diff --git a/.github/workflows/basic-tests.yml b/.github/workflows/basic-tests.yml
index f89af3a..a84d33e 100644
--- a/.github/workflows/basic-tests.yml
+++ b/.github/workflows/basic-tests.yml
@@ -33,6 +33,7 @@ jobs:
- name: Test Selected Python Scripts
run: |
pytest ch04/01_main-chapter-code/tests.py
+ pytest ch05/01_main-chapter-code/tests.py
pytest appendix-A/02_installing-python-libraries/tests.py
- name: Validate Selected Jupyter Notebooks
diff --git a/.github/workflows/pep8-linter.yml b/.github/workflows/pep8-linter.yml
index 731f7be..0a95d84 100644
--- a/.github/workflows/pep8-linter.yml
+++ b/.github/workflows/pep8-linter.yml
@@ -18,4 +18,4 @@ jobs:
- name: Install flake8
run: pip install flake8
- name: Run flake8 with exceptions
- run: flake8 . --max-line-length=120 --ignore=W504,E402,E731,C406,E741,E722,E226
+ run: flake8 . --max-line-length=140 --ignore=W504,E402,E731,C406,E741,E722,E226
diff --git a/README.md b/README.md
index e691238..c17b6e0 100644
--- a/README.md
+++ b/README.md
@@ -7,9 +7,9 @@ This repository contains the code for coding, pretraining, and finetuning a GPT-
- +
+ -In [*Build a Large Language Model (From Scratch)*](http://mng.bz/orYv), you'll discover how LLMs work from the inside out. In this book, I'll guide you step by step through creating your own LLM, explaining each stage with clear text, diagrams, and examples.
+In [*Build a Large Language Model (From Scratch)*](http://mng.bz/orYv), you'll discover how LLMs work from the inside out. In this book, I'll guide you step by step through creating your own LLM, explaining each stage with clear text, diagrams, and examples.
The method described in this book for training and developing your own small-but-functional model for educational purposes mirrors the approach used in creating large-scale foundational models such as those behind ChatGPT.
@@ -37,7 +37,7 @@ Alternatively, you can view this and other files on GitHub at [https://github.co
| Ch 2: Working with Text Data | - [ch02.ipynb](ch02/01_main-chapter-code/ch02.ipynb)
-In [*Build a Large Language Model (From Scratch)*](http://mng.bz/orYv), you'll discover how LLMs work from the inside out. In this book, I'll guide you step by step through creating your own LLM, explaining each stage with clear text, diagrams, and examples.
+In [*Build a Large Language Model (From Scratch)*](http://mng.bz/orYv), you'll discover how LLMs work from the inside out. In this book, I'll guide you step by step through creating your own LLM, explaining each stage with clear text, diagrams, and examples.
The method described in this book for training and developing your own small-but-functional model for educational purposes mirrors the approach used in creating large-scale foundational models such as those behind ChatGPT.
@@ -37,7 +37,7 @@ Alternatively, you can view this and other files on GitHub at [https://github.co
| Ch 2: Working with Text Data | - [ch02.ipynb](ch02/01_main-chapter-code/ch02.ipynb)
- [dataloader.ipynb](ch02/01_main-chapter-code/dataloader.ipynb) (summary)
- [exercise-solutions.ipynb](ch02/01_main-chapter-code/exercise-solutions.ipynb) | [./ch02](./ch02) |
| Ch 3: Coding Attention Mechanisms | - [ch03.ipynb](ch03/01_main-chapter-code/ch03.ipynb)
- [multihead-attention.ipynb](ch03/01_main-chapter-code/multihead-attention.ipynb) (summary)
- [exercise-solutions.ipynb](ch03/01_main-chapter-code/exercise-solutions.ipynb)| [./ch03](./ch03) |
| Ch 4: Implementing a GPT Model from Scratch | - [ch04.ipynb](ch04/01_main-chapter-code/ch04.ipynb)
- [gpt.py](ch04/01_main-chapter-code/gpt.py) (summary)
- [exercise-solutions.ipynb](ch04/01_main-chapter-code/exercise-solutions.ipynb) | [./ch04](./ch04) |
-| Ch 5: Pretraining on Unlabeled Data | - [ch05.ipynb](ch05/01_main-chapter-code/ch05.ipynb) | [./ch05](./ch05) |
+| Ch 5: Pretraining on Unlabeled Data | - [ch05.ipynb](ch05/01_main-chapter-code/ch05.ipynb)
- [train.py](ch05/01_main-chapter-code/train.py) (summary)
- [generate.py](ch05/01_main-chapter-code/generate.py) (summary) | [./ch05](./ch05) |
| Ch 6: Finetuning for Text Classification | Q2 2024 | ... |
| Ch 7: Finetuning with Human Feedback | Q2 2024 | ... |
| Ch 8: Using Large Language Models in Practice | Q2/3 2024 | ... |
@@ -58,4 +58,3 @@ Alternatively, you can view this and other files on GitHub at [https://github.co
Shown below is a mental model summarizing the contents covered in this book.
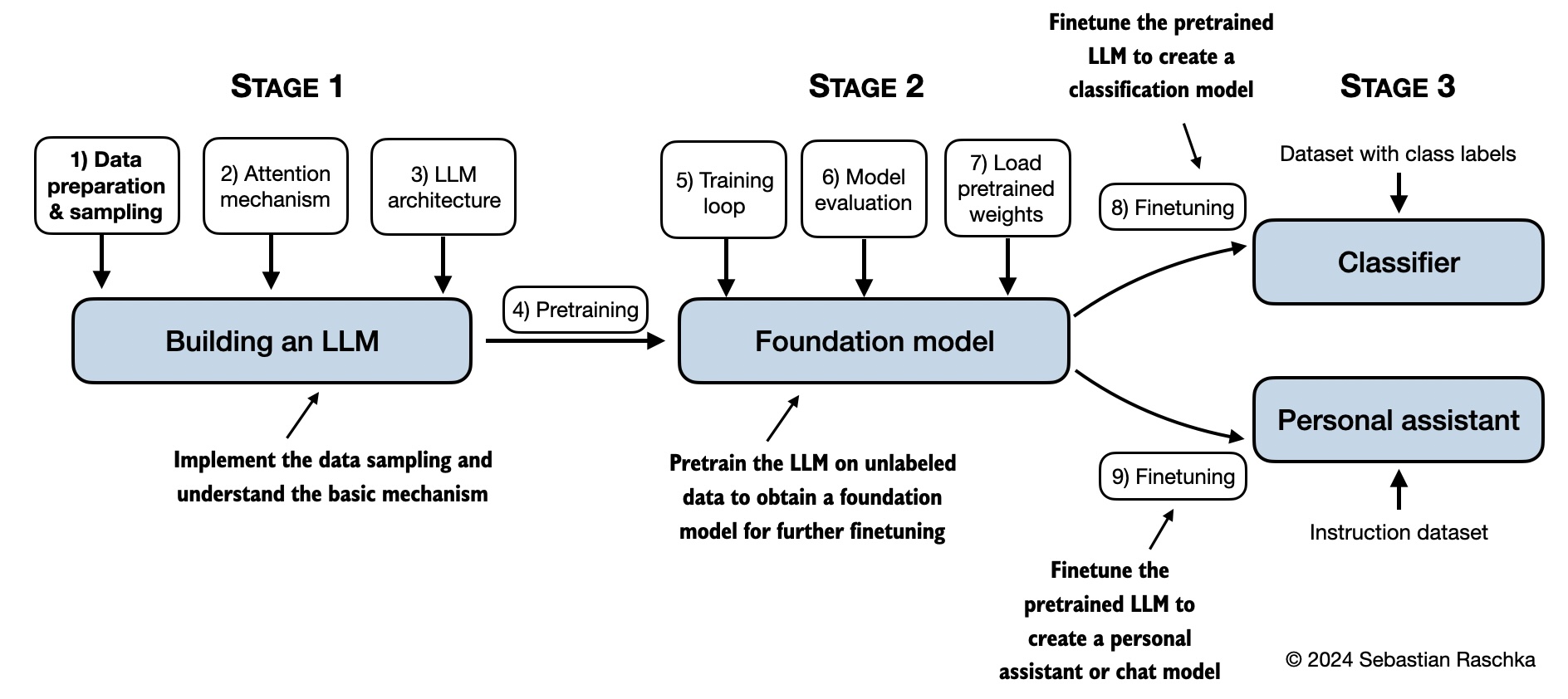 -
diff --git a/appendix-A/02_installing-python-libraries/python_environment_check.ipynb b/appendix-A/02_installing-python-libraries/python_environment_check.ipynb
index d086d99..cffd5a7 100644
--- a/appendix-A/02_installing-python-libraries/python_environment_check.ipynb
+++ b/appendix-A/02_installing-python-libraries/python_environment_check.ipynb
@@ -1,5 +1,16 @@
{
"cells": [
+ {
+ "cell_type": "markdown",
+ "id": "c31e08b0-f551-4d67-b95e-41f49de3b392",
+ "metadata": {},
+ "source": [
+ "\n",
+ "Supplementary code for \"Build a Large Language Model From Scratch\": https://www.manning.com/books/build-a-large-language-model-from-scratch by Sebastian Raschka
-
diff --git a/appendix-A/02_installing-python-libraries/python_environment_check.ipynb b/appendix-A/02_installing-python-libraries/python_environment_check.ipynb
index d086d99..cffd5a7 100644
--- a/appendix-A/02_installing-python-libraries/python_environment_check.ipynb
+++ b/appendix-A/02_installing-python-libraries/python_environment_check.ipynb
@@ -1,5 +1,16 @@
{
"cells": [
+ {
+ "cell_type": "markdown",
+ "id": "c31e08b0-f551-4d67-b95e-41f49de3b392",
+ "metadata": {},
+ "source": [
+ "\n",
+ "Supplementary code for \"Build a Large Language Model From Scratch\": https://www.manning.com/books/build-a-large-language-model-from-scratch by Sebastian Raschka
\n",
+ "Code repository: https://github.com/rasbt/LLMs-from-scratch\n",
+ ""
+ ]
+ },
{
"cell_type": "code",
"execution_count": 1,
@@ -45,7 +56,7 @@
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
- "version": "3.10.12"
+ "version": "3.10.6"
}
},
"nbformat": 4,
diff --git a/appendix-A/02_installing-python-libraries/python_environment_check.py b/appendix-A/02_installing-python-libraries/python_environment_check.py
index 49a1c80..34b25a5 100644
--- a/appendix-A/02_installing-python-libraries/python_environment_check.py
+++ b/appendix-A/02_installing-python-libraries/python_environment_check.py
@@ -1,4 +1,7 @@
-# Sebastian Raschka, 2024
+# Copyright (c) Sebastian Raschka under Apache License 2.0 (see LICENSE.txt).
+# Source for "Build a Large Language Model From Scratch"
+# - https://www.manning.com/books/build-a-large-language-model-from-scratch
+# Code: https://github.com/rasbt/LLMs-from-scratch
import importlib
from os.path import dirname, join, realpath
diff --git a/appendix-A/02_installing-python-libraries/tests.py b/appendix-A/02_installing-python-libraries/tests.py
index 911dc81..de5fdfb 100644
--- a/appendix-A/02_installing-python-libraries/tests.py
+++ b/appendix-A/02_installing-python-libraries/tests.py
@@ -1,3 +1,10 @@
+# Copyright (c) Sebastian Raschka under Apache License 2.0 (see LICENSE.txt).
+# Source for "Build a Large Language Model From Scratch"
+# - https://www.manning.com/books/build-a-large-language-model-from-scratch
+# Code: https://github.com/rasbt/LLMs-from-scratch
+
+# File for internal use (unit tests)
+
from python_environment_check import main
diff --git a/appendix-A/03_main-chapter-code/DDP-script.py b/appendix-A/03_main-chapter-code/DDP-script.py
index f93ed32..09c54b0 100644
--- a/appendix-A/03_main-chapter-code/DDP-script.py
+++ b/appendix-A/03_main-chapter-code/DDP-script.py
@@ -1,3 +1,8 @@
+# Copyright (c) Sebastian Raschka under Apache License 2.0 (see LICENSE.txt).
+# Source for "Build a Large Language Model From Scratch"
+# - https://www.manning.com/books/build-a-large-language-model-from-scratch
+# Code: https://github.com/rasbt/LLMs-from-scratch
+
# Appendix A: Introduction to PyTorch (Part 3)
import torch
diff --git a/appendix-A/03_main-chapter-code/code-part1.ipynb b/appendix-A/03_main-chapter-code/code-part1.ipynb
index 71490fa..0589d7c 100644
--- a/appendix-A/03_main-chapter-code/code-part1.ipynb
+++ b/appendix-A/03_main-chapter-code/code-part1.ipynb
@@ -1,5 +1,16 @@
{
"cells": [
+ {
+ "cell_type": "markdown",
+ "id": "f896245e-57c4-48fd-854f-9e43f22e10c9",
+ "metadata": {},
+ "source": [
+ "\n",
+ "Supplementary code for \"Build a Large Language Model From Scratch\": https://www.manning.com/books/build-a-large-language-model-from-scratch by Sebastian Raschka
\n",
+ "Code repository: https://github.com/rasbt/LLMs-from-scratch\n",
+ ""
+ ]
+ },
{
"cell_type": "markdown",
"id": "ca7fc8a0-280c-4979-b0c7-fc3a99b3b785",
diff --git a/appendix-A/03_main-chapter-code/code-part2.ipynb b/appendix-A/03_main-chapter-code/code-part2.ipynb
index 8a11b20..0bd3f4b 100644
--- a/appendix-A/03_main-chapter-code/code-part2.ipynb
+++ b/appendix-A/03_main-chapter-code/code-part2.ipynb
@@ -1,5 +1,15 @@
{
"cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "\n",
+ "Supplementary code for \"Build a Large Language Model From Scratch\": https://www.manning.com/books/build-a-large-language-model-from-scratch by Sebastian Raschka
\n",
+ "Code repository: https://github.com/rasbt/LLMs-from-scratch\n",
+ ""
+ ]
+ },
{
"cell_type": "markdown",
"metadata": {
diff --git a/appendix-A/03_main-chapter-code/exercise-solutions.ipynb b/appendix-A/03_main-chapter-code/exercise-solutions.ipynb
index f934b2d..bcbdd1d 100644
--- a/appendix-A/03_main-chapter-code/exercise-solutions.ipynb
+++ b/appendix-A/03_main-chapter-code/exercise-solutions.ipynb
@@ -1,5 +1,15 @@
{
"cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "\n",
+ "Supplementary code for \"Build a Large Language Model From Scratch\": https://www.manning.com/books/build-a-large-language-model-from-scratch by Sebastian Raschka
\n",
+ "Code repository: https://github.com/rasbt/LLMs-from-scratch\n",
+ ""
+ ]
+ },
{
"cell_type": "markdown",
"metadata": {},
diff --git a/appendix-D/01_main-chapter-code/appendix-D.ipynb b/appendix-D/01_main-chapter-code/appendix-D.ipynb
index a6f3494..1710394 100644
--- a/appendix-D/01_main-chapter-code/appendix-D.ipynb
+++ b/appendix-D/01_main-chapter-code/appendix-D.ipynb
@@ -1,5 +1,16 @@
{
"cells": [
+ {
+ "cell_type": "markdown",
+ "id": "9a5936bd-af17-4a7e-a4d2-e910411708ea",
+ "metadata": {},
+ "source": [
+ "\n",
+ "Supplementary code for \"Build a Large Language Model From Scratch\": https://www.manning.com/books/build-a-large-language-model-from-scratch by Sebastian Raschka
\n",
+ "Code repository: https://github.com/rasbt/LLMs-from-scratch\n",
+ ""
+ ]
+ },
{
"cell_type": "markdown",
"id": "af53bcb1-ff9d-49c7-a0bc-5b8d32ff975b",
@@ -739,7 +750,7 @@
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
- "version": "3.11.4"
+ "version": "3.10.6"
}
},
"nbformat": 4,
diff --git a/appendix-D/01_main-chapter-code/previous_chapters.py b/appendix-D/01_main-chapter-code/previous_chapters.py
index 6297085..719d791 100644
--- a/appendix-D/01_main-chapter-code/previous_chapters.py
+++ b/appendix-D/01_main-chapter-code/previous_chapters.py
@@ -1,3 +1,8 @@
+# Copyright (c) Sebastian Raschka under Apache License 2.0 (see LICENSE.txt).
+# Source for "Build a Large Language Model From Scratch"
+# - https://www.manning.com/books/build-a-large-language-model-from-scratch
+# Code: https://github.com/rasbt/LLMs-from-scratch
+
# This file collects all the relevant code that we covered thus far
# throughout Chapters 2-4.
# This file can be run as a standalone script.
diff --git a/ch02/01_main-chapter-code/ch02.ipynb b/ch02/01_main-chapter-code/ch02.ipynb
index d75558e..065df85 100644
--- a/ch02/01_main-chapter-code/ch02.ipynb
+++ b/ch02/01_main-chapter-code/ch02.ipynb
@@ -1,5 +1,16 @@
{
"cells": [
+ {
+ "cell_type": "markdown",
+ "id": "d95f841a-63c9-41d4-aea1-496b3d2024dd",
+ "metadata": {},
+ "source": [
+ "\n",
+ "Supplementary code for \"Build a Large Language Model From Scratch\": https://www.manning.com/books/build-a-large-language-model-from-scratch by Sebastian Raschka
\n",
+ "Code repository: https://github.com/rasbt/LLMs-from-scratch\n",
+ ""
+ ]
+ },
{
"cell_type": "markdown",
"id": "25aa40e3-5109-433f-9153-f5770531fe94",
diff --git a/ch02/01_main-chapter-code/dataloader.ipynb b/ch02/01_main-chapter-code/dataloader.ipynb
index f02c7f8..b1d9c4e 100644
--- a/ch02/01_main-chapter-code/dataloader.ipynb
+++ b/ch02/01_main-chapter-code/dataloader.ipynb
@@ -1,5 +1,16 @@
{
"cells": [
+ {
+ "cell_type": "markdown",
+ "id": "6e2a4891-c257-4d6b-afb3-e8fef39d0437",
+ "metadata": {},
+ "source": [
+ "\n",
+ "Supplementary code for \"Build a Large Language Model From Scratch\": https://www.manning.com/books/build-a-large-language-model-from-scratch by Sebastian Raschka
\n",
+ "Code repository: https://github.com/rasbt/LLMs-from-scratch\n",
+ ""
+ ]
+ },
{
"cell_type": "markdown",
"id": "6f678e62-7bcb-4405-86ae-dce94f494303",
diff --git a/ch02/01_main-chapter-code/exercise-solutions.ipynb b/ch02/01_main-chapter-code/exercise-solutions.ipynb
index bc479d0..402b729 100644
--- a/ch02/01_main-chapter-code/exercise-solutions.ipynb
+++ b/ch02/01_main-chapter-code/exercise-solutions.ipynb
@@ -1,5 +1,16 @@
{
"cells": [
+ {
+ "cell_type": "markdown",
+ "id": "99311e42-8467-458d-b918-632c8840b96f",
+ "metadata": {},
+ "source": [
+ "\n",
+ "Supplementary code for \"Build a Large Language Model From Scratch\": https://www.manning.com/books/build-a-large-language-model-from-scratch by Sebastian Raschka
\n",
+ "Code repository: https://github.com/rasbt/LLMs-from-scratch\n",
+ ""
+ ]
+ },
{
"cell_type": "markdown",
"id": "ab88d307-61ba-45ef-89bc-e3569443dfca",
@@ -366,7 +377,7 @@
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
- "version": "3.11.4"
+ "version": "3.10.6"
}
},
"nbformat": 4,
diff --git a/ch02/02_bonus_bytepair-encoder/bpe_openai_gpt2.py b/ch02/02_bonus_bytepair-encoder/bpe_openai_gpt2.py
index 16e0ee2..79b44c8 100644
--- a/ch02/02_bonus_bytepair-encoder/bpe_openai_gpt2.py
+++ b/ch02/02_bonus_bytepair-encoder/bpe_openai_gpt2.py
@@ -1,3 +1,30 @@
+# Source: https://github.com/openai/gpt-2/blob/master/src/encoder.py
+# License:
+# Modified MIT License
+
+# Software Copyright (c) 2019 OpenAI
+
+# We don’t claim ownership of the content you create with GPT-2, so it is yours to do with as you please.
+# We only ask that you use GPT-2 responsibly and clearly indicate your content was created using GPT-2.
+
+# Permission is hereby granted, free of charge, to any person obtaining a copy of this software and
+# associated documentation files (the "Software"), to deal in the Software without restriction,
+# including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense,
+# and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so,
+# subject to the following conditions:
+
+# The above copyright notice and this permission notice shall be included
+# in all copies or substantial portions of the Software.
+# The above copyright notice and this permission notice need not be included
+# with content created by the Software.
+
+# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED,
+# INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS
+# BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT,
+# TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE
+# OR OTHER DEALINGS IN THE SOFTWARE.
+
import os
import json
import regex as re
diff --git a/ch02/02_bonus_bytepair-encoder/compare-bpe-tiktoken.ipynb b/ch02/02_bonus_bytepair-encoder/compare-bpe-tiktoken.ipynb
index 84ac57a..3a898ef 100644
--- a/ch02/02_bonus_bytepair-encoder/compare-bpe-tiktoken.ipynb
+++ b/ch02/02_bonus_bytepair-encoder/compare-bpe-tiktoken.ipynb
@@ -1,5 +1,16 @@
{
"cells": [
+ {
+ "cell_type": "markdown",
+ "id": "c503e5ef-6bb4-45c3-ac49-0e016cedd8d0",
+ "metadata": {},
+ "source": [
+ "\n",
+ "Supplementary code for \"Build a Large Language Model From Scratch\": https://www.manning.com/books/build-a-large-language-model-from-scratch by Sebastian Raschka
\n",
+ "Code repository: https://github.com/rasbt/LLMs-from-scratch\n",
+ ""
+ ]
+ },
{
"cell_type": "markdown",
"id": "8a9e554f-58e3-4787-832d-d149add1b857",
@@ -455,7 +466,7 @@
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
- "version": "3.10.12"
+ "version": "3.10.6"
}
},
"nbformat": 4,
diff --git a/ch03/01_main-chapter-code/ch03.ipynb b/ch03/01_main-chapter-code/ch03.ipynb
index 6ab2b91..be7f378 100644
--- a/ch03/01_main-chapter-code/ch03.ipynb
+++ b/ch03/01_main-chapter-code/ch03.ipynb
@@ -1,5 +1,16 @@
{
"cells": [
+ {
+ "cell_type": "markdown",
+ "id": "1ae38945-39dd-45dc-ad4f-da7a4404241f",
+ "metadata": {},
+ "source": [
+ "\n",
+ "Supplementary code for \"Build a Large Language Model From Scratch\": https://www.manning.com/books/build-a-large-language-model-from-scratch by Sebastian Raschka
\n",
+ "Code repository: https://github.com/rasbt/LLMs-from-scratch\n",
+ ""
+ ]
+ },
{
"cell_type": "markdown",
"id": "8bfa70ec-5c4c-40e8-b923-16f8167e3181",
diff --git a/ch03/01_main-chapter-code/exercise-solutions.ipynb b/ch03/01_main-chapter-code/exercise-solutions.ipynb
index e008085..3576e61 100644
--- a/ch03/01_main-chapter-code/exercise-solutions.ipynb
+++ b/ch03/01_main-chapter-code/exercise-solutions.ipynb
@@ -1,5 +1,16 @@
{
"cells": [
+ {
+ "cell_type": "markdown",
+ "id": "78224549-3637-44b0-aed1-8ff889c65192",
+ "metadata": {},
+ "source": [
+ "\n",
+ "Supplementary code for \"Build a Large Language Model From Scratch\": https://www.manning.com/books/build-a-large-language-model-from-scratch by Sebastian Raschka
\n",
+ "Code repository: https://github.com/rasbt/LLMs-from-scratch\n",
+ ""
+ ]
+ },
{
"cell_type": "markdown",
"id": "51c9672d-8d0c-470d-ac2d-1271f8ec3f14",
@@ -300,7 +311,7 @@
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
- "version": "3.10.12"
+ "version": "3.10.6"
}
},
"nbformat": 4,
diff --git a/ch03/01_main-chapter-code/multihead-attention.ipynb b/ch03/01_main-chapter-code/multihead-attention.ipynb
index 47b19b7..f03efd8 100644
--- a/ch03/01_main-chapter-code/multihead-attention.ipynb
+++ b/ch03/01_main-chapter-code/multihead-attention.ipynb
@@ -1,5 +1,16 @@
{
"cells": [
+ {
+ "cell_type": "markdown",
+ "id": "be16f748-e12a-44a9-ad2b-81e320efdac4",
+ "metadata": {},
+ "source": [
+ "\n",
+ "Supplementary code for \"Build a Large Language Model From Scratch\": https://www.manning.com/books/build-a-large-language-model-from-scratch by Sebastian Raschka
\n",
+ "Code repository: https://github.com/rasbt/LLMs-from-scratch\n",
+ ""
+ ]
+ },
{
"cell_type": "markdown",
"id": "6f678e62-7bcb-4405-86ae-dce94f494303",
diff --git a/ch03/02_bonus_efficient-multihead-attention/mha-implementations.ipynb b/ch03/02_bonus_efficient-multihead-attention/mha-implementations.ipynb
index d3500e1..9e5e460 100644
--- a/ch03/02_bonus_efficient-multihead-attention/mha-implementations.ipynb
+++ b/ch03/02_bonus_efficient-multihead-attention/mha-implementations.ipynb
@@ -1,5 +1,16 @@
{
"cells": [
+ {
+ "cell_type": "markdown",
+ "id": "e2e65c03-36d4-413f-9b23-5cdd816729ab",
+ "metadata": {},
+ "source": [
+ "\n",
+ "Supplementary code for \"Build a Large Language Model From Scratch\": https://www.manning.com/books/build-a-large-language-model-from-scratch by Sebastian Raschka
\n",
+ "Code repository: https://github.com/rasbt/LLMs-from-scratch\n",
+ ""
+ ]
+ },
{
"cell_type": "markdown",
"id": "6f678e62-7bcb-4405-86ae-dce94f494303",
diff --git a/ch04/01_main-chapter-code/ch04.ipynb b/ch04/01_main-chapter-code/ch04.ipynb
index 3759538..a74c7b8 100644
--- a/ch04/01_main-chapter-code/ch04.ipynb
+++ b/ch04/01_main-chapter-code/ch04.ipynb
@@ -1,5 +1,16 @@
{
"cells": [
+ {
+ "cell_type": "markdown",
+ "id": "08f4321d-d32a-4a90-bfc7-e923f316b2f8",
+ "metadata": {},
+ "source": [
+ "\n",
+ "Supplementary code for \"Build a Large Language Model From Scratch\": https://www.manning.com/books/build-a-large-language-model-from-scratch by Sebastian Raschka
\n",
+ "Code repository: https://github.com/rasbt/LLMs-from-scratch\n",
+ ""
+ ]
+ },
{
"cell_type": "markdown",
"id": "ce9295b2-182b-490b-8325-83a67c4a001d",
diff --git a/ch04/01_main-chapter-code/exercise-solutions.ipynb b/ch04/01_main-chapter-code/exercise-solutions.ipynb
index ed2135e..74c213f 100644
--- a/ch04/01_main-chapter-code/exercise-solutions.ipynb
+++ b/ch04/01_main-chapter-code/exercise-solutions.ipynb
@@ -1,5 +1,16 @@
{
"cells": [
+ {
+ "cell_type": "markdown",
+ "id": "ba450fb1-8a26-4894-ab7a-5d7bfefe90ce",
+ "metadata": {},
+ "source": [
+ "\n",
+ "Supplementary code for \"Build a Large Language Model From Scratch\": https://www.manning.com/books/build-a-large-language-model-from-scratch by Sebastian Raschka
\n",
+ "Code repository: https://github.com/rasbt/LLMs-from-scratch\n",
+ ""
+ ]
+ },
{
"cell_type": "markdown",
"id": "51c9672d-8d0c-470d-ac2d-1271f8ec3f14",
@@ -373,7 +384,7 @@
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
- "version": "3.10.12"
+ "version": "3.10.6"
}
},
"nbformat": 4,
diff --git a/ch04/01_main-chapter-code/previous_chapters.py b/ch04/01_main-chapter-code/previous_chapters.py
index 5e067a4..2751e7a 100644
--- a/ch04/01_main-chapter-code/previous_chapters.py
+++ b/ch04/01_main-chapter-code/previous_chapters.py
@@ -1,3 +1,8 @@
+# Copyright (c) Sebastian Raschka under Apache License 2.0 (see LICENSE.txt).
+# Source for "Build a Large Language Model From Scratch"
+# - https://www.manning.com/books/build-a-large-language-model-from-scratch
+# Code: https://github.com/rasbt/LLMs-from-scratch
+
import tiktoken
import torch
import torch.nn as nn
diff --git a/ch04/01_main-chapter-code/tests.py b/ch04/01_main-chapter-code/tests.py
index 028fec7..8baa23f 100644
--- a/ch04/01_main-chapter-code/tests.py
+++ b/ch04/01_main-chapter-code/tests.py
@@ -1,3 +1,10 @@
+# Copyright (c) Sebastian Raschka under Apache License 2.0 (see LICENSE.txt).
+# Source for "Build a Large Language Model From Scratch"
+# - https://www.manning.com/books/build-a-large-language-model-from-scratch
+# Code: https://github.com/rasbt/LLMs-from-scratch
+
+# File for internal use (unit tests)
+
from gpt import main
expected = """
diff --git a/ch05/01_main-chapter-code/ch05.ipynb b/ch05/01_main-chapter-code/ch05.ipynb
index 340b3af..93e71e3 100644
--- a/ch05/01_main-chapter-code/ch05.ipynb
+++ b/ch05/01_main-chapter-code/ch05.ipynb
@@ -1,5 +1,16 @@
{
"cells": [
+ {
+ "cell_type": "markdown",
+ "id": "45398736-7e89-4263-89c8-92153baff553",
+ "metadata": {},
+ "source": [
+ "\n",
+ "Supplementary code for \"Build a Large Language Model From Scratch\": https://www.manning.com/books/build-a-large-language-model-from-scratch by Sebastian Raschka
\n",
+ "Code repository: https://github.com/rasbt/LLMs-from-scratch\n",
+ ""
+ ]
+ },
{
"cell_type": "markdown",
"id": "66dd524e-864c-4012-b0a2-ccfc56e80024",
@@ -2161,7 +2172,7 @@
" response = requests.get(url, stream=True)\n",
"\n",
" # Get the total file size from headers, defaulting to 0 if not present\n",
- " file_size = int(response.headers.get('content-length', 0))\n",
+ " file_size = int(response.headers.get(\"content-length\", 0))\n",
"\n",
" # Check if file exists and has the same size\n",
" if os.path.exists(destination):\n",
@@ -2174,10 +2185,10 @@
" block_size = 1024 # 1 Kilobyte\n",
"\n",
" # Initialize the progress bar with total file size\n",
- " progress_bar_description = url.split('/')[-1] # Extract filename from URL\n",
- " with tqdm(total=file_size, unit='iB', unit_scale=True, desc=progress_bar_description) as progress_bar:\n",
+ " progress_bar_description = url.split(\"/\")[-1] # Extract filename from URL\n",
+ " with tqdm(total=file_size, unit=\"iB\", unit_scale=True, desc=progress_bar_description) as progress_bar:\n",
" # Open the destination file in binary write mode\n",
- " with open(destination, 'wb') as file:\n",
+ " with open(destination, \"wb\") as file:\n",
" # Iterate over the file data in chunks\n",
" for chunk in response.iter_content(block_size):\n",
" progress_bar.update(len(chunk)) # Update progress bar\n",
diff --git a/ch05/01_main-chapter-code/generate.py b/ch05/01_main-chapter-code/generate.py
new file mode 100644
index 0000000..29a39d4
--- /dev/null
+++ b/ch05/01_main-chapter-code/generate.py
@@ -0,0 +1,247 @@
+# Copyright (c) Sebastian Raschka under Apache License 2.0 (see LICENSE.txt).
+# Source for "Build a Large Language Model From Scratch"
+# - https://www.manning.com/books/build-a-large-language-model-from-scratch
+# Code: https://github.com/rasbt/LLMs-from-scratch
+
+import json
+import numpy as np
+import os
+import requests
+import tensorflow as tf
+import tiktoken
+import torch
+from tqdm import tqdm
+
+# Import from local files
+from previous_chapters import GPTModel
+
+
+def text_to_token_ids(text, tokenizer):
+ encoded = tokenizer.encode(text)
+ encoded_tensor = torch.tensor(encoded).unsqueeze(0) # add batch dimension
+ return encoded_tensor
+
+
+def token_ids_to_text(token_ids, tokenizer):
+ flat = token_ids.squeeze(0) # remove batch dimension
+ return tokenizer.decode(flat.tolist())
+
+
+def download_and_load_gpt2(model_size, models_dir):
+ # Validate model size
+ allowed_sizes = ("124M", "355M", "774M", "1558M")
+ if model_size not in allowed_sizes:
+ raise ValueError(f"Model size not in {allowed_sizes}")
+
+ # Define paths
+ model_dir = os.path.join(models_dir, model_size)
+ base_url = "https://openaipublic.blob.core.windows.net/gpt-2/models"
+ filenames = [
+ "checkpoint", "encoder.json", "hparams.json",
+ "model.ckpt.data-00000-of-00001", "model.ckpt.index",
+ "model.ckpt.meta", "vocab.bpe"
+ ]
+
+ # Download files
+ os.makedirs(model_dir, exist_ok=True)
+ for filename in filenames:
+ file_url = os.path.join(base_url, model_size, filename)
+ file_path = os.path.join(model_dir, filename)
+ download_file(file_url, file_path)
+
+ # Load hparams and params
+ tf_ckpt_path = tf.train.latest_checkpoint(model_dir)
+ hparams = json.load(open(os.path.join(model_dir, "hparams.json")))
+ params = load_gpt2_params_from_tf_ckpt(tf_ckpt_path, hparams)
+
+ return hparams, params
+
+
+def download_file(url, destination):
+ # Send a GET request to download the file in streaming mode
+ response = requests.get(url, stream=True)
+
+ # Get the total file size from headers, defaulting to 0 if not present
+ file_size = int(response.headers.get("content-length", 0))
+
+ # Check if file exists and has the same size
+ if os.path.exists(destination):
+ file_size_local = os.path.getsize(destination)
+ if file_size == file_size_local:
+ print(f"File already exists and is up-to-date: {destination}")
+ return
+
+ # Define the block size for reading the file
+ block_size = 1024 # 1 Kilobyte
+
+ # Initialize the progress bar with total file size
+ progress_bar_description = url.split("/")[-1] # Extract filename from URL
+ with tqdm(total=file_size, unit="iB", unit_scale=True, desc=progress_bar_description) as progress_bar:
+ # Open the destination file in binary write mode
+ with open(destination, "wb") as file:
+ # Iterate over the file data in chunks
+ for chunk in response.iter_content(block_size):
+ progress_bar.update(len(chunk)) # Update progress bar
+ file.write(chunk) # Write the chunk to the file
+
+
+def load_gpt2_params_from_tf_ckpt(ckpt_path, hparams):
+ # Initialize parameters dictionary with empty blocks for each layer
+ params = {"blocks": [{} for _ in range(hparams["n_layer"])]}
+
+ # Iterate over each variable in the checkpoint
+ for name, _ in tf.train.list_variables(ckpt_path):
+ # Load the variable and remove singleton dimensions
+ variable_array = np.squeeze(tf.train.load_variable(ckpt_path, name))
+
+ # Process the variable name to extract relevant parts
+ variable_name_parts = name.split("/")[1:] # Skip the 'model/' prefix
+
+ # Identify the target dictionary for the variable
+ target_dict = params
+ if variable_name_parts[0].startswith("h"):
+ layer_number = int(variable_name_parts[0][1:])
+ target_dict = params["blocks"][layer_number]
+
+ # Recursively access or create nested dictionaries
+ for key in variable_name_parts[1:-1]:
+ target_dict = target_dict.setdefault(key, {})
+
+ # Assign the variable array to the last key
+ last_key = variable_name_parts[-1]
+ target_dict[last_key] = variable_array
+
+ return params
+
+
+def assign(left, right):
+ if left.shape != right.shape:
+ raise ValueError(f"Shape mismatch. Left: {left.shape}, Right: {right.shape}")
+ return torch.nn.Parameter(torch.tensor(right))
+
+
+def load_weights_into_gpt(gpt, params):
+ # Weight tying
+ gpt.pos_emb.weight = assign(gpt.pos_emb.weight, params['wpe'])
+ gpt.tok_emb.weight = assign(gpt.tok_emb.weight, params['wte'])
+
+ for b in range(len(params["blocks"])):
+ q_w, k_w, v_w = np.split((params["blocks"][b]["attn"]["c_attn"])["w"], 3, axis=-1)
+ gpt.trf_blocks[b].att.W_query.weight = assign(gpt.trf_blocks[b].att.W_query.weight, q_w.T)
+ gpt.trf_blocks[b].att.W_key.weight = assign(gpt.trf_blocks[b].att.W_key.weight, k_w.T)
+ gpt.trf_blocks[b].att.W_value.weight = assign(gpt.trf_blocks[b].att.W_value.weight, v_w.T)
+
+ q_b, k_b, v_b = np.split((params["blocks"][b]["attn"]["c_attn"])["b"], 3, axis=-1)
+ gpt.trf_blocks[b].att.W_query.bias = assign(gpt.trf_blocks[b].att.W_query.bias, q_b)
+ gpt.trf_blocks[b].att.W_key.bias = assign(gpt.trf_blocks[b].att.W_key.bias, k_b)
+ gpt.trf_blocks[b].att.W_value.bias = assign(gpt.trf_blocks[b].att.W_value.bias, v_b)
+
+ gpt.trf_blocks[b].att.out_proj.weight = assign(gpt.trf_blocks[b].att.out_proj.weight, params["blocks"][b]["attn"]["c_proj"]["w"].T)
+ gpt.trf_blocks[b].att.out_proj.bias = assign(gpt.trf_blocks[b].att.out_proj.bias, params["blocks"][b]["attn"]["c_proj"]["b"])
+
+ gpt.trf_blocks[b].ff.layers[0].weight = assign(gpt.trf_blocks[b].ff.layers[0].weight, params["blocks"][b]["mlp"]["c_fc"]["w"].T)
+ gpt.trf_blocks[b].ff.layers[0].bias = assign(gpt.trf_blocks[b].ff.layers[0].bias, params["blocks"][b]["mlp"]["c_fc"]["b"])
+ gpt.trf_blocks[b].ff.layers[2].weight = assign(gpt.trf_blocks[b].ff.layers[2].weight, params["blocks"][b]["mlp"]["c_proj"]["w"].T)
+ gpt.trf_blocks[b].ff.layers[2].bias = assign(gpt.trf_blocks[b].ff.layers[2].bias, params["blocks"][b]["mlp"]["c_proj"]["b"])
+
+ gpt.trf_blocks[b].norm1.scale = assign(gpt.trf_blocks[b].norm1.scale, params["blocks"][b]["ln_1"]["g"])
+ gpt.trf_blocks[b].norm1.shift = assign(gpt.trf_blocks[b].norm1.shift, params["blocks"][b]["ln_1"]["b"])
+ gpt.trf_blocks[b].norm2.scale = assign(gpt.trf_blocks[b].norm2.scale, params["blocks"][b]["ln_2"]["g"])
+ gpt.trf_blocks[b].norm2.shift = assign(gpt.trf_blocks[b].norm2.shift, params["blocks"][b]["ln_2"]["b"])
+
+ gpt.final_norm.scale = assign(gpt.final_norm.scale, params["g"])
+ gpt.final_norm.shift = assign(gpt.final_norm.shift, params["b"])
+ gpt.out_head.weight = assign(gpt.out_head.weight, params["wte"])
+
+
+def generate(model, idx, max_new_tokens, context_size, temperature, top_k=None):
+
+ # For-loop is the same as before: Get logits, and only focus on last time step
+ for _ in range(max_new_tokens):
+ idx_cond = idx[:, -context_size:]
+ with torch.no_grad():
+ logits = model(idx_cond)
+ logits = logits[:, -1, :]
+
+ # New: Filter logits with top_k sampling
+ if top_k is not None:
+ # Keep only top_k values
+ top_logits, _ = torch.topk(logits, top_k)
+ min_val = top_logits[:, -1]
+ logits = torch.where(logits < min_val, torch.tensor(float('-inf')).to(logits.device), logits)
+
+ # New: Apply temperature scaling
+ if temperature > 0.0:
+ logits = logits / temperature
+
+ # Apply softmax to get probabilities
+ probs = torch.softmax(logits, dim=-1) # (batch_size, context_len)
+
+ # Sample from the distribution
+ idx_next = torch.multinomial(probs, num_samples=1) # (batch_size, 1)
+
+ # Otherwise same as before: get idx of the vocab entry with the highest logits value
+ else:
+ idx_next = torch.argmax(logits, dim=-1, keepdim=True) # (batch_size, 1)
+
+ # Same as before: append sampled index to the running sequence
+ idx = torch.cat((idx, idx_next), dim=1) # (batch_size, num_tokens+1)
+
+ return idx
+
+
+def main(gpt_config, input_prompt, model_size):
+
+ device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
+
+ hparams, params = download_and_load_gpt2(model_size=model_size, models_dir="gpt2")
+
+ gpt = GPTModel(gpt_config)
+ load_weights_into_gpt(gpt, params)
+ gpt.to(device)
+
+ tokenizer = tiktoken.get_encoding("gpt2")
+
+ token_ids = generate(
+ model=gpt,
+ idx=text_to_token_ids(input_prompt, tokenizer),
+ max_new_tokens=65,
+ context_size=gpt_config["ctx_len"],
+ top_k=50,
+ temperature=1.5
+ )
+
+ print("Output text:\n", token_ids_to_text(token_ids, tokenizer))
+
+
+if __name__ == "__main__":
+
+ torch.manual_seed(123)
+
+ CHOOSE_MODEL = "gpt2-small"
+ INPUT_PROMPT = "Every effort moves you"
+
+ BASE_CONFIG = {
+ "vocab_size": 50257, # Vocabulary size
+ "ctx_len": 1024, # Context length
+ "drop_rate": 0.0, # Dropout rate
+ "qkv_bias": True # Query-key-value bias
+ }
+
+ model_configs = {
+ "gpt2-small": {"emb_dim": 768, "n_layers": 12, "n_heads": 12},
+ "gpt2-medium": {"emb_dim": 1024, "n_layers": 24, "n_heads": 16},
+ "gpt2-large": {"emb_dim": 1280, "n_layers": 36, "n_heads": 20},
+ "gpt2-xl": {"emb_dim": 1600, "n_layers": 48, "n_heads": 25},
+ }
+
+ model_sizes = {
+ "gpt2-small": "124M",
+ "gpt2-medium": "355M",
+ "gpt2-large": "774M",
+ "gpt2-xl": "1558"
+ }
+
+ BASE_CONFIG.update(model_configs[CHOOSE_MODEL])
+
+ main(BASE_CONFIG, INPUT_PROMPT, model_sizes[CHOOSE_MODEL])
diff --git a/ch05/01_main-chapter-code/tests.py b/ch05/01_main-chapter-code/tests.py
new file mode 100644
index 0000000..dea2300
--- /dev/null
+++ b/ch05/01_main-chapter-code/tests.py
@@ -0,0 +1,40 @@
+# Copyright (c) Sebastian Raschka under Apache License 2.0 (see LICENSE.txt).
+# Source for "Build a Large Language Model From Scratch"
+# - https://www.manning.com/books/build-a-large-language-model-from-scratch
+# Code: https://github.com/rasbt/LLMs-from-scratch
+
+# File for internal use (unit tests)
+
+import pytest
+from train import main
+
+
+@pytest.fixture
+def gpt_config():
+ return {
+ "vocab_size": 50257,
+ "ctx_len": 12, # small for testing efficiency
+ "emb_dim": 32, # small for testing efficiency
+ "n_heads": 4, # small for testing efficiency
+ "n_layers": 2, # small for testing efficiency
+ "drop_rate": 0.1,
+ "qkv_bias": False
+ }
+
+
+@pytest.fixture
+def other_hparams():
+ return {
+ "learning_rate": 5e-4,
+ "num_epochs": 1, # small for testing efficiency
+ "batch_size": 2,
+ "weight_decay": 0.1
+ }
+
+
+def test_main(gpt_config, other_hparams):
+ train_losses, val_losses, tokens_seen, model = main(gpt_config, other_hparams)
+
+ assert len(train_losses) == 39, "Unexpected number of training losses"
+ assert len(val_losses) == 39, "Unexpected number of validation losses"
+ assert len(tokens_seen) == 39, "Unexpected number of tokens seen"
diff --git a/ch05/01_main-chapter-code/train.py b/ch05/01_main-chapter-code/train.py
new file mode 100644
index 0000000..2bf7065
--- /dev/null
+++ b/ch05/01_main-chapter-code/train.py
@@ -0,0 +1,235 @@
+# Copyright (c) Sebastian Raschka under Apache License 2.0 (see LICENSE.txt).
+# Source for "Build a Large Language Model From Scratch"
+# - https://www.manning.com/books/build-a-large-language-model-from-scratch
+# Code: https://github.com/rasbt/LLMs-from-scratch
+
+import matplotlib.pyplot as plt
+import os
+import torch
+import urllib.request
+
+# Import from local files
+from previous_chapters import GPTModel, create_dataloader_v1, generate_text_simple
+
+
+def text_to_token_ids(text, tokenizer):
+ encoded = tokenizer.encode(text)
+ encoded_tensor = torch.tensor(encoded).unsqueeze(0) # add batch dimension
+ return encoded_tensor
+
+
+def token_ids_to_text(token_ids, tokenizer):
+ flat = token_ids.squeeze(0) # remove batch dimension
+ return tokenizer.decode(flat.tolist())
+
+
+def calc_loss_batch(input_batch, target_batch, model, device):
+ input_batch, target_batch = input_batch.to(device), target_batch.to(device)
+
+ logits = model(input_batch)
+ logits = logits.view(-1, logits.size(-1))
+ loss = torch.nn.functional.cross_entropy(logits, target_batch.view(-1))
+ return loss
+
+
+def calc_loss_loader(data_loader, model, device, num_batches=None):
+ total_loss, batches_seen = 0., 0.
+ if num_batches is None:
+ num_batches = len(data_loader)
+ for i, (input_batch, target_batch) in enumerate(data_loader):
+ if i < num_batches:
+ loss = calc_loss_batch(input_batch, target_batch, model, device)
+ total_loss += loss.item()
+ batches_seen += 1
+ else:
+ break
+ return total_loss / batches_seen
+
+
+def evaluate_model(model, train_loader, val_loader, device, eval_iter):
+ model.eval()
+ with torch.no_grad():
+ train_loss = calc_loss_loader(train_loader, model, device, num_batches=eval_iter)
+ val_loss = calc_loss_loader(val_loader, model, device, num_batches=eval_iter)
+ model.train()
+ return train_loss, val_loss
+
+
+def generate_and_print_sample(model, tokenizer, device, start_context):
+ model.eval()
+ context_size = model.pos_emb.weight.shape[0]
+ encoded = text_to_token_ids(start_context, tokenizer).to(device)
+ with torch.no_grad():
+ token_ids = generate_text_simple(
+ model=model, idx=encoded,
+ max_new_tokens=50, context_size=context_size
+ )
+ decoded_text = token_ids_to_text(token_ids, tokenizer)
+ print(decoded_text.replace("\n", " ")) # Compact print format
+ model.train()
+
+
+def train_model_simple(model, train_loader, val_loader, optimizer, device, num_epochs,
+ eval_freq, eval_iter, start_context):
+ # Initialize lists to track losses and tokens seen
+ train_losses, val_losses, track_tokens_seen = [], [], []
+ tokens_seen = 0
+ global_step = -1
+
+ # Main training loop
+ for epoch in range(num_epochs):
+ model.train() # Set model to training mode
+
+ for input_batch, target_batch in train_loader:
+ optimizer.zero_grad() # Reset loss gradients from previous epoch
+ loss = calc_loss_batch(input_batch, target_batch, model, device)
+ loss.backward() # Calculate loss gradients
+ optimizer.step() # Update model weights using loss gradients
+ tokens_seen += input_batch.numel()
+ global_step += 1
+
+ # Optional evaluation step
+ if global_step % eval_freq == 0:
+ train_loss, val_loss = evaluate_model(
+ model, train_loader, val_loader, device, eval_iter)
+ train_losses.append(train_loss)
+ val_losses.append(val_loss)
+ track_tokens_seen.append(tokens_seen)
+ print(f"Ep {epoch+1} (Step {global_step:06d}): "
+ f"Train loss {train_loss:.3f}, Val loss {val_loss:.3f}")
+
+ # Print a sample text after each epoch
+ generate_and_print_sample(
+ model, train_loader.dataset.tokenizer, device, start_context
+ )
+
+ return train_losses, val_losses, track_tokens_seen
+
+
+def plot_losses(epochs_seen, tokens_seen, train_losses, val_losses):
+ fig, ax1 = plt.subplots()
+
+ # Plot training and validation loss against epochs
+ ax1.plot(epochs_seen, train_losses, label="Training loss")
+ ax1.plot(epochs_seen, val_losses, linestyle="-.", label="Validation loss")
+ ax1.set_xlabel("Epochs")
+ ax1.set_ylabel("Loss")
+ ax1.legend(loc="upper right")
+
+ # Create a second x-axis for tokens seen
+ ax2 = ax1.twiny() # Create a second x-axis that shares the same y-axis
+ ax2.plot(tokens_seen, train_losses, alpha=0) # Invisible plot for aligning ticks
+ ax2.set_xlabel("Tokens seen")
+
+ fig.tight_layout() # Adjust layout to make room
+ # plt.show()
+
+
+def main(gpt_config, hparams):
+
+ torch.manual_seed(123)
+ device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
+
+ ##############################
+ # Download data if necessary
+ ##############################
+
+ file_path = "the-verdict.txt"
+ url = "https://raw.githubusercontent.com/rasbt/LLMs-from-scratch/main/ch02/01_main-chapter-code/the-verdict.txt"
+
+ if not os.path.exists(file_path):
+ with urllib.request.urlopen(url) as response:
+ text_data = response.read().decode('utf-8')
+ with open(file_path, "w", encoding="utf-8") as file:
+ file.write(text_data)
+ else:
+ with open(file_path, "r", encoding="utf-8") as file:
+ text_data = file.read()
+
+ ##############################
+ # Initialize model
+ ##############################
+
+ model = GPTModel(gpt_config)
+ model.to(device) # no assignment model = model.to(device) necessary for nn.Module classes
+ optimizer = torch.optim.AdamW(
+ model.parameters(), lr=hparams["learning_rate"], weight_decay=hparams["weight_decay"]
+ )
+
+ ##############################
+ # Set up dataloaders
+ ##############################
+
+ # Train/validation ratio
+ train_ratio = 0.90
+ split_idx = int(train_ratio * len(text_data))
+
+ train_loader = create_dataloader_v1(
+ text_data[:split_idx],
+ batch_size=hparams["batch_size"],
+ max_length=gpt_config["ctx_len"],
+ stride=gpt_config["ctx_len"],
+ drop_last=True,
+ shuffle=True
+ )
+
+ val_loader = create_dataloader_v1(
+ text_data[split_idx:],
+ batch_size=hparams["batch_size"],
+ max_length=gpt_config["ctx_len"],
+ stride=gpt_config["ctx_len"],
+ drop_last=False,
+ shuffle=False
+ )
+
+ ##############################
+ # Train model
+ ##############################
+
+ train_losses, val_losses, tokens_seen = train_model_simple(
+ model, train_loader, val_loader, optimizer, device,
+ num_epochs=hparams["num_epochs"], eval_freq=5, eval_iter=1,
+ start_context="Every effort moves you",
+ )
+
+ return train_losses, val_losses, tokens_seen, model
+
+
+if __name__ == "__main__":
+
+ GPT_CONFIG_124M = {
+ "vocab_size": 50257, # Vocabulary size
+ "ctx_len": 256, # Shortened context length (orig: 1024)
+ "emb_dim": 768, # Embedding dimension
+ "n_heads": 12, # Number of attention heads
+ "n_layers": 12, # Number of layers
+ "drop_rate": 0.1, # Dropout rate
+ "qkv_bias": False # Query-key-value bias
+ }
+
+ OTHER_HPARAMS = {
+ "learning_rate": 5e-4,
+ "num_epochs": 10,
+ "batch_size": 2,
+ "weight_decay": 0.1
+ }
+
+ ###########################
+ # Initiate training
+ ###########################
+
+ train_losses, val_losses, tokens_seen, model = main(GPT_CONFIG_124M, OTHER_HPARAMS)
+
+ ###########################
+ # After training
+ ###########################
+
+ # Plot results
+ epochs_tensor = torch.linspace(0, OTHER_HPARAMS["num_epochs"], len(train_losses))
+ plot_losses(epochs_tensor, tokens_seen, train_losses, val_losses)
+ plt.savefig("loss.pdf")
+
+ # Save and load model
+ torch.save(model.state_dict(), "model.pth")
+ model = GPTModel(GPT_CONFIG_124M)
+ model.load_state_dict(torch.load("model.pth"))
diff --git a/ch05/02_bonus_hparam_tuning/hparam_search.py b/ch05/02_bonus_hparam_tuning/hparam_search.py
index 46199fd..569d7e2 100644
--- a/ch05/02_bonus_hparam_tuning/hparam_search.py
+++ b/ch05/02_bonus_hparam_tuning/hparam_search.py
@@ -1,3 +1,8 @@
+# Copyright (c) Sebastian Raschka under Apache License 2.0 (see LICENSE.txt).
+# Source for "Build a Large Language Model From Scratch"
+# - https://www.manning.com/books/build-a-large-language-model-from-scratch
+# Code: https://github.com/rasbt/LLMs-from-scratch
+
import itertools
import math
import os
diff --git a/ch05/02_bonus_hparam_tuning/previous_chapters.py b/ch05/02_bonus_hparam_tuning/previous_chapters.py
index 33399b1..1091fa3 100644
--- a/ch05/02_bonus_hparam_tuning/previous_chapters.py
+++ b/ch05/02_bonus_hparam_tuning/previous_chapters.py
@@ -1,3 +1,8 @@
+# Copyright (c) Sebastian Raschka under Apache License 2.0 (see LICENSE.txt).
+# Source for "Build a Large Language Model From Scratch"
+# - https://www.manning.com/books/build-a-large-language-model-from-scratch
+# Code: https://github.com/rasbt/LLMs-from-scratch
+
# This file collects all the relevant code that we covered thus far
# throughout Chapters 2-4.
# This file can be run as a standalone script.
diff --git a/ch05/03_bonus_pretraining_on_gutenberg/prepare_dataset.py b/ch05/03_bonus_pretraining_on_gutenberg/prepare_dataset.py
index 1503511..7ab5df4 100644
--- a/ch05/03_bonus_pretraining_on_gutenberg/prepare_dataset.py
+++ b/ch05/03_bonus_pretraining_on_gutenberg/prepare_dataset.py
@@ -1,4 +1,8 @@
-# -*- coding: utf-8 -*-
+# Copyright (c) Sebastian Raschka under Apache License 2.0 (see LICENSE.txt).
+# Source for "Build a Large Language Model From Scratch"
+# - https://www.manning.com/books/build-a-large-language-model-from-scratch
+# Code: https://github.com/rasbt/LLMs-from-scratch
+
"""
Script that processes the Project Gutenberg files into fewer larger files.
"""
diff --git a/ch05/03_bonus_pretraining_on_gutenberg/pretraining_simple.py b/ch05/03_bonus_pretraining_on_gutenberg/pretraining_simple.py
index 14a26f7..c25bfe2 100644
--- a/ch05/03_bonus_pretraining_on_gutenberg/pretraining_simple.py
+++ b/ch05/03_bonus_pretraining_on_gutenberg/pretraining_simple.py
@@ -1,4 +1,8 @@
-# -*- coding: utf-8 -*-
+# Copyright (c) Sebastian Raschka under Apache License 2.0 (see LICENSE.txt).
+# Source for "Build a Large Language Model From Scratch"
+# - https://www.manning.com/books/build-a-large-language-model-from-scratch
+# Code: https://github.com/rasbt/LLMs-from-scratch
+
"""
Script for pretraining a small GPT-2 124M parameter model
on books from Project Gutenberg.
diff --git a/ch05/03_bonus_pretraining_on_gutenberg/previous_chapters.py b/ch05/03_bonus_pretraining_on_gutenberg/previous_chapters.py
index fbe05ee..1887c8b 100644
--- a/ch05/03_bonus_pretraining_on_gutenberg/previous_chapters.py
+++ b/ch05/03_bonus_pretraining_on_gutenberg/previous_chapters.py
@@ -1,3 +1,8 @@
+# Copyright (c) Sebastian Raschka under Apache License 2.0 (see LICENSE.txt).
+# Source for "Build a Large Language Model From Scratch"
+# - https://www.manning.com/books/build-a-large-language-model-from-scratch
+# Code: https://github.com/rasbt/LLMs-from-scratch
+
# This file collects all the relevant code that we covered thus far
# throughout Chapters 2-4.
# This file can be run as a standalone script.