {},
+ "source": [
+ "- We train LLMs to generate one word at a time, so we want to prepare the training data accordingly where the next word in a sequence represents the target to predict:"
+ ]
+ },
{
"cell_type": "markdown",
"id": "39fb44f4-0c43-4a6a-9c2f-9cf31452354c",
"metadata": {},
"source": [
- "
"
]
},
{
@@ -969,12 +1051,20 @@
"## 2.6 Data sampling with a sliding window"
]
},
+ {
+ "cell_type": "markdown",
+ "id": "509d9826-6384-462e-aa8a-a7c73cd6aad0",
+ "metadata": {},
+ "source": [
+ "- We train LLMs to generate one word at a time, so we want to prepare the training data accordingly where the next word in a sequence represents the target to predict:"
+ ]
+ },
{
"cell_type": "markdown",
"id": "39fb44f4-0c43-4a6a-9c2f-9cf31452354c",
"metadata": {},
"source": [
- " "
+ "
"
+ " "
]
},
{
@@ -1101,14 +1191,6 @@
" print(tokenizer.decode(context), \"---->\", tokenizer.decode([desired]))"
]
},
- {
- "cell_type": "markdown",
- "id": "b59f90fe-fa73-4c2d-bd9b-ce7c2ce2ba00",
- "metadata": {},
- "source": [
- "
"
]
},
{
@@ -1101,14 +1191,6 @@
" print(tokenizer.decode(context), \"---->\", tokenizer.decode([desired]))"
]
},
- {
- "cell_type": "markdown",
- "id": "b59f90fe-fa73-4c2d-bd9b-ce7c2ce2ba00",
- "metadata": {},
- "source": [
- " "
- ]
- },
{
"cell_type": "markdown",
"id": "210d2dd9-fc20-4927-8d3d-1466cf41aae1",
@@ -1145,6 +1227,16 @@
"print(\"PyTorch version:\", torch.__version__)"
]
},
+ {
+ "cell_type": "markdown",
+ "id": "0c9a3d50-885b-49bc-b791-9f5cc8bc7b7c",
+ "metadata": {},
+ "source": [
+ "- We use a sliding window approach where we slide the window one word at a time (this is also known as `stride=1`):\n",
+ "\n",
+ "
"
- ]
- },
{
"cell_type": "markdown",
"id": "210d2dd9-fc20-4927-8d3d-1466cf41aae1",
@@ -1145,6 +1227,16 @@
"print(\"PyTorch version:\", torch.__version__)"
]
},
+ {
+ "cell_type": "markdown",
+ "id": "0c9a3d50-885b-49bc-b791-9f5cc8bc7b7c",
+ "metadata": {},
+ "source": [
+ "- We use a sliding window approach where we slide the window one word at a time (this is also known as `stride=1`):\n",
+ "\n",
+ " "
+ ]
+ },
{
"cell_type": "markdown",
"id": "92ac652d-7b38-4843-9fbd-494cdc8ec12c",
@@ -1268,12 +1360,20 @@
"print(second_batch)"
]
},
+ {
+ "cell_type": "markdown",
+ "id": "b006212f-de45-468d-bdee-5806216d1679",
+ "metadata": {},
+ "source": [
+ "- An example using stride equal to the context length (here: 4) as shown below:"
+ ]
+ },
{
"cell_type": "markdown",
"id": "9cb467e0-bdcd-4dda-b9b0-a738c5d33ac3",
"metadata": {},
"source": [
- "
"
+ ]
+ },
{
"cell_type": "markdown",
"id": "92ac652d-7b38-4843-9fbd-494cdc8ec12c",
@@ -1268,12 +1360,20 @@
"print(second_batch)"
]
},
+ {
+ "cell_type": "markdown",
+ "id": "b006212f-de45-468d-bdee-5806216d1679",
+ "metadata": {},
+ "source": [
+ "- An example using stride equal to the context length (here: 4) as shown below:"
+ ]
+ },
{
"cell_type": "markdown",
"id": "9cb467e0-bdcd-4dda-b9b0-a738c5d33ac3",
"metadata": {},
"source": [
- " "
+ "
"
+ " "
]
},
{
@@ -1349,7 +1449,7 @@
"id": "e85089aa-8671-4e5f-a2b3-ef252004ee4c",
"metadata": {},
"source": [
- "
"
]
},
{
@@ -1349,7 +1449,7 @@
"id": "e85089aa-8671-4e5f-a2b3-ef252004ee4c",
"metadata": {},
"source": [
- " "
+ "
"
+ " "
]
},
{
@@ -1489,12 +1589,30 @@
"print(embedding_layer(input_ids))"
]
},
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "be97ced4-bd13-42b7-866a-4d699a17e155",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "- An embedding layer is essentially a look-up operation:"
+ ]
+ },
{
"cell_type": "markdown",
"id": "f33c2741-bf1b-4c60-b7fd-61409d556646",
"metadata": {},
"source": [
- "
"
]
},
{
@@ -1489,12 +1589,30 @@
"print(embedding_layer(input_ids))"
]
},
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "be97ced4-bd13-42b7-866a-4d699a17e155",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "- An embedding layer is essentially a look-up operation:"
+ ]
+ },
{
"cell_type": "markdown",
"id": "f33c2741-bf1b-4c60-b7fd-61409d556646",
"metadata": {},
"source": [
- " "
+ "
"
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "08218d9f-aa1a-4afb-a105-72ff96a54e73",
+ "metadata": {},
+ "source": [
+ "- **You may be interested in the bonus content comparing embedding layers with regular linear layers: [../02_bonus_efficient-multihead-attention](../02_bonus_efficient-multihead-attention)**"
]
},
{
@@ -1505,12 +1623,28 @@
"## 2.8 Encoding word positions"
]
},
+ {
+ "cell_type": "markdown",
+ "id": "24940068-1099-4698-bdc0-e798515e2902",
+ "metadata": {},
+ "source": [
+ "- Embedding layer convert IDs into identical vector representations regardless of where they are located in the input sequence:"
+ ]
+ },
{
"cell_type": "markdown",
"id": "9e0b14a2-f3f3-490e-b513-f262dbcf94fa",
"metadata": {},
"source": [
- "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "08218d9f-aa1a-4afb-a105-72ff96a54e73",
+ "metadata": {},
+ "source": [
+ "- **You may be interested in the bonus content comparing embedding layers with regular linear layers: [../02_bonus_efficient-multihead-attention](../02_bonus_efficient-multihead-attention)**"
]
},
{
@@ -1505,12 +1623,28 @@
"## 2.8 Encoding word positions"
]
},
+ {
+ "cell_type": "markdown",
+ "id": "24940068-1099-4698-bdc0-e798515e2902",
+ "metadata": {},
+ "source": [
+ "- Embedding layer convert IDs into identical vector representations regardless of where they are located in the input sequence:"
+ ]
+ },
{
"cell_type": "markdown",
"id": "9e0b14a2-f3f3-490e-b513-f262dbcf94fa",
"metadata": {},
"source": [
- " "
+ "
"
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "92a7d7fe-38a5-46e6-8db6-b688887b0430",
+ "metadata": {},
+ "source": [
+ "- Positional embeddings are combined with the token embedding vector to form the input embeddings for a large language model:"
]
},
{
@@ -1518,7 +1652,7 @@
"id": "48de37db-d54d-45c4-ab3e-88c0783ad2e4",
"metadata": {},
"source": [
- "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "92a7d7fe-38a5-46e6-8db6-b688887b0430",
+ "metadata": {},
+ "source": [
+ "- Positional embeddings are combined with the token embedding vector to form the input embeddings for a large language model:"
]
},
{
@@ -1518,7 +1652,7 @@
"id": "48de37db-d54d-45c4-ab3e-88c0783ad2e4",
"metadata": {},
"source": [
- " "
+ "
"
+ " "
]
},
{
@@ -1679,12 +1813,21 @@
"print(input_embeddings.shape)"
]
},
+ {
+ "cell_type": "markdown",
+ "id": "1fbda581-6f9b-476f-8ea7-d244e6a4eaec",
+ "metadata": {},
+ "source": [
+ "- In the initial phase of the input processing workflow, the input text is segmented into separate tokens\n",
+ "- Following this segmentation, these tokens are transformed into token IDs based on a predefined vocabulary:"
+ ]
+ },
{
"cell_type": "markdown",
"id": "d1bb0f7e-460d-44db-b366-096adcd84fff",
"metadata": {},
"source": [
- "
"
]
},
{
@@ -1679,12 +1813,21 @@
"print(input_embeddings.shape)"
]
},
+ {
+ "cell_type": "markdown",
+ "id": "1fbda581-6f9b-476f-8ea7-d244e6a4eaec",
+ "metadata": {},
+ "source": [
+ "- In the initial phase of the input processing workflow, the input text is segmented into separate tokens\n",
+ "- Following this segmentation, these tokens are transformed into token IDs based on a predefined vocabulary:"
+ ]
+ },
{
"cell_type": "markdown",
"id": "d1bb0f7e-460d-44db-b366-096adcd84fff",
"metadata": {},
"source": [
- " "
+ "
"
+ " "
]
},
{
@@ -1722,7 +1865,7 @@
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
- "version": "3.12.2"
+ "version": "3.10.6"
}
},
"nbformat": 4,
diff --git a/ch02/01_main-chapter-code/figures/1.webp b/ch02/01_main-chapter-code/figures/1.webp
deleted file mode 100644
index 48a4df4..0000000
Binary files a/ch02/01_main-chapter-code/figures/1.webp and /dev/null differ
diff --git a/ch02/01_main-chapter-code/figures/10.webp b/ch02/01_main-chapter-code/figures/10.webp
deleted file mode 100644
index 35dd7d5..0000000
Binary files a/ch02/01_main-chapter-code/figures/10.webp and /dev/null differ
diff --git a/ch02/01_main-chapter-code/figures/11.webp b/ch02/01_main-chapter-code/figures/11.webp
deleted file mode 100644
index 444d265..0000000
Binary files a/ch02/01_main-chapter-code/figures/11.webp and /dev/null differ
diff --git a/ch02/01_main-chapter-code/figures/12.webp b/ch02/01_main-chapter-code/figures/12.webp
deleted file mode 100644
index 2da9d68..0000000
Binary files a/ch02/01_main-chapter-code/figures/12.webp and /dev/null differ
diff --git a/ch02/01_main-chapter-code/figures/13.webp b/ch02/01_main-chapter-code/figures/13.webp
deleted file mode 100644
index fe2e6f4..0000000
Binary files a/ch02/01_main-chapter-code/figures/13.webp and /dev/null differ
diff --git a/ch02/01_main-chapter-code/figures/14.webp b/ch02/01_main-chapter-code/figures/14.webp
deleted file mode 100644
index d8f48e4..0000000
Binary files a/ch02/01_main-chapter-code/figures/14.webp and /dev/null differ
diff --git a/ch02/01_main-chapter-code/figures/15.webp b/ch02/01_main-chapter-code/figures/15.webp
deleted file mode 100644
index 61a93ef..0000000
Binary files a/ch02/01_main-chapter-code/figures/15.webp and /dev/null differ
diff --git a/ch02/01_main-chapter-code/figures/16.webp b/ch02/01_main-chapter-code/figures/16.webp
deleted file mode 100644
index 29d1609..0000000
Binary files a/ch02/01_main-chapter-code/figures/16.webp and /dev/null differ
diff --git a/ch02/01_main-chapter-code/figures/17.webp b/ch02/01_main-chapter-code/figures/17.webp
deleted file mode 100644
index c88db28..0000000
Binary files a/ch02/01_main-chapter-code/figures/17.webp and /dev/null differ
diff --git a/ch02/01_main-chapter-code/figures/18.webp b/ch02/01_main-chapter-code/figures/18.webp
deleted file mode 100644
index a3ae32a..0000000
Binary files a/ch02/01_main-chapter-code/figures/18.webp and /dev/null differ
diff --git a/ch02/01_main-chapter-code/figures/19.webp b/ch02/01_main-chapter-code/figures/19.webp
deleted file mode 100644
index b725c2d..0000000
Binary files a/ch02/01_main-chapter-code/figures/19.webp and /dev/null differ
diff --git a/ch02/01_main-chapter-code/figures/2.webp b/ch02/01_main-chapter-code/figures/2.webp
deleted file mode 100644
index 8be4ae9..0000000
Binary files a/ch02/01_main-chapter-code/figures/2.webp and /dev/null differ
diff --git a/ch02/01_main-chapter-code/figures/3.webp b/ch02/01_main-chapter-code/figures/3.webp
deleted file mode 100644
index b3b26ff..0000000
Binary files a/ch02/01_main-chapter-code/figures/3.webp and /dev/null differ
diff --git a/ch02/01_main-chapter-code/figures/4.webp b/ch02/01_main-chapter-code/figures/4.webp
deleted file mode 100644
index 54f1a7f..0000000
Binary files a/ch02/01_main-chapter-code/figures/4.webp and /dev/null differ
diff --git a/ch02/01_main-chapter-code/figures/5.webp b/ch02/01_main-chapter-code/figures/5.webp
deleted file mode 100644
index 10965b0..0000000
Binary files a/ch02/01_main-chapter-code/figures/5.webp and /dev/null differ
diff --git a/ch02/01_main-chapter-code/figures/6.webp b/ch02/01_main-chapter-code/figures/6.webp
deleted file mode 100644
index d8f30f2..0000000
Binary files a/ch02/01_main-chapter-code/figures/6.webp and /dev/null differ
diff --git a/ch02/01_main-chapter-code/figures/7.webp b/ch02/01_main-chapter-code/figures/7.webp
deleted file mode 100644
index ed07e3c..0000000
Binary files a/ch02/01_main-chapter-code/figures/7.webp and /dev/null differ
diff --git a/ch02/01_main-chapter-code/figures/8.webp b/ch02/01_main-chapter-code/figures/8.webp
deleted file mode 100644
index 6cbed99..0000000
Binary files a/ch02/01_main-chapter-code/figures/8.webp and /dev/null differ
diff --git a/ch02/01_main-chapter-code/figures/9.webp b/ch02/01_main-chapter-code/figures/9.webp
deleted file mode 100644
index ac9d879..0000000
Binary files a/ch02/01_main-chapter-code/figures/9.webp and /dev/null differ
diff --git a/ch03/01_main-chapter-code/ch03.ipynb b/ch03/01_main-chapter-code/ch03.ipynb
index d332a25..1b5ba29 100644
--- a/ch03/01_main-chapter-code/ch03.ipynb
+++ b/ch03/01_main-chapter-code/ch03.ipynb
@@ -37,6 +37,22 @@
"print(\"torch version:\", version(\"torch\"))"
]
},
+ {
+ "cell_type": "markdown",
+ "id": "02a11208-d9d3-44b1-8e0d-0c8414110b93",
+ "metadata": {},
+ "source": [
+ "
"
]
},
{
@@ -1722,7 +1865,7 @@
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
- "version": "3.12.2"
+ "version": "3.10.6"
}
},
"nbformat": 4,
diff --git a/ch02/01_main-chapter-code/figures/1.webp b/ch02/01_main-chapter-code/figures/1.webp
deleted file mode 100644
index 48a4df4..0000000
Binary files a/ch02/01_main-chapter-code/figures/1.webp and /dev/null differ
diff --git a/ch02/01_main-chapter-code/figures/10.webp b/ch02/01_main-chapter-code/figures/10.webp
deleted file mode 100644
index 35dd7d5..0000000
Binary files a/ch02/01_main-chapter-code/figures/10.webp and /dev/null differ
diff --git a/ch02/01_main-chapter-code/figures/11.webp b/ch02/01_main-chapter-code/figures/11.webp
deleted file mode 100644
index 444d265..0000000
Binary files a/ch02/01_main-chapter-code/figures/11.webp and /dev/null differ
diff --git a/ch02/01_main-chapter-code/figures/12.webp b/ch02/01_main-chapter-code/figures/12.webp
deleted file mode 100644
index 2da9d68..0000000
Binary files a/ch02/01_main-chapter-code/figures/12.webp and /dev/null differ
diff --git a/ch02/01_main-chapter-code/figures/13.webp b/ch02/01_main-chapter-code/figures/13.webp
deleted file mode 100644
index fe2e6f4..0000000
Binary files a/ch02/01_main-chapter-code/figures/13.webp and /dev/null differ
diff --git a/ch02/01_main-chapter-code/figures/14.webp b/ch02/01_main-chapter-code/figures/14.webp
deleted file mode 100644
index d8f48e4..0000000
Binary files a/ch02/01_main-chapter-code/figures/14.webp and /dev/null differ
diff --git a/ch02/01_main-chapter-code/figures/15.webp b/ch02/01_main-chapter-code/figures/15.webp
deleted file mode 100644
index 61a93ef..0000000
Binary files a/ch02/01_main-chapter-code/figures/15.webp and /dev/null differ
diff --git a/ch02/01_main-chapter-code/figures/16.webp b/ch02/01_main-chapter-code/figures/16.webp
deleted file mode 100644
index 29d1609..0000000
Binary files a/ch02/01_main-chapter-code/figures/16.webp and /dev/null differ
diff --git a/ch02/01_main-chapter-code/figures/17.webp b/ch02/01_main-chapter-code/figures/17.webp
deleted file mode 100644
index c88db28..0000000
Binary files a/ch02/01_main-chapter-code/figures/17.webp and /dev/null differ
diff --git a/ch02/01_main-chapter-code/figures/18.webp b/ch02/01_main-chapter-code/figures/18.webp
deleted file mode 100644
index a3ae32a..0000000
Binary files a/ch02/01_main-chapter-code/figures/18.webp and /dev/null differ
diff --git a/ch02/01_main-chapter-code/figures/19.webp b/ch02/01_main-chapter-code/figures/19.webp
deleted file mode 100644
index b725c2d..0000000
Binary files a/ch02/01_main-chapter-code/figures/19.webp and /dev/null differ
diff --git a/ch02/01_main-chapter-code/figures/2.webp b/ch02/01_main-chapter-code/figures/2.webp
deleted file mode 100644
index 8be4ae9..0000000
Binary files a/ch02/01_main-chapter-code/figures/2.webp and /dev/null differ
diff --git a/ch02/01_main-chapter-code/figures/3.webp b/ch02/01_main-chapter-code/figures/3.webp
deleted file mode 100644
index b3b26ff..0000000
Binary files a/ch02/01_main-chapter-code/figures/3.webp and /dev/null differ
diff --git a/ch02/01_main-chapter-code/figures/4.webp b/ch02/01_main-chapter-code/figures/4.webp
deleted file mode 100644
index 54f1a7f..0000000
Binary files a/ch02/01_main-chapter-code/figures/4.webp and /dev/null differ
diff --git a/ch02/01_main-chapter-code/figures/5.webp b/ch02/01_main-chapter-code/figures/5.webp
deleted file mode 100644
index 10965b0..0000000
Binary files a/ch02/01_main-chapter-code/figures/5.webp and /dev/null differ
diff --git a/ch02/01_main-chapter-code/figures/6.webp b/ch02/01_main-chapter-code/figures/6.webp
deleted file mode 100644
index d8f30f2..0000000
Binary files a/ch02/01_main-chapter-code/figures/6.webp and /dev/null differ
diff --git a/ch02/01_main-chapter-code/figures/7.webp b/ch02/01_main-chapter-code/figures/7.webp
deleted file mode 100644
index ed07e3c..0000000
Binary files a/ch02/01_main-chapter-code/figures/7.webp and /dev/null differ
diff --git a/ch02/01_main-chapter-code/figures/8.webp b/ch02/01_main-chapter-code/figures/8.webp
deleted file mode 100644
index 6cbed99..0000000
Binary files a/ch02/01_main-chapter-code/figures/8.webp and /dev/null differ
diff --git a/ch02/01_main-chapter-code/figures/9.webp b/ch02/01_main-chapter-code/figures/9.webp
deleted file mode 100644
index ac9d879..0000000
Binary files a/ch02/01_main-chapter-code/figures/9.webp and /dev/null differ
diff --git a/ch03/01_main-chapter-code/ch03.ipynb b/ch03/01_main-chapter-code/ch03.ipynb
index d332a25..1b5ba29 100644
--- a/ch03/01_main-chapter-code/ch03.ipynb
+++ b/ch03/01_main-chapter-code/ch03.ipynb
@@ -37,6 +37,22 @@
"print(\"torch version:\", version(\"torch\"))"
]
},
+ {
+ "cell_type": "markdown",
+ "id": "02a11208-d9d3-44b1-8e0d-0c8414110b93",
+ "metadata": {},
+ "source": [
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "50e020fd-9690-4343-80df-da96678bef5e",
+ "metadata": {},
+ "source": [
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "50e020fd-9690-4343-80df-da96678bef5e",
+ "metadata": {},
+ "source": [
+ " "
+ ]
+ },
{
"cell_type": "markdown",
"id": "ecc4dcee-34ea-4c05-9085-2f8887f70363",
@@ -53,6 +69,22 @@
"- No code in this section"
]
},
+ {
+ "cell_type": "markdown",
+ "id": "55c0c433-aa4b-491e-848a-54905ebb05ad",
+ "metadata": {},
+ "source": [
+ "
"
+ ]
+ },
{
"cell_type": "markdown",
"id": "ecc4dcee-34ea-4c05-9085-2f8887f70363",
@@ -53,6 +69,22 @@
"- No code in this section"
]
},
+ {
+ "cell_type": "markdown",
+ "id": "55c0c433-aa4b-491e-848a-54905ebb05ad",
+ "metadata": {},
+ "source": [
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "03d8df2c-c1c2-4df0-9977-ade9713088b2",
+ "metadata": {},
+ "source": [
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "03d8df2c-c1c2-4df0-9977-ade9713088b2",
+ "metadata": {},
+ "source": [
+ " "
+ ]
+ },
{
"cell_type": "markdown",
"id": "3602c585-b87a-41c7-a324-c5e8298849df",
@@ -69,6 +101,22 @@
"- No code in this section"
]
},
+ {
+ "cell_type": "markdown",
+ "id": "bc4f6293-8ab5-4aeb-a04c-50ee158485b1",
+ "metadata": {},
+ "source": [
+ "
"
+ ]
+ },
{
"cell_type": "markdown",
"id": "3602c585-b87a-41c7-a324-c5e8298849df",
@@ -69,6 +101,22 @@
"- No code in this section"
]
},
+ {
+ "cell_type": "markdown",
+ "id": "bc4f6293-8ab5-4aeb-a04c-50ee158485b1",
+ "metadata": {},
+ "source": [
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "6565dc9f-b1be-4c78-b503-42ccc743296c",
+ "metadata": {},
+ "source": [
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "6565dc9f-b1be-4c78-b503-42ccc743296c",
+ "metadata": {},
+ "source": [
+ " "
+ ]
+ },
{
"cell_type": "markdown",
"id": "5efe05ff-b441-408e-8d66-cde4eb3397e3",
@@ -103,6 +151,14 @@
" - In short, think of $z^{(2)}$ as a modified version of $x^{(2)}$ that also incorporates information about all other input elements that are relevant to a given task at hand."
]
},
+ {
+ "cell_type": "markdown",
+ "id": "fcc7c7a2-b6ab-478f-ae37-faa8eaa8049a",
+ "metadata": {},
+ "source": [
+ "
"
+ ]
+ },
{
"cell_type": "markdown",
"id": "5efe05ff-b441-408e-8d66-cde4eb3397e3",
@@ -103,6 +151,14 @@
" - In short, think of $z^{(2)}$ as a modified version of $x^{(2)}$ that also incorporates information about all other input elements that are relevant to a given task at hand."
]
},
+ {
+ "cell_type": "markdown",
+ "id": "fcc7c7a2-b6ab-478f-ae37-faa8eaa8049a",
+ "metadata": {},
+ "source": [
+ " "
+ ]
+ },
{
"cell_type": "markdown",
"id": "ff856c58-8382-44c7-827f-798040e6e697",
@@ -141,14 +197,6 @@
" - The subscript \"21\" in $\\omega_{21}$ means that input sequence element 2 was used as a query against input sequence element 1."
]
},
- {
- "cell_type": "markdown",
- "id": "2e29440f-9b77-4966-83aa-d1ff2e653b00",
- "metadata": {},
- "source": [
- "
"
+ ]
+ },
{
"cell_type": "markdown",
"id": "ff856c58-8382-44c7-827f-798040e6e697",
@@ -141,14 +197,6 @@
" - The subscript \"21\" in $\\omega_{21}$ means that input sequence element 2 was used as a query against input sequence element 1."
]
},
- {
- "cell_type": "markdown",
- "id": "2e29440f-9b77-4966-83aa-d1ff2e653b00",
- "metadata": {},
- "source": [
- " "
- ]
- },
{
"cell_type": "markdown",
"id": "35e55f7a-f2d0-4f24-858b-228e4fe88fb3",
@@ -176,6 +224,14 @@
")"
]
},
+ {
+ "cell_type": "markdown",
+ "id": "5cb3453a-58fa-42c4-b225-86850bc856f8",
+ "metadata": {},
+ "source": [
+ "
"
- ]
- },
{
"cell_type": "markdown",
"id": "35e55f7a-f2d0-4f24-858b-228e4fe88fb3",
@@ -176,6 +224,14 @@
")"
]
},
+ {
+ "cell_type": "markdown",
+ "id": "5cb3453a-58fa-42c4-b225-86850bc856f8",
+ "metadata": {},
+ "source": [
+ " "
+ ]
+ },
{
"cell_type": "markdown",
"id": "77be52fb-82fd-4886-a4c8-f24a9c87af22",
@@ -242,6 +298,14 @@
"print(torch.dot(inputs[0], query))"
]
},
+ {
+ "cell_type": "markdown",
+ "id": "dfd965d6-980c-476a-93d8-9efe603b1b3b",
+ "metadata": {},
+ "source": [
+ "
"
+ ]
+ },
{
"cell_type": "markdown",
"id": "77be52fb-82fd-4886-a4c8-f24a9c87af22",
@@ -242,6 +298,14 @@
"print(torch.dot(inputs[0], query))"
]
},
+ {
+ "cell_type": "markdown",
+ "id": "dfd965d6-980c-476a-93d8-9efe603b1b3b",
+ "metadata": {},
+ "source": [
+ " "
+ ]
+ },
{
"cell_type": "markdown",
"id": "7d444d76-e19e-4e9a-a268-f315d966609b",
@@ -346,6 +410,14 @@
"- **Step 3**: compute the context vector $z^{(2)}$ by multiplying the embedded input tokens, $x^{(i)}$ with the attention weights and sum the resulting vectors:"
]
},
+ {
+ "cell_type": "markdown",
+ "id": "f1c9f5ac-8d3d-4847-94e3-fd783b7d4d3d",
+ "metadata": {},
+ "source": [
+ "
"
+ ]
+ },
{
"cell_type": "markdown",
"id": "7d444d76-e19e-4e9a-a268-f315d966609b",
@@ -346,6 +410,14 @@
"- **Step 3**: compute the context vector $z^{(2)}$ by multiplying the embedded input tokens, $x^{(i)}$ with the attention weights and sum the resulting vectors:"
]
},
+ {
+ "cell_type": "markdown",
+ "id": "f1c9f5ac-8d3d-4847-94e3-fd783b7d4d3d",
+ "metadata": {},
+ "source": [
+ " "
+ ]
+ },
{
"cell_type": "code",
"execution_count": 8,
@@ -394,7 +466,15 @@
"id": "11c0fb55-394f-42f4-ba07-d01ae5c98ab4",
"metadata": {},
"source": [
- "
"
+ ]
+ },
{
"cell_type": "code",
"execution_count": 8,
@@ -394,7 +466,15 @@
"id": "11c0fb55-394f-42f4-ba07-d01ae5c98ab4",
"metadata": {},
"source": [
- " "
+ "
"
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "d9bffe4b-56fe-4c37-9762-24bd924b7d3c",
+ "metadata": {},
+ "source": [
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "d9bffe4b-56fe-4c37-9762-24bd924b7d3c",
+ "metadata": {},
+ "source": [
+ " "
]
},
{
@@ -594,6 +674,14 @@
"## 3.4 Implementing self-attention with trainable weights"
]
},
+ {
+ "cell_type": "markdown",
+ "id": "ac9492ba-6f66-4f65-bd1d-87cf16d59928",
+ "metadata": {},
+ "source": [
+ "
"
]
},
{
@@ -594,6 +674,14 @@
"## 3.4 Implementing self-attention with trainable weights"
]
},
+ {
+ "cell_type": "markdown",
+ "id": "ac9492ba-6f66-4f65-bd1d-87cf16d59928",
+ "metadata": {},
+ "source": [
+ " "
+ ]
+ },
{
"cell_type": "markdown",
"id": "2b90a77e-d746-4704-9354-1ddad86e6298",
@@ -617,6 +705,14 @@
" - These trainable weight matrices are crucial so that the model (specifically, the attention module inside the model) can learn to produce \"good\" context vectors."
]
},
+ {
+ "cell_type": "markdown",
+ "id": "59db4093-93e8-4bee-be8f-c8fac8a08cdd",
+ "metadata": {},
+ "source": [
+ "
"
+ ]
+ },
{
"cell_type": "markdown",
"id": "2b90a77e-d746-4704-9354-1ddad86e6298",
@@ -617,6 +705,14 @@
" - These trainable weight matrices are crucial so that the model (specifically, the attention module inside the model) can learn to produce \"good\" context vectors."
]
},
+ {
+ "cell_type": "markdown",
+ "id": "59db4093-93e8-4bee-be8f-c8fac8a08cdd",
+ "metadata": {},
+ "source": [
+ " "
+ ]
+ },
{
"cell_type": "markdown",
"id": "4d996671-87aa-45c9-b2e0-07a7bcc9060a",
@@ -630,14 +726,6 @@
" - Value vector: $v^{(i)} = W_v \\,x^{(i)}$\n"
]
},
- {
- "cell_type": "markdown",
- "id": "d3b29bc6-4bde-4924-9aff-0af1421803f5",
- "metadata": {},
- "source": [
- "
"
+ ]
+ },
{
"cell_type": "markdown",
"id": "4d996671-87aa-45c9-b2e0-07a7bcc9060a",
@@ -630,14 +726,6 @@
" - Value vector: $v^{(i)} = W_v \\,x^{(i)}$\n"
]
},
- {
- "cell_type": "markdown",
- "id": "d3b29bc6-4bde-4924-9aff-0af1421803f5",
- "metadata": {},
- "source": [
- " "
- ]
- },
{
"cell_type": "markdown",
"id": "9f334313-5fd0-477b-8728-04080a427049",
@@ -755,7 +843,7 @@
"id": "8ed0a2b7-5c50-4ede-90cf-7ad74412b3aa",
"metadata": {},
"source": [
- "
"
- ]
- },
{
"cell_type": "markdown",
"id": "9f334313-5fd0-477b-8728-04080a427049",
@@ -755,7 +843,7 @@
"id": "8ed0a2b7-5c50-4ede-90cf-7ad74412b3aa",
"metadata": {},
"source": [
- " "
+ "
"
+ " "
]
},
{
@@ -810,7 +898,7 @@
"id": "8622cf39-155f-4eb5-a0c0-82a03ce9b999",
"metadata": {},
"source": [
- "
"
]
},
{
@@ -810,7 +898,7 @@
"id": "8622cf39-155f-4eb5-a0c0-82a03ce9b999",
"metadata": {},
"source": [
- " "
+ "
"
+ " "
]
},
{
@@ -847,7 +935,7 @@
"id": "b8f61a28-b103-434a-aee1-ae7cbd821126",
"metadata": {},
"source": [
- "
"
]
},
{
@@ -847,7 +935,7 @@
"id": "b8f61a28-b103-434a-aee1-ae7cbd821126",
"metadata": {},
"source": [
- " "
+ "
"
+ " "
]
},
{
@@ -940,6 +1028,14 @@
"print(sa_v1(inputs))"
]
},
+ {
+ "cell_type": "markdown",
+ "id": "7ee1a024-84a5-425a-9567-54ab4e4ed445",
+ "metadata": {},
+ "source": [
+ "
"
]
},
{
@@ -940,6 +1028,14 @@
"print(sa_v1(inputs))"
]
},
+ {
+ "cell_type": "markdown",
+ "id": "7ee1a024-84a5-425a-9567-54ab4e4ed445",
+ "metadata": {},
+ "source": [
+ " "
+ ]
+ },
{
"cell_type": "markdown",
"id": "048e0c16-d911-4ec8-b0bc-45ceec75c081",
@@ -1010,6 +1106,14 @@
"## 3.5 Hiding future words with causal attention"
]
},
+ {
+ "cell_type": "markdown",
+ "id": "71e91bb5-5aae-4f05-8a95-973b3f988a35",
+ "metadata": {},
+ "source": [
+ "
"
+ ]
+ },
{
"cell_type": "markdown",
"id": "048e0c16-d911-4ec8-b0bc-45ceec75c081",
@@ -1010,6 +1106,14 @@
"## 3.5 Hiding future words with causal attention"
]
},
+ {
+ "cell_type": "markdown",
+ "id": "71e91bb5-5aae-4f05-8a95-973b3f988a35",
+ "metadata": {},
+ "source": [
+ " "
+ ]
+ },
{
"cell_type": "markdown",
"id": "82f405de-cd86-4e72-8f3c-9ea0354946ba",
@@ -1031,10 +1135,10 @@
},
{
"cell_type": "markdown",
- "id": "71e91bb5-5aae-4f05-8a95-973b3f988a35",
+ "id": "57f99af3-32bc-48f5-8eb4-63504670ca0a",
"metadata": {},
"source": [
- "
"
+ ]
+ },
{
"cell_type": "markdown",
"id": "82f405de-cd86-4e72-8f3c-9ea0354946ba",
@@ -1031,10 +1135,10 @@
},
{
"cell_type": "markdown",
- "id": "71e91bb5-5aae-4f05-8a95-973b3f988a35",
+ "id": "57f99af3-32bc-48f5-8eb4-63504670ca0a",
"metadata": {},
"source": [
- " "
+ "
"
+ " "
]
},
{
@@ -1193,6 +1297,14 @@
"- So, instead of zeroing out attention weights above the diagonal and renormalizing the results, we can mask the unnormalized attention scores above the diagonal with negative infinity before they enter the softmax function:"
]
},
+ {
+ "cell_type": "markdown",
+ "id": "eb682900-8df2-4767-946c-a82bee260188",
+ "metadata": {},
+ "source": [
+ "
"
]
},
{
@@ -1193,6 +1297,14 @@
"- So, instead of zeroing out attention weights above the diagonal and renormalizing the results, we can mask the unnormalized attention scores above the diagonal with negative infinity before they enter the softmax function:"
]
},
+ {
+ "cell_type": "markdown",
+ "id": "eb682900-8df2-4767-946c-a82bee260188",
+ "metadata": {},
+ "source": [
+ " "
+ ]
+ },
{
"cell_type": "code",
"execution_count": 29,
@@ -1279,7 +1391,7 @@
"id": "ee799cf6-6175-45f2-827e-c174afedb722",
"metadata": {},
"source": [
- "
"
+ ]
+ },
{
"cell_type": "code",
"execution_count": 29,
@@ -1279,7 +1391,7 @@
"id": "ee799cf6-6175-45f2-827e-c174afedb722",
"metadata": {},
"source": [
- " "
+ ""
]
},
{
@@ -1460,6 +1572,14 @@
"- Note that dropout is only applied during training, not during inference."
]
},
+ {
+ "cell_type": "markdown",
+ "id": "a554cf47-558c-4f45-84cd-bf9b839a8d50",
+ "metadata": {},
+ "source": [
+ "
"
+ ""
]
},
{
@@ -1460,6 +1572,14 @@
"- Note that dropout is only applied during training, not during inference."
]
},
+ {
+ "cell_type": "markdown",
+ "id": "a554cf47-558c-4f45-84cd-bf9b839a8d50",
+ "metadata": {},
+ "source": [
+ " "
+ ]
+ },
{
"cell_type": "markdown",
"id": "c8bef90f-cfd4-4289-b0e8-6a00dc9be44c",
@@ -1485,11 +1605,11 @@
"\n",
"- This is also called single-head attention:\n",
"\n",
- "
"
+ ]
+ },
{
"cell_type": "markdown",
"id": "c8bef90f-cfd4-4289-b0e8-6a00dc9be44c",
@@ -1485,11 +1605,11 @@
"\n",
"- This is also called single-head attention:\n",
"\n",
- " \n",
+ "
\n",
+ " \n",
"\n",
"- We simply stack multiple single-head attention modules to obtain a multi-head attention module:\n",
"\n",
- "
\n",
"\n",
"- We simply stack multiple single-head attention modules to obtain a multi-head attention module:\n",
"\n",
- " \n",
+ "
\n",
+ " \n",
"\n",
"- The main idea behind multi-head attention is to run the attention mechanism multiple times (in parallel) with different, learned linear projections. This allows the model to jointly attend to information from different representation subspaces at different positions."
]
@@ -1678,6 +1798,14 @@
"- Note that in addition, we added a linear projection layer (`self.out_proj `) to the `MultiHeadAttention` class above. This is simply a linear transformation that doesn't change the dimensions. It's a standard convention to use such a projection layer in LLM implementation, but it's not strictly necessary (recent research has shown that it can be removed without affecting the modeling performance; see the further reading section at the end of this chapter)\n"
]
},
+ {
+ "cell_type": "markdown",
+ "id": "dbe5d396-c990-45dc-9908-2c621461f851",
+ "metadata": {},
+ "source": [
+ "
\n",
"\n",
"- The main idea behind multi-head attention is to run the attention mechanism multiple times (in parallel) with different, learned linear projections. This allows the model to jointly attend to information from different representation subspaces at different positions."
]
@@ -1678,6 +1798,14 @@
"- Note that in addition, we added a linear projection layer (`self.out_proj `) to the `MultiHeadAttention` class above. This is simply a linear transformation that doesn't change the dimensions. It's a standard convention to use such a projection layer in LLM implementation, but it's not strictly necessary (recent research has shown that it can be removed without affecting the modeling performance; see the further reading section at the end of this chapter)\n"
]
},
+ {
+ "cell_type": "markdown",
+ "id": "dbe5d396-c990-45dc-9908-2c621461f851",
+ "metadata": {},
+ "source": [
+ " "
+ ]
+ },
{
"cell_type": "markdown",
"id": "8b0ed78c-e8ac-4f8f-a479-a98242ae8f65",
@@ -1802,7 +1930,7 @@
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
- "version": "3.10.12"
+ "version": "3.10.6"
}
},
"nbformat": 4,
diff --git a/ch03/01_main-chapter-code/figures/attention-matrix.png b/ch03/01_main-chapter-code/figures/attention-matrix.png
deleted file mode 100644
index cfda9f6..0000000
Binary files a/ch03/01_main-chapter-code/figures/attention-matrix.png and /dev/null differ
diff --git a/ch03/01_main-chapter-code/figures/attention.png b/ch03/01_main-chapter-code/figures/attention.png
deleted file mode 100644
index 73edf26..0000000
Binary files a/ch03/01_main-chapter-code/figures/attention.png and /dev/null differ
diff --git a/ch03/01_main-chapter-code/figures/dot-product.png b/ch03/01_main-chapter-code/figures/dot-product.png
deleted file mode 100644
index b7f88e2..0000000
Binary files a/ch03/01_main-chapter-code/figures/dot-product.png and /dev/null differ
diff --git a/ch03/01_main-chapter-code/figures/dropout.png b/ch03/01_main-chapter-code/figures/dropout.png
deleted file mode 100644
index d139372..0000000
Binary files a/ch03/01_main-chapter-code/figures/dropout.png and /dev/null differ
diff --git a/ch03/01_main-chapter-code/figures/masked.png b/ch03/01_main-chapter-code/figures/masked.png
deleted file mode 100644
index 6b5d7ea..0000000
Binary files a/ch03/01_main-chapter-code/figures/masked.png and /dev/null differ
diff --git a/ch03/01_main-chapter-code/figures/multi-head.png b/ch03/01_main-chapter-code/figures/multi-head.png
deleted file mode 100644
index 53fe6c5..0000000
Binary files a/ch03/01_main-chapter-code/figures/multi-head.png and /dev/null differ
diff --git a/ch03/01_main-chapter-code/figures/single-head.png b/ch03/01_main-chapter-code/figures/single-head.png
deleted file mode 100644
index 8bb3367..0000000
Binary files a/ch03/01_main-chapter-code/figures/single-head.png and /dev/null differ
diff --git a/ch03/01_main-chapter-code/figures/weight-selfattn-1.png b/ch03/01_main-chapter-code/figures/weight-selfattn-1.png
deleted file mode 100644
index 54190e7..0000000
Binary files a/ch03/01_main-chapter-code/figures/weight-selfattn-1.png and /dev/null differ
diff --git a/ch03/01_main-chapter-code/figures/weight-selfattn-2.png b/ch03/01_main-chapter-code/figures/weight-selfattn-2.png
deleted file mode 100644
index e4db5bd..0000000
Binary files a/ch03/01_main-chapter-code/figures/weight-selfattn-2.png and /dev/null differ
diff --git a/ch03/01_main-chapter-code/figures/weight-selfattn-3.png b/ch03/01_main-chapter-code/figures/weight-selfattn-3.png
deleted file mode 100644
index 7f68655..0000000
Binary files a/ch03/01_main-chapter-code/figures/weight-selfattn-3.png and /dev/null differ
diff --git a/ch03/01_main-chapter-code/figures/weight-selfattn-4.png b/ch03/01_main-chapter-code/figures/weight-selfattn-4.png
deleted file mode 100644
index 40d538d..0000000
Binary files a/ch03/01_main-chapter-code/figures/weight-selfattn-4.png and /dev/null differ
diff --git a/ch04/01_main-chapter-code/ch04.ipynb b/ch04/01_main-chapter-code/ch04.ipynb
index ef4a388..4304e38 100644
--- a/ch04/01_main-chapter-code/ch04.ipynb
+++ b/ch04/01_main-chapter-code/ch04.ipynb
@@ -49,7 +49,7 @@
"id": "7d4f11e0-4434-4979-9dee-e1207df0eb01",
"metadata": {},
"source": [
- "
"
+ ]
+ },
{
"cell_type": "markdown",
"id": "8b0ed78c-e8ac-4f8f-a479-a98242ae8f65",
@@ -1802,7 +1930,7 @@
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
- "version": "3.10.12"
+ "version": "3.10.6"
}
},
"nbformat": 4,
diff --git a/ch03/01_main-chapter-code/figures/attention-matrix.png b/ch03/01_main-chapter-code/figures/attention-matrix.png
deleted file mode 100644
index cfda9f6..0000000
Binary files a/ch03/01_main-chapter-code/figures/attention-matrix.png and /dev/null differ
diff --git a/ch03/01_main-chapter-code/figures/attention.png b/ch03/01_main-chapter-code/figures/attention.png
deleted file mode 100644
index 73edf26..0000000
Binary files a/ch03/01_main-chapter-code/figures/attention.png and /dev/null differ
diff --git a/ch03/01_main-chapter-code/figures/dot-product.png b/ch03/01_main-chapter-code/figures/dot-product.png
deleted file mode 100644
index b7f88e2..0000000
Binary files a/ch03/01_main-chapter-code/figures/dot-product.png and /dev/null differ
diff --git a/ch03/01_main-chapter-code/figures/dropout.png b/ch03/01_main-chapter-code/figures/dropout.png
deleted file mode 100644
index d139372..0000000
Binary files a/ch03/01_main-chapter-code/figures/dropout.png and /dev/null differ
diff --git a/ch03/01_main-chapter-code/figures/masked.png b/ch03/01_main-chapter-code/figures/masked.png
deleted file mode 100644
index 6b5d7ea..0000000
Binary files a/ch03/01_main-chapter-code/figures/masked.png and /dev/null differ
diff --git a/ch03/01_main-chapter-code/figures/multi-head.png b/ch03/01_main-chapter-code/figures/multi-head.png
deleted file mode 100644
index 53fe6c5..0000000
Binary files a/ch03/01_main-chapter-code/figures/multi-head.png and /dev/null differ
diff --git a/ch03/01_main-chapter-code/figures/single-head.png b/ch03/01_main-chapter-code/figures/single-head.png
deleted file mode 100644
index 8bb3367..0000000
Binary files a/ch03/01_main-chapter-code/figures/single-head.png and /dev/null differ
diff --git a/ch03/01_main-chapter-code/figures/weight-selfattn-1.png b/ch03/01_main-chapter-code/figures/weight-selfattn-1.png
deleted file mode 100644
index 54190e7..0000000
Binary files a/ch03/01_main-chapter-code/figures/weight-selfattn-1.png and /dev/null differ
diff --git a/ch03/01_main-chapter-code/figures/weight-selfattn-2.png b/ch03/01_main-chapter-code/figures/weight-selfattn-2.png
deleted file mode 100644
index e4db5bd..0000000
Binary files a/ch03/01_main-chapter-code/figures/weight-selfattn-2.png and /dev/null differ
diff --git a/ch03/01_main-chapter-code/figures/weight-selfattn-3.png b/ch03/01_main-chapter-code/figures/weight-selfattn-3.png
deleted file mode 100644
index 7f68655..0000000
Binary files a/ch03/01_main-chapter-code/figures/weight-selfattn-3.png and /dev/null differ
diff --git a/ch03/01_main-chapter-code/figures/weight-selfattn-4.png b/ch03/01_main-chapter-code/figures/weight-selfattn-4.png
deleted file mode 100644
index 40d538d..0000000
Binary files a/ch03/01_main-chapter-code/figures/weight-selfattn-4.png and /dev/null differ
diff --git a/ch04/01_main-chapter-code/ch04.ipynb b/ch04/01_main-chapter-code/ch04.ipynb
index ef4a388..4304e38 100644
--- a/ch04/01_main-chapter-code/ch04.ipynb
+++ b/ch04/01_main-chapter-code/ch04.ipynb
@@ -49,7 +49,7 @@
"id": "7d4f11e0-4434-4979-9dee-e1207df0eb01",
"metadata": {},
"source": [
- " "
+ "
"
+ " "
]
},
{
@@ -76,7 +76,7 @@
"id": "5c5213e9-bd1c-437e-aee8-f5e8fb717251",
"metadata": {},
"source": [
- "
"
]
},
{
@@ -76,7 +76,7 @@
"id": "5c5213e9-bd1c-437e-aee8-f5e8fb717251",
"metadata": {},
"source": [
- " "
+ "
"
+ " "
]
},
{
@@ -136,7 +136,7 @@
"id": "4adce779-857b-4418-9501-12a7f3818d88",
"metadata": {},
"source": [
- "
"
]
},
{
@@ -136,7 +136,7 @@
"id": "4adce779-857b-4418-9501-12a7f3818d88",
"metadata": {},
"source": [
- " "
+ "
"
+ " "
]
},
{
@@ -204,7 +204,7 @@
"id": "9665e8ab-20ca-4100-b9b9-50d9bdee33be",
"metadata": {},
"source": [
- "
"
]
},
{
@@ -204,7 +204,7 @@
"id": "9665e8ab-20ca-4100-b9b9-50d9bdee33be",
"metadata": {},
"source": [
- " "
+ "
"
+ " "
]
},
{
@@ -294,7 +294,7 @@
"id": "314ac47a-69cc-4597-beeb-65bed3b5910f",
"metadata": {},
"source": [
- "
"
]
},
{
@@ -294,7 +294,7 @@
"id": "314ac47a-69cc-4597-beeb-65bed3b5910f",
"metadata": {},
"source": [
- " "
+ "
"
+ " "
]
},
{
@@ -380,7 +380,7 @@
"id": "570db83a-205c-4f6f-b219-1f6195dde1a7",
"metadata": {},
"source": [
- "
"
]
},
{
@@ -380,7 +380,7 @@
"id": "570db83a-205c-4f6f-b219-1f6195dde1a7",
"metadata": {},
"source": [
- " "
+ "
"
+ " "
]
},
{
@@ -551,7 +551,7 @@
"id": "e136cfc4-7c89-492e-b120-758c272bca8c",
"metadata": {},
"source": [
- "
"
]
},
{
@@ -551,7 +551,7 @@
"id": "e136cfc4-7c89-492e-b120-758c272bca8c",
"metadata": {},
"source": [
- " "
+ "
"
+ " "
]
},
{
@@ -696,7 +696,7 @@
"id": "fdcaacfa-3cfc-4c9e-b668-b71a2753145a",
"metadata": {},
"source": [
- "
"
]
},
{
@@ -696,7 +696,7 @@
"id": "fdcaacfa-3cfc-4c9e-b668-b71a2753145a",
"metadata": {},
"source": [
- " "
+ "
"
+ " "
]
},
{
@@ -727,7 +727,15 @@
"id": "8f8756c5-6b04-443b-93d0-e555a316c377",
"metadata": {},
"source": [
- "
"
]
},
{
@@ -727,7 +727,15 @@
"id": "8f8756c5-6b04-443b-93d0-e555a316c377",
"metadata": {},
"source": [
- " "
+ "
"
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "e5da2a50-04f4-4388-af23-ad32e405a972",
+ "metadata": {},
+ "source": [
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "e5da2a50-04f4-4388-af23-ad32e405a972",
+ "metadata": {},
+ "source": [
+ " "
]
},
{
@@ -749,7 +757,7 @@
"- This is achieved by adding the output of one layer to the output of a later layer, usually skipping one or more layers in between\n",
"- Let's illustrate this idea with a small example network:\n",
"\n",
- "
"
]
},
{
@@ -749,7 +757,7 @@
"- This is achieved by adding the output of one layer to the output of a later layer, usually skipping one or more layers in between\n",
"- Let's illustrate this idea with a small example network:\n",
"\n",
- " "
+ "
"
+ " "
]
},
{
@@ -957,7 +965,7 @@
"id": "36b64d16-94a6-4d13-8c85-9494c50478a9",
"metadata": {},
"source": [
- "
"
]
},
{
@@ -957,7 +965,7 @@
"id": "36b64d16-94a6-4d13-8c85-9494c50478a9",
"metadata": {},
"source": [
- " "
+ "
"
+ " "
]
},
{
@@ -1000,7 +1008,7 @@
"id": "91f502e4-f3e4-40cb-8268-179eec002394",
"metadata": {},
"source": [
- "
"
]
},
{
@@ -1000,7 +1008,7 @@
"id": "91f502e4-f3e4-40cb-8268-179eec002394",
"metadata": {},
"source": [
- " "
+ "
"
+ " "
]
},
{
@@ -1025,7 +1033,7 @@
"id": "9b7b362d-f8c5-48d2-8ebd-722480ac5073",
"metadata": {},
"source": [
- "
"
]
},
{
@@ -1025,7 +1033,7 @@
"id": "9b7b362d-f8c5-48d2-8ebd-722480ac5073",
"metadata": {},
"source": [
- " "
+ "
"
+ " "
]
},
{
@@ -1288,7 +1296,7 @@
"id": "caade12a-fe97-480f-939c-87d24044edff",
"metadata": {},
"source": [
- "
"
]
},
{
@@ -1288,7 +1296,7 @@
"id": "caade12a-fe97-480f-939c-87d24044edff",
"metadata": {},
"source": [
- " "
+ "
"
+ " "
]
},
{
@@ -1307,7 +1315,7 @@
"id": "7ee0f32c-c18c-445e-b294-a879de2aa187",
"metadata": {},
"source": [
- "
"
]
},
{
@@ -1307,7 +1315,7 @@
"id": "7ee0f32c-c18c-445e-b294-a879de2aa187",
"metadata": {},
"source": [
- " "
+ "
"
+ " "
]
},
{
@@ -1353,7 +1361,7 @@
"source": [
"- The `generate_text_simple` above implements an iterative process, where it creates one token at a time\n",
"\n",
- "
"
]
},
{
@@ -1353,7 +1361,7 @@
"source": [
"- The `generate_text_simple` above implements an iterative process, where it creates one token at a time\n",
"\n",
- " "
+ "
"
+ " "
]
},
{
@@ -1506,7 +1514,7 @@
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
- "version": "3.11.4"
+ "version": "3.10.6"
}
},
"nbformat": 4,
diff --git a/ch04/01_main-chapter-code/figures/chapter-steps.webp b/ch04/01_main-chapter-code/figures/chapter-steps.webp
deleted file mode 100644
index aa3c17c..0000000
Binary files a/ch04/01_main-chapter-code/figures/chapter-steps.webp and /dev/null differ
diff --git a/ch04/01_main-chapter-code/figures/ffn.webp b/ch04/01_main-chapter-code/figures/ffn.webp
deleted file mode 100644
index d686cb3..0000000
Binary files a/ch04/01_main-chapter-code/figures/ffn.webp and /dev/null differ
diff --git a/ch04/01_main-chapter-code/figures/generate-text.webp b/ch04/01_main-chapter-code/figures/generate-text.webp
deleted file mode 100644
index d7f38e6..0000000
Binary files a/ch04/01_main-chapter-code/figures/generate-text.webp and /dev/null differ
diff --git a/ch04/01_main-chapter-code/figures/gpt-in-out.webp b/ch04/01_main-chapter-code/figures/gpt-in-out.webp
deleted file mode 100644
index 9127f29..0000000
Binary files a/ch04/01_main-chapter-code/figures/gpt-in-out.webp and /dev/null differ
diff --git a/ch04/01_main-chapter-code/figures/gpt.webp b/ch04/01_main-chapter-code/figures/gpt.webp
deleted file mode 100644
index f1a39fa..0000000
Binary files a/ch04/01_main-chapter-code/figures/gpt.webp and /dev/null differ
diff --git a/ch04/01_main-chapter-code/figures/iterative-gen.webp b/ch04/01_main-chapter-code/figures/iterative-gen.webp
deleted file mode 100644
index fa5fad2..0000000
Binary files a/ch04/01_main-chapter-code/figures/iterative-gen.webp and /dev/null differ
diff --git a/ch04/01_main-chapter-code/figures/iterative-generate.webp b/ch04/01_main-chapter-code/figures/iterative-generate.webp
deleted file mode 100644
index 8a1eb1b..0000000
Binary files a/ch04/01_main-chapter-code/figures/iterative-generate.webp and /dev/null differ
diff --git a/ch04/01_main-chapter-code/figures/layernorm.webp b/ch04/01_main-chapter-code/figures/layernorm.webp
deleted file mode 100644
index 38cf3a7..0000000
Binary files a/ch04/01_main-chapter-code/figures/layernorm.webp and /dev/null differ
diff --git a/ch04/01_main-chapter-code/figures/layernorm2.webp b/ch04/01_main-chapter-code/figures/layernorm2.webp
deleted file mode 100644
index 55821a5..0000000
Binary files a/ch04/01_main-chapter-code/figures/layernorm2.webp and /dev/null differ
diff --git a/ch04/01_main-chapter-code/figures/mental-model-2.webp b/ch04/01_main-chapter-code/figures/mental-model-2.webp
deleted file mode 100644
index 639175f..0000000
Binary files a/ch04/01_main-chapter-code/figures/mental-model-2.webp and /dev/null differ
diff --git a/ch04/01_main-chapter-code/figures/mental-model-3.webp b/ch04/01_main-chapter-code/figures/mental-model-3.webp
deleted file mode 100644
index cbf41d6..0000000
Binary files a/ch04/01_main-chapter-code/figures/mental-model-3.webp and /dev/null differ
diff --git a/ch04/01_main-chapter-code/figures/mental-model-final.webp b/ch04/01_main-chapter-code/figures/mental-model-final.webp
deleted file mode 100644
index 03817ec..0000000
Binary files a/ch04/01_main-chapter-code/figures/mental-model-final.webp and /dev/null differ
diff --git a/ch04/01_main-chapter-code/figures/mental-model.webp b/ch04/01_main-chapter-code/figures/mental-model.webp
deleted file mode 100644
index 16a9c19..0000000
Binary files a/ch04/01_main-chapter-code/figures/mental-model.webp and /dev/null differ
diff --git a/ch04/01_main-chapter-code/figures/overview-after-ln.webp b/ch04/01_main-chapter-code/figures/overview-after-ln.webp
deleted file mode 100644
index ed6530e..0000000
Binary files a/ch04/01_main-chapter-code/figures/overview-after-ln.webp and /dev/null differ
diff --git a/ch04/01_main-chapter-code/figures/shortcut-example.webp b/ch04/01_main-chapter-code/figures/shortcut-example.webp
deleted file mode 100644
index 32e7018..0000000
Binary files a/ch04/01_main-chapter-code/figures/shortcut-example.webp and /dev/null differ
diff --git a/ch04/01_main-chapter-code/figures/transformer-block.webp b/ch04/01_main-chapter-code/figures/transformer-block.webp
deleted file mode 100644
index 6dc41d0..0000000
Binary files a/ch04/01_main-chapter-code/figures/transformer-block.webp and /dev/null differ
diff --git a/ch04/01_main-chapter-code/figures/use-gpt.webp b/ch04/01_main-chapter-code/figures/use-gpt.webp
deleted file mode 100644
index b83a4b7..0000000
Binary files a/ch04/01_main-chapter-code/figures/use-gpt.webp and /dev/null differ
"
]
},
{
@@ -1506,7 +1514,7 @@
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
- "version": "3.11.4"
+ "version": "3.10.6"
}
},
"nbformat": 4,
diff --git a/ch04/01_main-chapter-code/figures/chapter-steps.webp b/ch04/01_main-chapter-code/figures/chapter-steps.webp
deleted file mode 100644
index aa3c17c..0000000
Binary files a/ch04/01_main-chapter-code/figures/chapter-steps.webp and /dev/null differ
diff --git a/ch04/01_main-chapter-code/figures/ffn.webp b/ch04/01_main-chapter-code/figures/ffn.webp
deleted file mode 100644
index d686cb3..0000000
Binary files a/ch04/01_main-chapter-code/figures/ffn.webp and /dev/null differ
diff --git a/ch04/01_main-chapter-code/figures/generate-text.webp b/ch04/01_main-chapter-code/figures/generate-text.webp
deleted file mode 100644
index d7f38e6..0000000
Binary files a/ch04/01_main-chapter-code/figures/generate-text.webp and /dev/null differ
diff --git a/ch04/01_main-chapter-code/figures/gpt-in-out.webp b/ch04/01_main-chapter-code/figures/gpt-in-out.webp
deleted file mode 100644
index 9127f29..0000000
Binary files a/ch04/01_main-chapter-code/figures/gpt-in-out.webp and /dev/null differ
diff --git a/ch04/01_main-chapter-code/figures/gpt.webp b/ch04/01_main-chapter-code/figures/gpt.webp
deleted file mode 100644
index f1a39fa..0000000
Binary files a/ch04/01_main-chapter-code/figures/gpt.webp and /dev/null differ
diff --git a/ch04/01_main-chapter-code/figures/iterative-gen.webp b/ch04/01_main-chapter-code/figures/iterative-gen.webp
deleted file mode 100644
index fa5fad2..0000000
Binary files a/ch04/01_main-chapter-code/figures/iterative-gen.webp and /dev/null differ
diff --git a/ch04/01_main-chapter-code/figures/iterative-generate.webp b/ch04/01_main-chapter-code/figures/iterative-generate.webp
deleted file mode 100644
index 8a1eb1b..0000000
Binary files a/ch04/01_main-chapter-code/figures/iterative-generate.webp and /dev/null differ
diff --git a/ch04/01_main-chapter-code/figures/layernorm.webp b/ch04/01_main-chapter-code/figures/layernorm.webp
deleted file mode 100644
index 38cf3a7..0000000
Binary files a/ch04/01_main-chapter-code/figures/layernorm.webp and /dev/null differ
diff --git a/ch04/01_main-chapter-code/figures/layernorm2.webp b/ch04/01_main-chapter-code/figures/layernorm2.webp
deleted file mode 100644
index 55821a5..0000000
Binary files a/ch04/01_main-chapter-code/figures/layernorm2.webp and /dev/null differ
diff --git a/ch04/01_main-chapter-code/figures/mental-model-2.webp b/ch04/01_main-chapter-code/figures/mental-model-2.webp
deleted file mode 100644
index 639175f..0000000
Binary files a/ch04/01_main-chapter-code/figures/mental-model-2.webp and /dev/null differ
diff --git a/ch04/01_main-chapter-code/figures/mental-model-3.webp b/ch04/01_main-chapter-code/figures/mental-model-3.webp
deleted file mode 100644
index cbf41d6..0000000
Binary files a/ch04/01_main-chapter-code/figures/mental-model-3.webp and /dev/null differ
diff --git a/ch04/01_main-chapter-code/figures/mental-model-final.webp b/ch04/01_main-chapter-code/figures/mental-model-final.webp
deleted file mode 100644
index 03817ec..0000000
Binary files a/ch04/01_main-chapter-code/figures/mental-model-final.webp and /dev/null differ
diff --git a/ch04/01_main-chapter-code/figures/mental-model.webp b/ch04/01_main-chapter-code/figures/mental-model.webp
deleted file mode 100644
index 16a9c19..0000000
Binary files a/ch04/01_main-chapter-code/figures/mental-model.webp and /dev/null differ
diff --git a/ch04/01_main-chapter-code/figures/overview-after-ln.webp b/ch04/01_main-chapter-code/figures/overview-after-ln.webp
deleted file mode 100644
index ed6530e..0000000
Binary files a/ch04/01_main-chapter-code/figures/overview-after-ln.webp and /dev/null differ
diff --git a/ch04/01_main-chapter-code/figures/shortcut-example.webp b/ch04/01_main-chapter-code/figures/shortcut-example.webp
deleted file mode 100644
index 32e7018..0000000
Binary files a/ch04/01_main-chapter-code/figures/shortcut-example.webp and /dev/null differ
diff --git a/ch04/01_main-chapter-code/figures/transformer-block.webp b/ch04/01_main-chapter-code/figures/transformer-block.webp
deleted file mode 100644
index 6dc41d0..0000000
Binary files a/ch04/01_main-chapter-code/figures/transformer-block.webp and /dev/null differ
diff --git a/ch04/01_main-chapter-code/figures/use-gpt.webp b/ch04/01_main-chapter-code/figures/use-gpt.webp
deleted file mode 100644
index b83a4b7..0000000
Binary files a/ch04/01_main-chapter-code/figures/use-gpt.webp and /dev/null differ